📢📢📢We've released the ScanNet++ Novel View Synthesis Benchmark for iPhone data! 🥳
Test your models on RGBD video featuring real-world challenges like exposure changes & motion blur!
Download the newest iPhone NVS test split and submit your results! ⬇️
https://t.co/hLnFwifvTL
📢 SceneComp @ ICCV 2025 🏝️
🌎 Generative Scene Completion for Immersive Worlds
🛠️ Reconstruct what you know AND 🪄 Generate what you don’t!
🙌 Meet our speakers
@angelaqdai, @holynski_, @jampani_varun, @ZGojcic@taiyasaki, Peter Kontschieder
https://t.co/LvONYIK3dz
#ICCV2025
🎉Meet the #3DV2026 Keynote Speakers!
Jitendra Malik · University of California, Berkeley
Angela Dai · Technical University of Munich
Christian Rupprecht · University of Oxford
Alec Jacobson · University of Toronto
Bring your latest work and join us for the exciting keynotes!
📢 IntrinsiX: High-Quality PBR Generation using Image Priors 📢
From text input, we generate renderable PBR maps! Next to editable image generation, our predictions can be distilled into room-scale scenes using SDS for large-scale PBR texture generation.
We first train separate LoRA modules for the intrinsic properties of albedo, rough/metal, normal. Then, we introduce cross-intrinsic attention using a rerendering loss with importance-weighted light sampling to enable coherent PBR generation.
Our method outperforms text -> image -> PBR methods both in generalization and quality, since directly generating PBR maps does not suffer from the inherent ambiguity of intrinsic image decomposition. In addition, our design choice facilitates SDS-based PBR texture distillation.
🌍 https://t.co/fxu5zjAsyJ
🎥 https://t.co/A12W65ijSl
Great work by @Peter4AI, @LukasHollein
📢ExCap3D: Multilevel Captioning of Objects in 3D Scenes
@chandan__yes generates consistent object and part-level descriptions of objects in 3D scenes, and introduces a new dataset with 190k captions for 34k ScanNet++ objects.
Project: https://t.co/6tWzlYsx5F
w/ @david_roz_
Check out our #CVPR2025 papers on articulated mesh generation, 4d shape generation with dictionary neural fields, large-scale 3d scene generation and editing, and 3d editing!
Congrats to @DaoyiGao, @xinyi092298, @ABokhovkin, @QTDSMQ, @ErkocZiya for their amazing work!
Excited to bring back the 2nd ScanNet++ Novel View Synthesis and 3D Semantic Understanding Challenge @CVPR 2025!
Submit to our new benchmark, now with over 1000 high-fidelity scans of real-world scenes: https://t.co/SKCGM23hA0
Check it out: https://t.co/TvURvNYoW3
Excited to announce ScanNet++ v2!🎉
@chandan__yes and @liuyuehcheng have been working tirelessly to bring:
🔹1006 high-fidelity 3D scans
🔹+ DSLR & iPhone captures
🔹+ rich semantics
Elevating 3D scene understanding to the next level!🚀
w/ @MattNiessner
https://t.co/QayR1S8KZZ
Super happy to present our #NeurIPS paper 𝐂𝐨𝐡𝐞𝐫𝐞𝐧𝐭 𝟑𝐃 𝐒𝐜𝐞𝐧𝐞 𝐃𝐢𝐟𝐟𝐮𝐬𝐢𝐨𝐧 𝐅𝐫𝐨𝐦 𝐚 𝐒𝐢𝐧𝐠𝐥𝐞 𝐑𝐆𝐁 𝐈𝐦𝐚𝐠𝐞 in Vancouver.
Come to our poster #2804 on Wednesday 11am - 2pm in East Exhibit Hall A-C and say hi if you want to learn more about 3D Scene Diffusion!
See you tomorrow!
Project Page: https://t.co/0U3UV2DMwR
Poster: https://t.co/Idya9NJbkc
We're extremely excited to announce our $15.6M Series A led by a16z!
We're building the AI communications platform for logistics.
Go check out our new website and book a demo: https://t.co/dxG05bZCUW.
You might be surprised who calls you back ;)
📢SceneFactor: Generating & editing 3D indoor scenes from text!
@ABokhovkin presents a factored latent diffusion for controllable, large-scale scene synthesis -- decomposed into high-level semantic generation + geometric refinement
w/ @QTDSMQ, @shubhtuls
https://t.co/WGTw70cKIo
Congrats to @Normanisation who won the best paper award of @MdsiTum for his DiffRF work!
DiffRF is among the first 3D generative models that leverages diffusion, and that directly operates on a 3D radiance field representation.
(1/2)
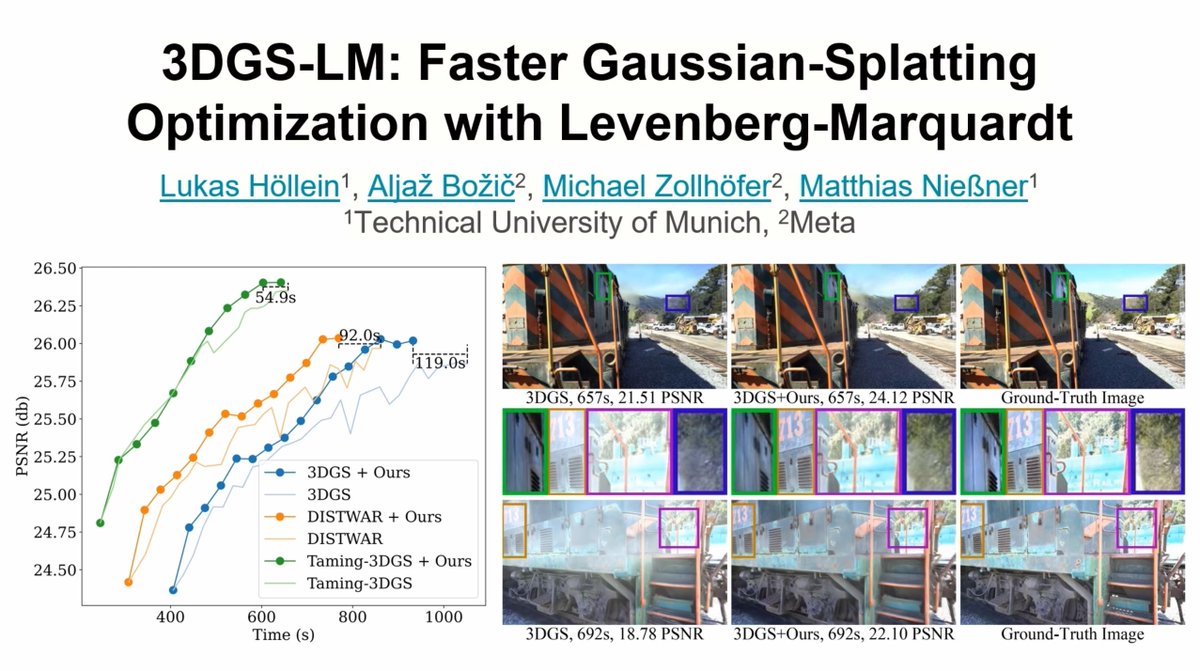
How to accelerate the reconstruction of 3D Gaussian Splatting?
3DGS-LM replaces the commonly used ADAM optimizer with a tailored Levenberg-Marquardt (LM).
=> We are 𝟑𝟎% 𝐟𝐚𝐬𝐭𝐞𝐫 𝐭𝐡𝐚𝐧 𝟑𝐃𝐆𝐒 for the same quality.
https://t.co/F4uB4DpJGt
https://t.co/Ju0Y2VxH7z
Excited to present DiffCAD coming to #SIGGRAPH2024!
@DaoyiGao introduces the first probabilistic single-view CAD retrieval & alignment.
We train only on synthetic -> generalize robustly to real images!
Check out the code: https://t.co/hBCoN0Hx3w
w/@david_roz_, @StefanLeuteneg1
Check out MultiDiff #CVPR2024!
From a single RGB image, MultiDiff enables scene-level novel view synthesis with free camera control.
https://t.co/oz7IVyV1dc
https://t.co/oxKUbXJmBQ
Great work by @normanisation@K_S_Schwarz@barbara_roessle, L Porzi, S Rota Bulò, P Kontschieder
Come and chat with us at our #CVPR2024 poster UnScene3D to learn how to understand 3D scenes without ANY human annotation. See you tomorrow 10:30 at #40 in Arch.
Work done with @angelaqdai and @orlitany.
Check out more about our paper at https://t.co/6pxkWvmfNY
Excited to present GenZI at #CVPR2024!
@craigleili introduces GenZI, the first zero-shot approach to creating realistic 3D human-scene interactions by leveraging interaction priors from large VLMs.
Code and data on our website!
https://t.co/hUhMgUoU70
https://t.co/rnn1G5HOuu