We are releasing an expanded version of Global PIQA! It now covers 141 language varieties and includes parallel and non-parallel splits. We are also releasing an updated preprint.
📢 Call for Papers:
6th Multilingual Representation Learning Workshop at EMNLP in Budapest, Hungary!
Join us and submit your works relating to multilingual NLP
Speakers to be announced, so stay tuned! 👀
More info in the CFP:
🔗 https://t.co/ZnQjqyBASQ
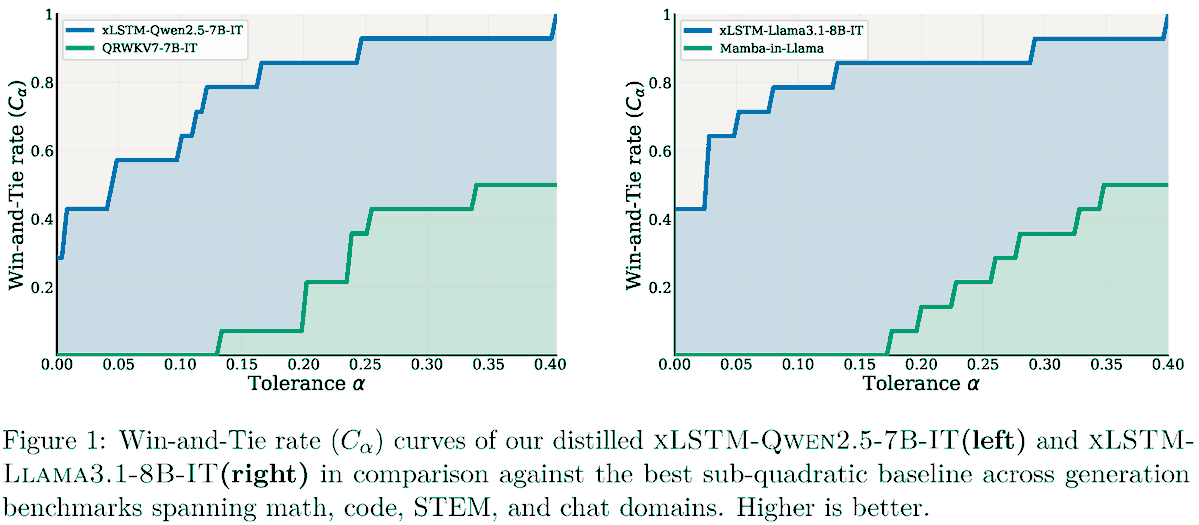
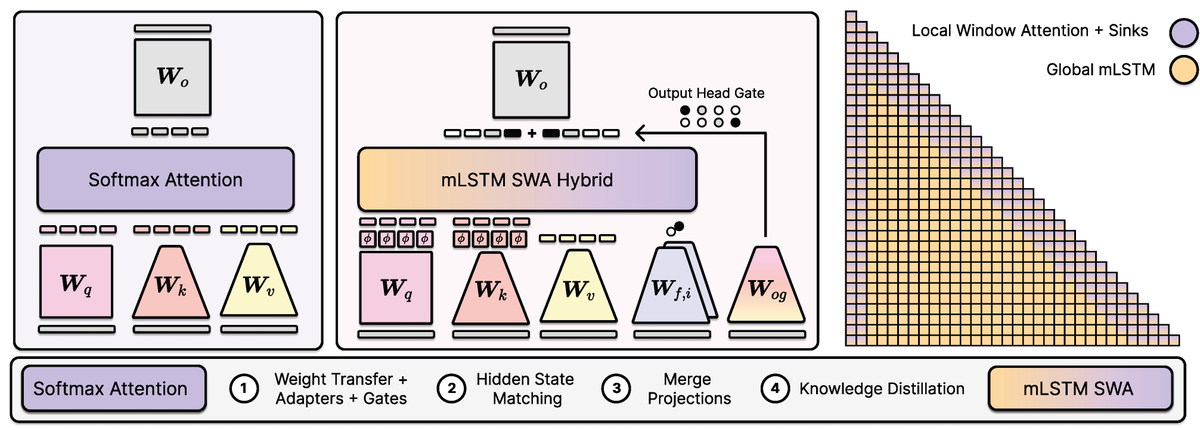
xLSTM Distillation: https://t.co/iBIJzGbzXX
Near-lossless distillation of quadratic Transformer LLMs into linear xLSTM architectures enables cost- and energy-efficient alternatives without sacrificing performance.
xLSTM variants of instruction-tuned Llama, Qwen, & Olmo models.
The call for papers is out for the 5th edition of the Workshop on Multilingual Representation Learning which will take place in Suzhou, China co-located with EMNLP 2025! See details below!
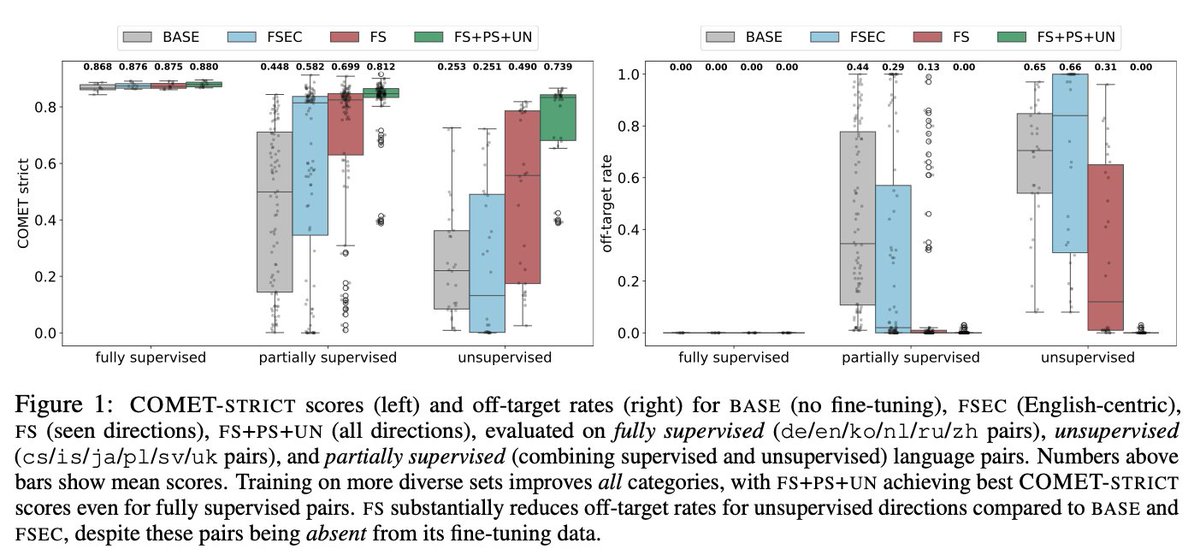
8/8📋 Key takeaway: Fine-tune with diverse language directions even when optimizing for specific translation pairs. But identify an optimal diversity threshold - too many languages can diminish performance for well-supported pairs while still benefiting less-represented ones.
🔍 How does language diversity affect LLM fine-tuning for translation?
We fine-tuned LLMs and found that MORE diversity consistently improves performance - even for language pairs that less diverse models were specifically trained to handle!
https://t.co/9M6Q7CcGTl
7/8 But there's a sweet spot! When scaling beyond 132 directions to 272 directions, we found benefits plateau or even slightly decrease for well-represented language pairs, while still helping underrepresented languages.
@JeffDean https://t.co/K5MN4xGEA9
Actually we find LLMs learn most/all translation ability from parallel sentences in the book, not the grammar.
And we can predict translation performance just from prompts' test set vocab coverage!
But we do find that grammar can help *linguistic* tasks
Our work “Can LLMs Really Learn to Translate a Low-Resource Language from One Grammar Book?” is now on arXiv! https://t.co/cRMX6fwEPg - in collaboration with @davidstap, @diwuNLP, @c_monz , and Khalil Sima'an from @illc_amsterdam and @ltl_uva 🧵
Today we release the first EuroLLM paper and models: EuroLLM-1.7B and EuroLLM-1.7B-Instruct!
The EuroLLM project will develop open-weight multilingual LLMs that understand and generate text in all official EU languages.
Stay tuned for the bigger and stronger EuroLLMs (9B, 22B)!
@EvaHasler@unattributed@c_monz@ketran Our IdiomsInCtx-MT dataset, consisting of idiomatic expressions in context and their human-written translations, is now available on Huggingface: https://t.co/RG7ozauUEo