New EIP!
pERC20 - Privacy-Native Fungible Tokens
🔗 https://t.co/DBDudAF6I7
Highlights:
- Not ERC-20 compatible by design: pERC20 removes public balance/allowance concepts (no balanceOf/approve/allowance/transferFrom) and replaces transfers with a ZK note-based interface (transfer(PrivacyCall)), because public balances would defeat the privacy goal.
- Privacy-native from issuance: tokens are always represented as encrypted ZK-UTXO notes (Orchard-style actions with Groth16 proofs); there is no “public-to-private shielding” step—transfers are note→note and amounts/participants are private by default.
- Public, on-chain verifiable supply: totalSupply remains public and is updated only through controlled mint(amount, ...) and burn(amount, ...); transfers must conserve value (valueBalance == 0), enabling “no invisible inflation” while keeping balances private.
- Built-in compliance via frozen-root binding: every action commits to the contract’s cmxFrozenRoot, and the ZK circuit must prove the spent note commitment is NOT in the blacklist SMT. Admin can update the root (setFrozenRoot) to freeze/unfreeze specific notes without revealing normal users’ balances.
- Security-critical invariants and checks: implementations must prevent double-spends with nullifiers and must range-check each public field (< Fr) to avoid nf + Fr-style bypasses; the core bundle execution must not be publicly callable to prevent unaccounted supply changes; signature points must be curve/field validated and replay protection must bind chainId + contract + note data.
ELI5:
This EIP proposes a new kind of token standard for Ethereum where people’s token amounts and who they pay are hidden by default. Instead of keeping a public “balance” per account like ERC-20, the token exists as many encrypted “notes” (like digital cash bills) that can be spent with zero-knowledge proofs. Everyone can still see the total number of tokens that exist (totalSupply) so the issuer can’t secretly create extra tokens. It also adds an optional-but-built-in “freeze list” mechanism: the token contract keeps a public fingerprint (root) of a blacklist, and the zero-knowledge proof must show you are not spending a frozen note.
1/
we just shipped the redesigned hourly DCA in ETH on @base 🔥
no more guessing the perfect day
no charts. no leverage. no timing the market
just set it — and the protocol buys wETH for you 24 times a day
90-second walkthrough with our co-founder @s19kravtsov of the new experience ↓
X Money going into recurring payments = every fintech will follow
The question is build vs. plug in
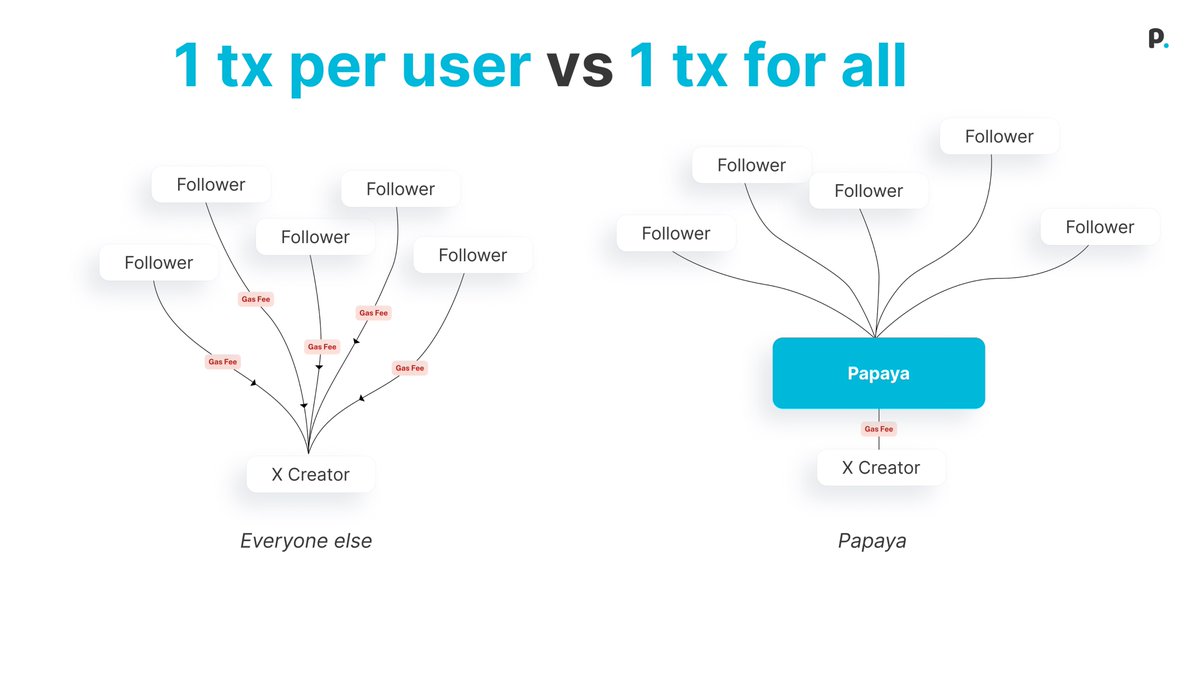
@papaya_fi already built the open infra layer — O(1) settlement, non-custodial, multi-chain
This is the Stripe moment for onchain subscriptions
X Money wants recurring payments. We built the rails.
Papaya is recurring payment infrastructure for the stablecoin economy:
→ Unlimited subscriptions settled in 1 tx
→ < $0.01 gas regardless of user count
→ Non-custodial, audited, live since 2024
Any platform can plug in. The infra is ready.
A historic milestone for the EVM
Real, native Account Abstraction on Ethereum without the clunky bundlers.
EIP-8141 elegantly solves the remaining friction through transaction frames: no more third-party workarounds for batching or token gas payments
Now, account abstraction.
We have been talking about account abstraction ever since early 2016, see the original EIP-86: https://t.co/E4xJymAxiH
Now, we finally have EIP-8141 ( https://t.co/YD9nIpsxcC ), an omnibus that wraps up and solves every remaining problem that AA was intended to address (plus more). Let's talk again about what it does.
The concept, "Frame Transactions", is about as simple as you can get while still being highly general purpose. A transaction is N calls, which can read each other's calldata, and which have the ability to authorize a sender and authorize a gas payer. At the protocol layer, *that's it*.
Now, let's see how to use it.
First, a "normal transaction from a normal account" (eg. a multisig, or an account with changeable keys, or with a quantum-resistant signature scheme). This would have two frames:
* Validation (check the signature, and return using the ACCEPT opcode with flags set to signal approval of sender and of gas payment)
* Execution
You could have multiple execution frames, atomic operations (eg. approve then spend) become trivial now.
If the account does not exist yet, then you prepend another frame, "Deployment", which calls a proxy to create the contract (EIP-7997 https://t.co/sIQrtJDXLt is good for this, as it would also let the contract address reliably be consistent across chains).
Now, suppose you want to pay gas in RAI. You use a paymaster contract, which is a special-purpose onchain DEX that provides the ETH in real time. The tx frames are:
* Deployment [if needed]
* Validation (ACCEPT approves sender only, not gas payment)
* Paymaster validation (paymaster checks that the immediate next op sends enough RAI to the paymaster and that the final op exists)
* Send RAI to the paymaster
* Execution [can be multiple]
* Paymaster refunds unused RAI, and converts to ETH
Basically the same thing that is done in existing sponsored transactions mechanisms, but with no intermediaries required (!!!!). Intermediary minimization is a core principle of non-ugly cypherpunk ethereum: maximize what you can do even if all the world's infrastructure except the ethereum chain itself goes down.
Now, privacy protocols. Two strategies here. First, we can have a paymaster contract, which checks for a valid ZK-SNARK and pays for gas if it sees one. Second, we could add 2D nonces (see https://t.co/1cRegaXpHM ), which allow an individual account to function as a privacy protocol, and receive txs in parallel from many users.
Basically, the mechanism is extremely flexible, and solves for all the use cases. But is it safe? At the onchain level, yes, obviously so: a tx is only valid to include if it contains a validation frame that returns ACCEPT with the flag to pay gas. The more challenging question is at the mempool level.
If a tx contains a first frame which calls into 10000 accounts and rejects if any of them have different values, this cannot be broadcasted safely. But all of the examples above can. There is a similar notion here to "standard transactions" in bitcoin, where the chain itself only enforces a very limited set of rules, but there are more rules at the mempool layer.
There are specific rulesets (eg. "validation frame must come before execution frames, and cannot call out to outside contracts") that are known to be safe, but are limited. For paymasters, there has been deep thought about a staking mechanism to limit DoS attacks in a very general-purpose way. Realistically, when 8141 is rolled out, the mempool rules will be very conservative, and there will be a second optional more aggressive mempool. The former will expand over time.
For privacy protocol users, this means that we can completely remove "public broadcasters" that are the source of massive UX pain in railgun/PP/TC, and replace them with a general-purpose public mempool.
For quantum-resistant signatures, we also have to solve one more problem: efficiency. Here's are posts about the ideas we have for that: https://t.co/xzG3Jp7Yky https://t.co/WikL7gJ5qg
AA is also highly complementary with FOCIL: FOCIL ensures rapid inclusion guarantees for transactions, and AA ensures that all of the more complex operations people want to make actually can be made directly as first-class transactions.
Another interesting topic is EOA compatibility in 8141. This is being discussed, in principle it is possible, so all accounts incl existing ones can be put into the same framework and gain the ability to do batch operations, transaction sponsorship, etc, all as first-class transactions that fully benefit from FOCIL.
Finally, after over a decade of research and refinement of these techniques, this all looks possible to make happen within a year (Hegota fork).
https://t.co/p7XOgId5NN
My first blogpost is out: https://t.co/GA6V36chR8
Like many of you, my feed has been dominated recently by Anthropic's Optimization team take-home.
TL;DR: They retired this "notoriously difficult" exam because Claude Opus 4.5 effectively solved it. So, they released the task, and everyone started the grind.
Yes, AI beat human candidates here, but AI-generated solutions aren't easy to follow if you aren't familiar with the domain. And they carry 0 educational value.
I didn't just want to see the solution; I wanted to understand the mechanics under the hood.
So I spent the weekend digging into the task. I started with a naive Python baseline that took 147k cycles. After three rounds of specific optimizations, I got it down to ~2,200 cycles.
That’s a 65x speedup—and likely would have passed the hiring bar half a year ago.
I’ve just published a full breakdown of the solution. I explain everything in detail and depth, but I kept it accessible. Hope you'll love the visuals!
Enjoy!
If we have AGI, does that eliminate all developer jobs?
My intuition tells me no, there will be more demand than ever to build software, but that the role is definitely changing and you need to adapt.
First off, no one agrees on what AGI is. The goal posts move.
If you've worked at a boomer company in the middle-of-nowhere US, writing software for a company that doesn't understand software, then you understand how early we still are.
Y'all... it's brutal out there. These companies are working on their digital transformations to get off their COBOL systems, just trying to keep the lights on. They are not attracting the top talent like SF or NY. They still view software engineering as "IT".
If you could equip every engineer at those companies with unlimited AI spend, I don't think you would see a 100x return overnight. Because the issue here isn't generating code. These companies have to update the process of *how they build software* for the new world.
And building software is a lot more than just writing code. You have to figure out the correct thing to build, which usually means getting it wrong and iterating a bunch, talking to customers, working with different parts of a company. You need to have good taste!
I'm just as impressed as everyone else with the latest AI models, coding agents, and products. It's a wild time and it will definitely mean that a "software engineer" has to change. Gone are the days of punching every key by hand. But these changes take time, and they're not evenly distributed across the economy.
This is part of the reason I joined Cursor. I don't really know what AGI is, nor are we trying to "feel the AGI" and build god in a box. We just want to make really good tools for developers and software engineers.
By some definitions, what we have today is already "AGI". If you would have shown me this a decade ago, I would have lost my mind. So it's not really the right benchmark to measure progress against.
If AGI is actually "capable of doing literally anything a human can do" then I think we have a long way to go. I don't know what this means exactly: is this also robots? Neuralink?
When I see one of the 100-year-old companies shipping amazing software products with a handful of engineers on staff, then I will be wrong.
But I just don't see that happening for a very long time. Most of the commercial software I use for banking, flights, groceries, etc... is not good. Until then, I expect the demand for great engineers to increase, especially as more people try to figure out how to wield these new AI tools.
THE FUTURE OF AI APPLICATIONS
Jensen Huang: “Another breakthrough happened… the first time I realized Perplexity was using multiple models at the same time, I thought it was completely genius.”
The future isn’t one great model…
It’s orchestrating multiple great models at every step of the reasoning chain.
Multi-model. Multimodal. Multi-cloud.
Your AI has amnesia. It’s a feature, not a bug. Until now
We’ve hit a wall with LLMs
You talk, they answer, you close the tab -> poof
All that context is gone
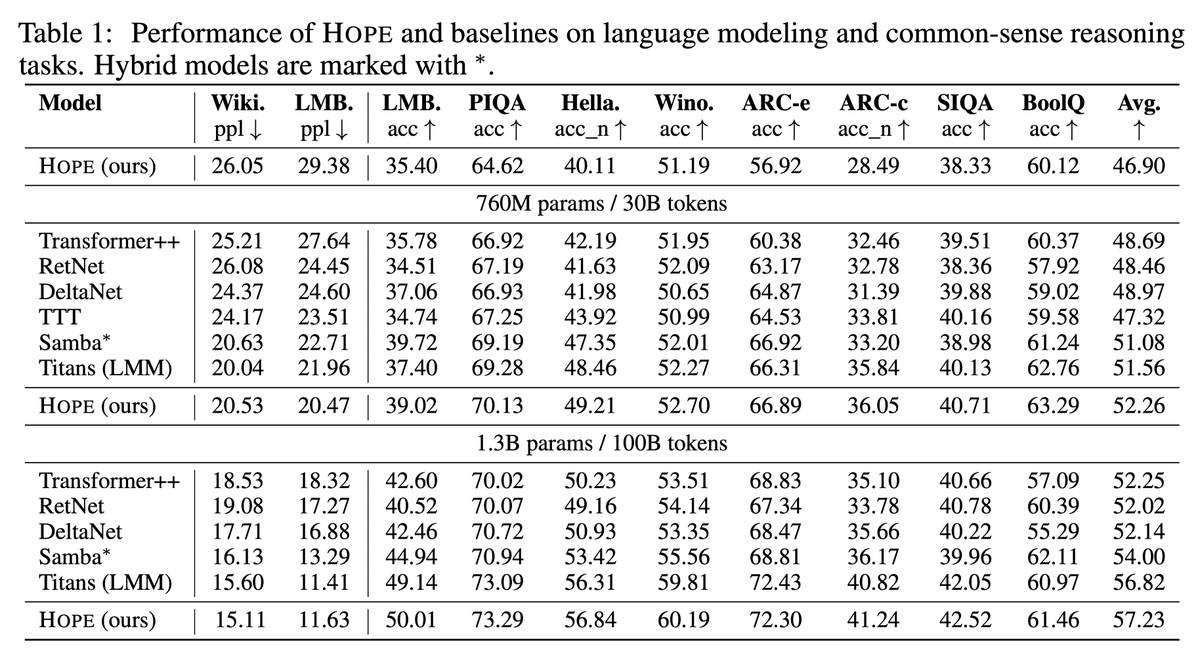
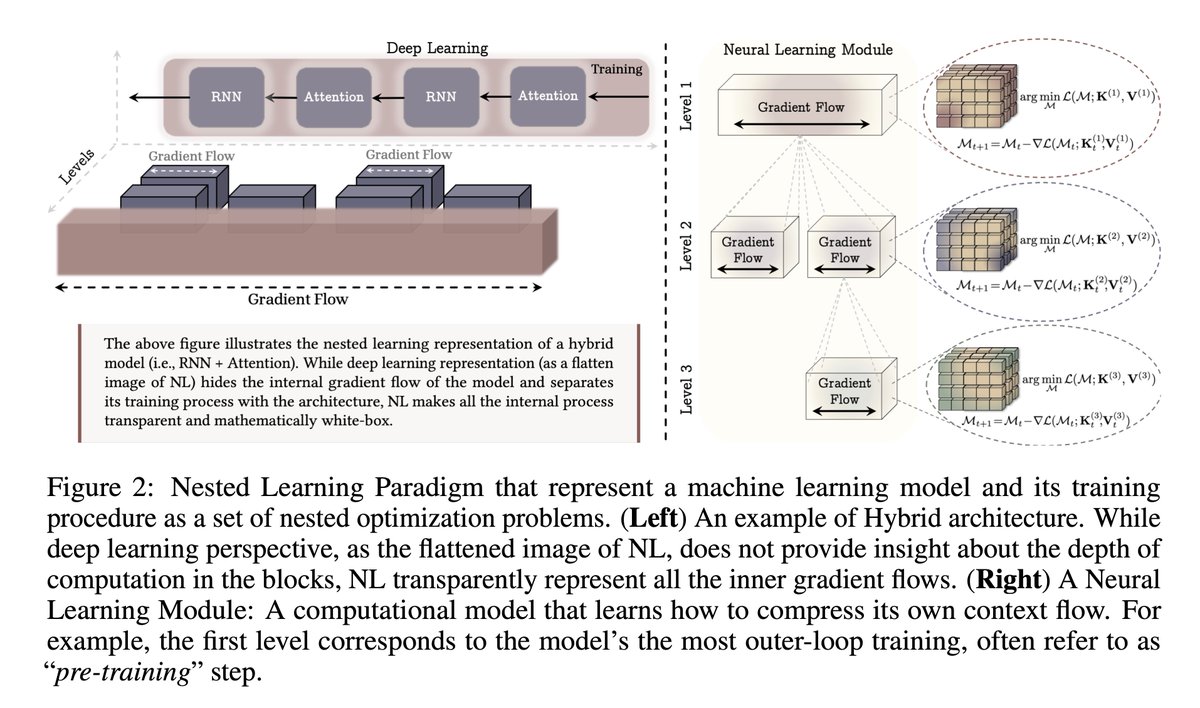
Google Research just proposed a fix called HOPE
The idea is wild:
They realized "Deep Learning" layers are actually an illusion
Real learning happens in loops, not stacks
Think of it like brain waves:
- Fast waves handle the current convo.
- Slow waves lock it into long-term memory
HOPE uses "Nested Learning" to update itself in real-time
It doesn't just learn from data
It learns how to learn better while it talks to you
Static models are dead
Living, adapting models are next
Would you trust an AI that remembers everything you’ve ever said?
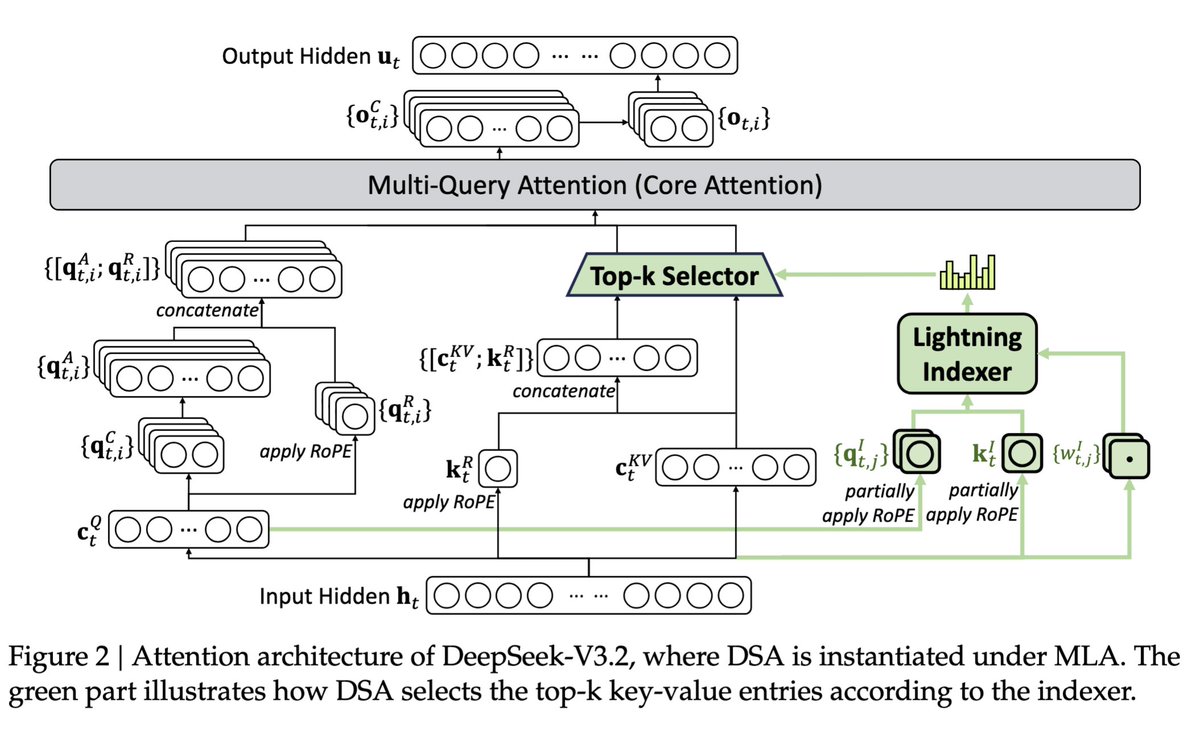
DeepSeek just dropped V3.2 and it’s massive
They released a "Speciale" model that claims to beat GPT-5 and rival Gemini 3.0 Pro
But here is the best part:
It uses a new "Sparse Attention" mechanism
📉 50% lower API cost
🚀 2x faster for long context
🥇 Gold medal performance in Math/Coding (IMO/IOI)
Open source is moving faster than closed models can release
Introducing Gemini 3 ✨
It’s the best model in the world for multimodal understanding, and our most powerful agentic + vibe coding model yet. Gemini 3 can bring any idea to life, quickly grasping context and intent so you can get what you need with less prompting.
Find Gemini 3 Pro rolling out today in the @Geminiapp and AI Mode in Search. For developers, build with it now in @GoogleAIStudio and Vertex AI.
Excited for you to try it!































![chetaslua's tweet photo. 🚨DeepSeek V4 is expected mid-Feb 2026
Two version will be there according WeChat post:
> v4 [long coding session]
> v4-lite [faster response] https://t.co/ZbRk9k2GUb](https://pbs.twimg.com/media/G-iN0W7bQAA-nL7.jpg)






















