What is database synchronization?
Updated our overview with clearer examples and diagrams for insert, update, delete, and mixed sync modes.
https://t.co/PyCez4SutI
Before you migrate or sync data, you usually need to inspect it first.
Tables, columns, DDL, row previews, files, S3 paths, quick SQL checks.
That inspection layer is what Data Explorer in DBConvert Streams is for.
https://t.co/B7knEorCqS
DBConvert Streams 2.3.0: SQL Console results are now paged.
Large SELECT / WITH queries load into the grid page by page instead of dumping everything at once.
Useful for database browsing and federated SQL across DBs/files/S3.
https://t.co/1MpypK3vrY
Embedded DuckDB in a Go API is simple until native execution shares the API failure domain.
A CGO SIGSEGV reminded us why interactive query execution needs a supervised worker process.
Related discussion collected in r/DBConvert:
https://t.co/B046ENK8d2
#golang#DuckDB
DuckDB made cross-source SQL feel simple.
Once the query needs credentials, schema checks, exports, and repeat runs, the hard part often moves outside the engine.
Wrote about the gap between DuckDB as a query engine and the workflow around it:
https://t.co/l20mtRikIp
@duckdb
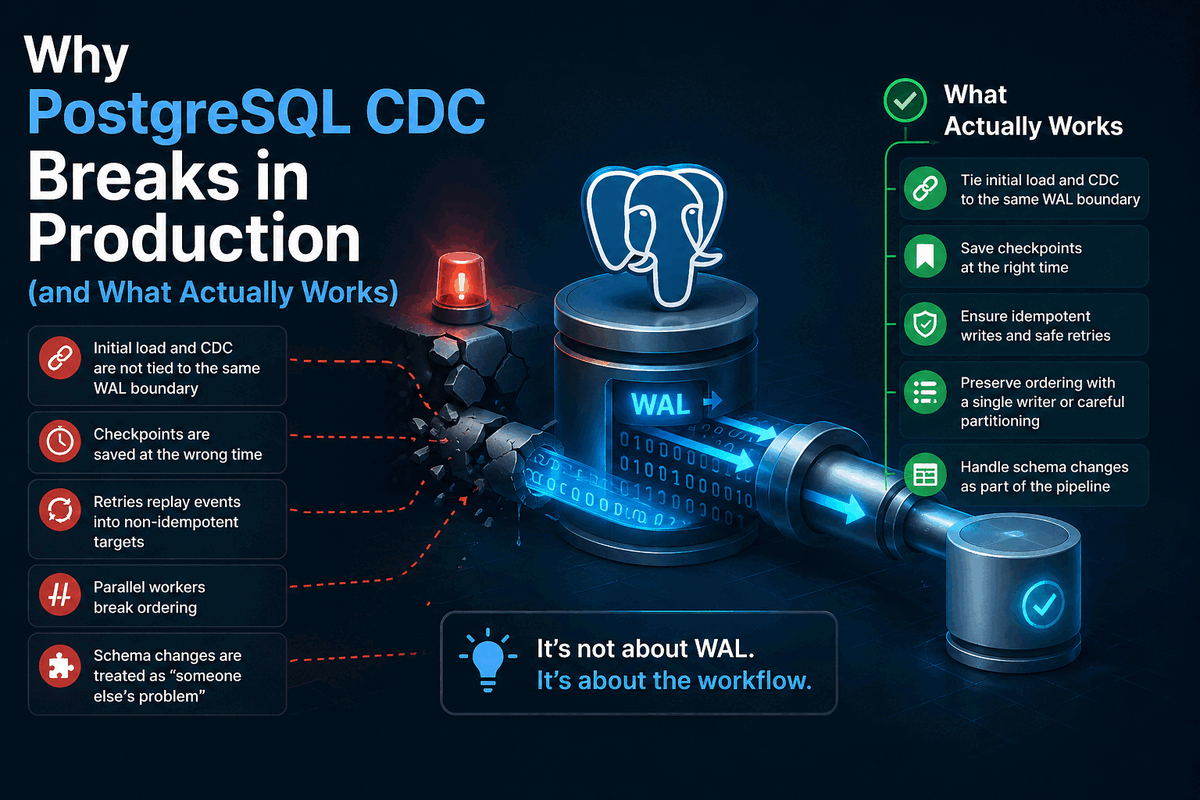
PostgreSQL CDC usually breaks after WAL, not because of WAL.
The ugly parts are the workflow around it:
- snapshot handoff
- checkpoint timing
- retries
- ordering
- schema changes
- restart recovery
I republished the full write-up on Medium.
Link below.
@_linkofhyrule Building DBConvert Streams.
It’s a database workspace for people who need to inspect data, query across sources, migrate databases, and keep them in sync with CDC.
Basically trying to reduce the “SQL client + scripts + pipeline tool + sync tool” mess into one workflow.
@FAHADSH97656634@apurva1618 Agree with this.
Kafka still makes sense when CDC is part of a larger event platform.
But for Pg CDC → one operational target, the stack often feels oversized. The hard parts are usually snapshot handoff, checkpoints, retries, and target idempotency, not running a broker.
@r0ktech PostgreSQL for 90% of projects.
SQLite for small/local stuff.
Mongo only when the data is genuinely document-shaped, not when I’m trying to avoid thinking about schema.
@BacLeodiv Postgres.
Mongo is fine until the app quietly becomes relational anyway.
Supabase/Neon are good starts too, but that’s still mostly a Postgres decision with better DX around it.
Cross-source joins, powered by @duckdb:
SELECT https://t.co/fcPLfK5Hpg, COUNT(https://t.co/sRkaGKgLe3)
FROM pg.users u
JOIN read_parquet('s3://logs/*.parquet') e
ON e.user_id = https://t.co/fcPLfK5Hpg
GROUP BY 1;