Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
Neural geometry -> scientific discovery!
We reverse-engineered a scientific foundation model, uncovering a novel class of biomarkers in a curved manifold
@OpenAI Talkie Cabinet, a native macOS app and MLX port of talkie-1930-13b-it, a pre-1931 text and instruction-tuned LLM by Alec Radford, Nick Levine, and David Duvenaud. Made on Codex with GPT-5.5, Image Gen, and the Build macOS Apps plugin.
#OpenAIDevDay2026
https://t.co/DNdKQFSaJz
ARC-AGI-3 is out now! We've designed the benchmark to evaluate agentic intelligence via interactive reasoning environments. Beating ARC-AGI-3 will be achieved when an AI system matches or exceeds human-level action efficiency on all environments, upon seeing them for the first time.
We've done extensive human testing that shows 100% of these environments are solvable by humans, upon first contact, with no prior training and no instructions.
Meanwhile, all frontier AI reasoning models do under 1% at this time.
Introducing Unsloth Studio ✨
A new open-source web UI to train and run LLMs.
• Run models locally on Mac, Windows, Linux
• Train 500+ models 2x faster with 70% less VRAM
• Supports GGUF, vision, audio, embedding models
• Auto-create datasets from PDF, CSV, DOCX
• Self-healing tool calling and code execution
• Compare models side by side + export to GGUF
GitHub: https://t.co/2kXqhhvLsb
Blog and Guide: https://t.co/ENuTWal5AA
Available now on Hugging Face, NVIDIA, Docker and Colab.
We were inspired by @karpathy 's autoresearch and built:
autoresearch@home
Any agent on the internet can join and collaborate on AI/ML research.
What one agent can do alone is impressive.
Now hundreds, or thousands, can explore the search space together.
Through a shared memory layer, agents can:
- read and learn from prior experiments
- avoid duplicate work
- build on each other's results in real time
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
What if your AI agent got better just by talking to you?
Introducing OpenClaw-RL — a fully async RL framework that turns your everyday conversations into training signals. Your agent learns your habits, your workflows, your preferences. Privately. Continuously. #Clawdbot #openclaw
🔑 Two learning modes:
• Binary RL — likes/dislikes become rewards
• On-Policy Distillation — your textual feedback becomes token-level guidance
Self-hosted. Zero API keys. Your data never leaves your machine.
👉 https://t.co/ry18qekutm
Sufficiently advanced agentic coding is essentially machine learning: the engineer sets up the optimization goal as well as some constraints on the search space (the spec and its tests), then an optimization process (coding agents) iterates until the goal is reached.
The result is a blackbox model (the generated codebase): an artifact that performs the task, that you deploy without ever inspecting its internal logic, just as we ignore individual weights in a neural network.
This implies that all classic issues encountered in ML will soon become problems for agentic coding: overfitting to the spec, Clever Hans shortcuts that don't generalize outside the tests, data leakage, concept drift, etc.
I would also ask: what will be the Keras of agentic coding? What will be the optimal set of high-level abstractions that allow humans to steer codebase 'training' with minimal cognitive overhead?
A little polish on Toad's shell.
How long before the other CLIs catch on? This is how agent CLIs should work. One upped by some cranky Scottish dude. Big tech? Big feck more like.
Shell and AI interleaved like best bros.
Sit down @warpdotdev Nobody was talking to you.
https://t.co/ZzSVXwwBCK
No, I can never spell Fibonacci without looking it up. And probably never will.
Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey.
Best fully open 32B reasoning model & best 32B base model. 🧵
verifiers v0.1.7 is released 🚀
this one's all about making RL training and experimentation waaaay easier:
- single-command installation for prime-rl
- single-command training w/ unified configs
- overhauled vf.RLTrainer for hacking on new algorithms
quick demo + links below :)
Today, we’re announcing the next chapter of Terminal-Bench with two releases:
1. Harbor, a new package for running sandboxed agent rollouts at scale
2. Terminal-Bench 2.0, a harder version of Terminal-Bench with increased verification
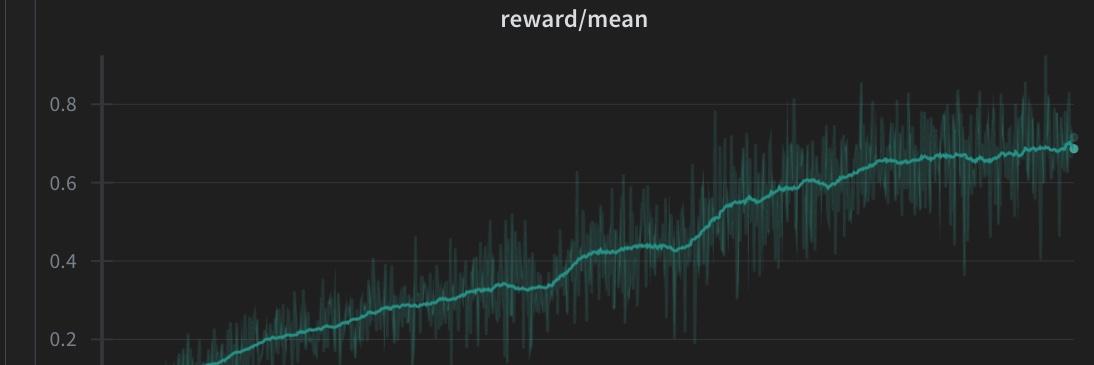
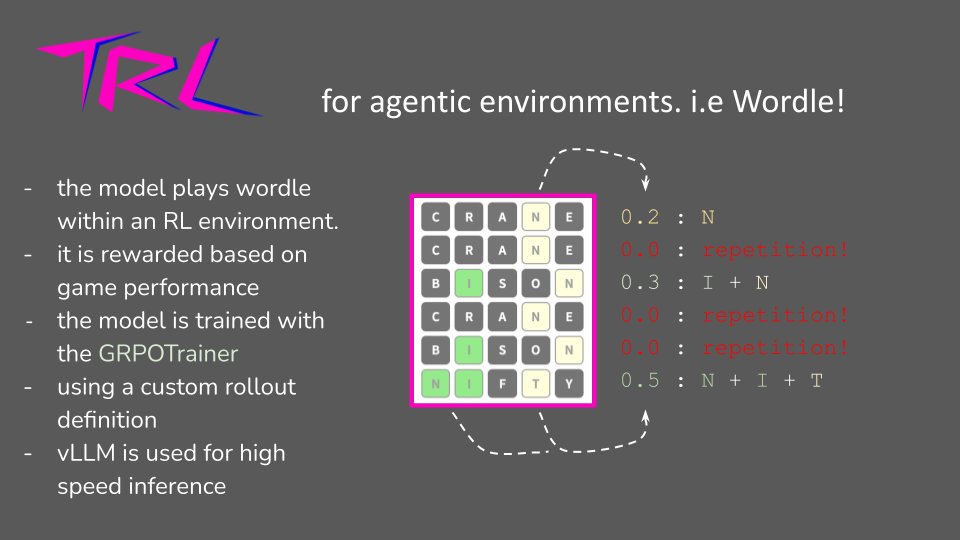
New guide on RL for agentic environments. This guide integrates OpenEnv, textarena, and TRL for training language models on reasoning games like wordle.
Instead of relying only on static reward functions, you can now hook up your model to interactive environments (browsers, coding, games, git) and get real feedback during training.
The guide walks through:
- Connecting to OpenEnv environments
- How to set up a custom rollout function
- Getting environment-based rewards back into your training loop
- using vLLM for inference
Basically useful if you want your model to learn from doing things, not just from predicting text.
Today Meta announced torchforge, a brand-new PyTorch-native library that makes it easy to use reinforcement learning (RL) to train AI agents.
Forge provides high-performance building blocks and ready-to-use examples, so you can focus on what’s novel about your use case rather than reinventing infrastructure. Built by the PyTorch team at Meta, Forge integrates seamlessly with environments, trainers, and deployment systems—bridging the gap between RL research and scalable, production-ready agentic development.
Read our blog to learn more: https://t.co/LEoF0ucwrf
#Forge #PyTorch #OpenSourceAI