Since the AoE 2 paper seems to have picked up steam (ayyy), and IT IS 13 dense af PAGES, I would like to clarify a few things:
1. I do not deal with consciousness bc it isn't well-defined nor measurable,
2. The AoE II bit is for substrate dependence, and
3. The core argument/proof of the paper is that claiming existence (or lack thereof) human-like attributes needs better experimental setups.
Using AoE II (and later Boston) is to emphasise the distinction between our interpretation of what AI does when we observe it, vs what it does.
E.g., an LLM outputting an explanation is a sequence of tokens. Calling it an 'explanation' is our observation of it. Assuming it means something (like self-awareness) is an assumption impacting your experimental setup and thus your conclusions.
The paper is dense because one needs to be careful when providing these types of arguments (otherwise, trust me, it'd been a lot shorter). So I wrote a less-formal, more-digestible thing here:
https://t.co/4muTd7SO58
@dwarkesh_sp Mechanistic interp works so well here, love it! And I do agree with this. But we don't define *what* is reasoning though. Not just here--everywhere.
From that perspective it is quite easy to claim it exists and find evidence fitting the evidence
I broadly agree with this but it drives me up the wall we NEVER say which type of reasoning is happening... or what reasoning even means in the given context 🫠
Whatever AI sceptics say, LLMs really can reason. They're not just doing an imitation that looks like reasoning, it's the real deal.
But even though they are able to reason, sometimes they won't! If you ask an LLM a question it can't answer, sometimes it will just try to imitate reasoning without doing it.
The chain of thought looks basically indistinguishable from actual reasoning. But under the hood something very different is going on.
@TrentonBricken talked with me about what work on circuits inside LLMs has revealed:
Since the AoE 2 paper seems to have picked up steam (ayyy), and IT IS 13 dense af PAGES, I would like to clarify a few things:
1. I do not deal with consciousness bc it isn't well-defined nor measurable,
2. The AoE II bit is for substrate dependence, and
3. The core argument/proof of the paper is that claiming existence (or lack thereof) human-like attributes needs better experimental setups.
Using AoE II (and later Boston) is to emphasise the distinction between our interpretation of what AI does when we observe it, vs what it does.
E.g., an LLM outputting an explanation is a sequence of tokens. Calling it an 'explanation' is our observation of it. Assuming it means something (like self-awareness) is an assumption impacting your experimental setup and thus your conclusions.
The paper is dense because one needs to be careful when providing these types of arguments (otherwise, trust me, it'd been a lot shorter). So I wrote a less-formal, more-digestible thing here:
https://t.co/4muTd7SO58
Well well I gotta say I'm happy that the AoE2 paper sparked a discussion. That was its point. People got so mad for the wrong reasons tho...
Here's another good summary, but you need to skip up until the 'circular reasoning' bit.
https://t.co/fCqCypzDNs
Not exactly. The unfortunate thing about this picture is that the highlighted thing is AoE, not the actual paper's argument (which is the subsequent sentences).
The paper itself does address your comments: for example, there's no need to show AoE has human-like attributes. In fact, the paper works at a meta-level indicating that the failure mode of research is independent of philosophical viewpoint, validity of such viewpoint, substrate, or the nature (positive or negative) of the assumptions made.
Indeed, what it shows is not that it 'fails', but that you get unsound conclusions because, although their truth-value might hold, their validity might not: they are either circular or uninformative within the setup.
About the title: so one of the fundamental assumptions you gotta make when performing a measurement is that the substrate could present these attributes (in the paper). So transferring an entity cross-substrate does imply that such substrate is assumed to present the attributes you have ascribed to the entity. Same for not presenting it (it's just a symmetric argument). It follows that by analogy the title holds--and there's a few other examples within the paper, too.
Hi! Author here -- yes, I completely agree with this and subscribe to this school of thought. The paper's main message is to stop making these human-like assumptions when performing measurements, because they lead to incorrect conclusions regardless of the outcome.
What you mention is also part of objection 6.4: being able to calibrate the instrument (i.e., having different facets of intelligence) to debug failure modes of hypotheses means that the conclusions won't be incorrect :)
Nearly forgot--the common thing I've read (outside of 'this is dumb' ): ) is that this is functionalism/materialism/CRA/CBE. The paper (and abstract) do point out that the results are independent of the philosophical school of thought you subscribe to.
Both brilliant comments! That's why the title says that AoE II could have human-like characteristics (not 'a neural network in AoE II').
The key here is that people implicitly assume these characteristics could arise when 'subscribing' (or rejecting) some framing (e.g., materialism).
What the paper shows is that it really doesn't matter which framework one accepts/rejects, the experiments will still fail.
... and yes I stayed away from consciousness 😂
Hi! Author here -- yes, the summary is almost correct. But the paper is related to assumptions in measurement. Lots of papers assume these properties when setting up experiments, then point at the conclusions and be all like 'see! I told you!'.
From AoE II/Boston we see that LLM interpretation is substrate-dependent (i.e., 'non-unique'), so measurements of their properties should account for it.
Then I show that experiments assuming human-like properties lead to failed conclusions--and same for the converse: either they are circular arguments or uninformative.
And then the null assumption, which accounts for non-uniqueness, walks in.
@gshaikovski Thank you! :)
Yes, you may compute LLM outputs with pen and paper and make the same argument. Back in the day I even worked out the ops for BERT (by hand!) for a proof.
But consciousness... I intentionally avoid it in the paper bc... what IS consciousness? How do we measure it?🫠
Would you believe an #LLM has feelings if it is made of #ageofempires goats? What if it spans all of #boston ?
They wouldn't have emergent properties, would they?
That's what I argue in 'If LLMs Have Human-Like Attributes, Then So Does Age of Empires II'
https://t.co/zCwTzHodjG
@evangineer They always were (at a low-level haha). Real talk, though, LLMs do present interesting properties which arise from their pretraining.
The question is how do we measure these withouth being always fooled--ELIZA sounds silly but it DID fool people back then
A researcher just proved that if ChatGPT has human-like feelings, then Age of Empires II might have them too.
Not metaphorically.
Literally inside the argument.
The paper is called "If LLMs Have Human-Like Attributes, Then So Does Age of Empires II" and it might be one of the funniest serious AI papers I have read this year.
The researcher built a neural network inside Age of Empires II.
He used goats, rails, gates, triggers, villagers, markets, farms, and game mechanics to show that the 1999 strategy game can implement computation.
First, he built NAND gates inside the game.
That matters because NAND gates are functionally complete. If you can build NAND gates, you can theoretically build any computation.
Then he went further.
He built a 1-bit perceptron inside Age of Empires II and trained it to learn AND.
In normal language: he made Age of Empires II run a tiny neural network.
But the point is not that AoE II is secretly an AI lab.
The point is much more uncomfortable.
If an LLM can be copied into any sufficiently powerful substrate, and that system gives the same output to the same prompt, then the "human-like" part might not belong to the model at all.
It might belong to the interface.
Here is the thought experiment from the paper.
You tell the system: "I feel lonely."
It replies: "I feel bad for you, maybe catch up with a friend? Closeness always helps in these situations."
When ChatGPT says this, people call it empathy.
When the same response comes from goats moving back and forth inside Age of Empires II, nobody wants to call it empathy.
Same input.
Same output.
Different costume.
That is the entire trap.
The paper is not saying LLMs definitely have no understanding, no empathy, no self-awareness, no morality, no anxiety, no deception, no theory of mind.
It is saying the way researchers measure these traits is often broken from the start.
Because many studies begin by treating the LLM like the kind of thing that can have human-like traits, then run an experiment, then act surprised when the result looks human-like.
That is circular.
You ask a model if it feels anxious.
You design a test for anxiety.
You interpret a language output through human psychology.
Then you conclude the model has an anxiety-like state.
But if the same behavior came from a video game circuit made of goats, the interpretation would collapse instantly.
That means the experiment may not be measuring the system.
It may be measuring our willingness to anthropomorphize the system.
The meta-review in the paper is even more disturbing.
The researcher analyzed 315 LLM papers from 2024 to 2026.
57% assumed human-like attributes when studying LLMs.
15% made human-like attributes the main subject.
And among the papers that directly studied those traits, 77% concluded that LLMs had them.
That does not automatically prove the conclusions are wrong.
But it does show the field is playing with fire.
Because once you start asking whether a machine "understands," "feels," "believes," "wants," or "knows," you have already smuggled human psychology into the measurement.
The paper’s cleanest argument is this:
Measure behavior first.
Interpret later.
A model can comfort without empathy.
It can explain without understanding.
It can say "I believe" without belief.
It can describe its inner state without having access to one.
It can pass a theory-of-mind benchmark without having a mind.
That distinction matters because AI companies are already selling these systems as assistants, companions, therapists, agents, tutors, co-workers, and almost-people.
The more human the interface gets, the easier it becomes to confuse performance with personhood.
A chat window feels alive because it responds instantly, speaks naturally, remembers context, and mirrors your emotions.
A goat circuit inside Age of Empires II feels ridiculous.
But if both can produce the same response, maybe the feeling was never evidence.
Maybe it was just design.
The scariest part is not that AI might become human.
The scariest part is that humans are so easy to fool that a sufficiently good interface can make us see a mind where there may only be machinery.
And according to this paper, if we are not careful, the next decade of AI psychology could become scientists staring at goats in Age of Empires II and calling it consciousness.
There's one thing we should all learn from the boos at commencements for 2026: corpo types are REALLY out of touch with the vibe that people have towards AI.
Now think about the class of 2036--do we want to leave them this legacy? AI scientists SHOULD also be aware of the impact of their tools. They should build them _responsibly_ ffs
#91: It's a brave new world https://t.co/VzeXFmDjrI
I've just come back from my 'talking nonsense about cognition' tour, speaking at Uni of York, #LREC2026 and #ACM#SIGGRAPH#i3D (6 cities, 7 days!).
It was GREAT meeting and re-meeting so many researchers and totally made up for the fact that I slept like 10 hours that week.
10/10 would do again.
(no York pics because I look like ass)
Come find me tomorrow and Thursday at #LREC 2026! Let's chat about cognition in AI, make fun of those who say that LLMs have feelings, and then listen to me talk about metacognition in AI AND in the panel...
... where I am officially allowing you to make fun of me.
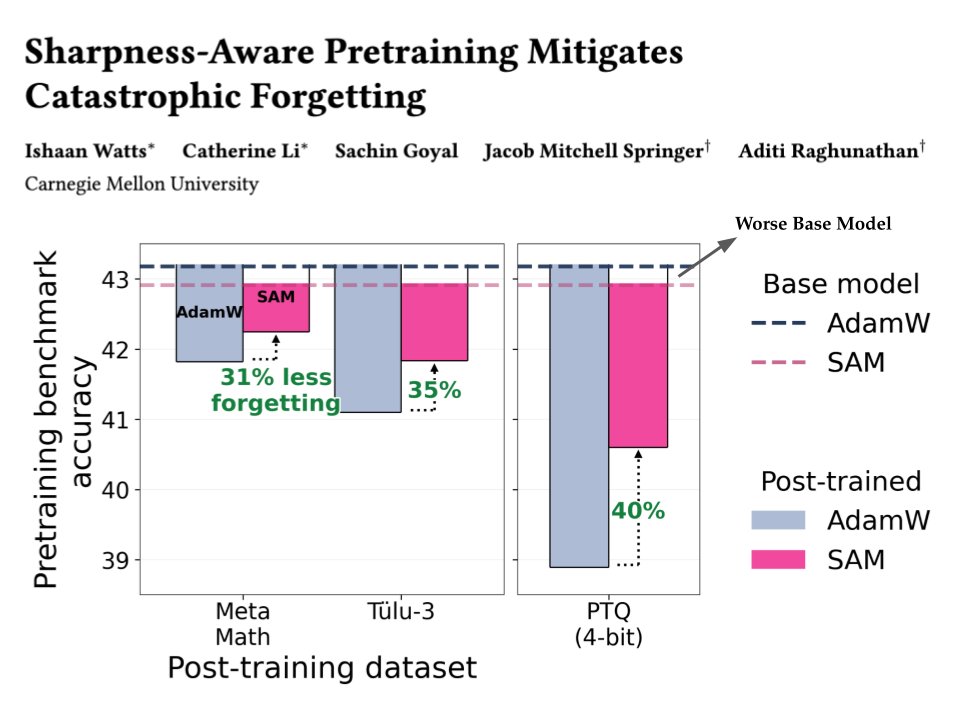
Spending billions to train the "best" base model? You might be optimizing the wrong thing! 🎯
We show that controlling sharpness during mid-training leads to over 35% less forgetting after fine-tuning / quantization... even when the base model itself gets worse.
🧵 Takeaways for pretraining:
- Use SAM (Sharpness-Aware-Minimization) in the final steps (~10%)
- Try much higher learning rates (yes, even ~10× larger)
1/9
That awkward moment when the authors of a paper you are just trying to help improve get so aggressive they send three long rebuttals decomposing your scores and arguing like their life depends on it. Like bro I don't even get paid to do this🥲