Breaking New Ground in LLM Reasoning - Proud to present MetaMath-Bagel-DPO-34B, the world's smartest ~30B model I personally trained. Grateful for Arka Pal's amazing guidance in this groundbreaking achievement.
Blog: https://t.co/DKMzkBlo9t
Model Weights: https://t.co/PZbVhmRdso
Improving LLM Reasoning - Open-Sourcing The World's Smartest ~30B Model
Today, we at Abacus AI are open-sourcing the smartest ~30B in the world - MetaMath-Bagel-DPO-34B.
This time, we’ve refined our focus on enhancing mathematical and reasoning capabilities in LLMs by primarily targeting the improvement of GSM8k scores without compromising performance on other benchmarks. We’ve adopted strategies involving data enrichment and interleaved training techniques. This new model applies our dataset MetaMath Fewshot dataset to the excellent Bagel models released by Jon Durbin.
Our new model largely maintains the performance of the Bagel model across the board but lifts GSM8K by nearly 13%, resulting in an overall improvement of about 1% on average. With a GSM8K score of 72.78, it's the top model in the hugging face leaderboard in its class (~30B models)
Our internal evaluations show that we are the best overall performing model in the 32B class.
Path to Improved Reasoning:
The first step of the training process was a supervised fine-tuning (SFT) run using the MetaMathFewshot, Orca, and ShareGPT datasets starting from a bagel SFT base model. Whilst this did improve the GSM8K score significantly, we found that this alone was not sufficient to come close to DPO-tuned models in the same class.
Interleaving DPO and SFT
Driven by the promising results of this first experiment, we decided to repeat the process with a post-DPO model.
However, doing so lost performance in TruthfulQA and ARC, primarily because these high benchmark scores are centered around DPO training. Thus, we followed up with a second round of DPO after our SFT step. This technique proved effective, as it not only retained the GSM8K boost but also managed to restore drops in other metrics to a large extent.
Our blog post has all the relevant links, including a link to the open-source weights! (link to it in image alt)
Excited to unveil the LLM - Giraffe! 🦒
Worked with @siddartha_naidu & Arka Pal on this.
Extended context to 4K and 16K, tackling SOTA open-source LLM limitations.
Llama-1 based, Llama-2 soon. Eager for its impact on real-world AI! #AI#LLM 🚀
Repo: https://t.co/bImOOZJ0Wi
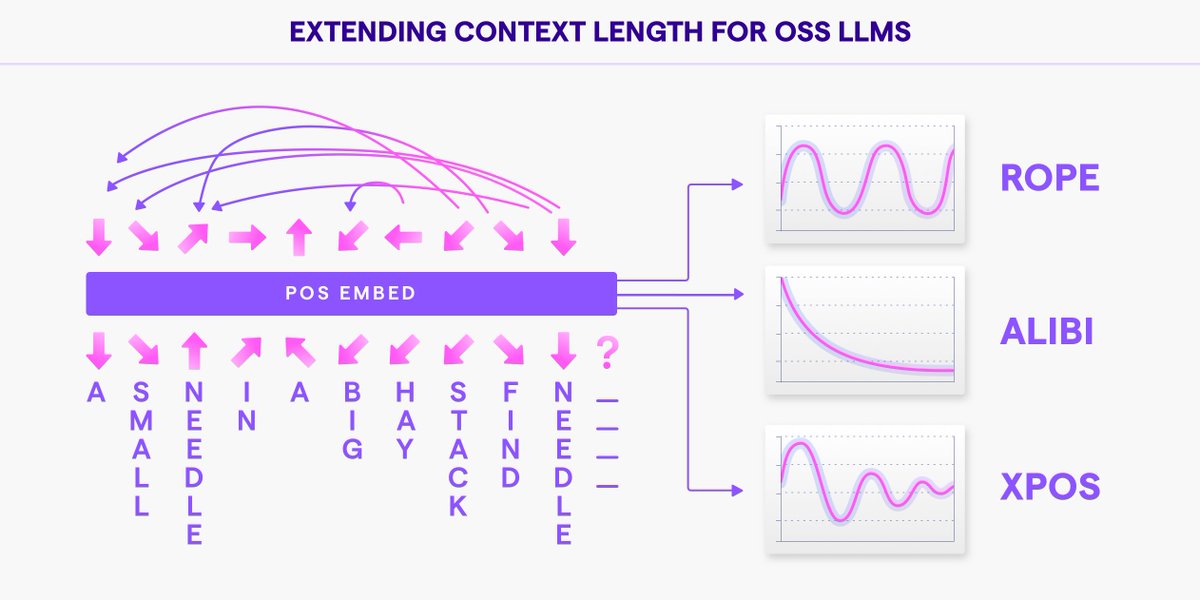
🌟Announcing Long Context OSS LLM - Giraffe 🌟
We are thrilled to announce 2 new open-source LLMs!
Today's SOTA open-source LLMs have one big shortcoming!
These LLMs have a very small context length of only 2K
This translates to them not being very useful when it comes to creating a Custom LLM based on your knowledge base.
You can’t send the LLM much data in a single call, which has a very negative effect on model performance.
Giraffe is a Llama 1 fine tune that extends context lengths to 4K and 16K.
We are open-sourcing these models, evaluation datasets, and performance experiments.
These models work well for real-world applied AI systems
Relevant links:
Git repo: https://t.co/2DDBeWePAu
Huggingface:
16k context - https://t.co/pSP1uHmxTL
4k context - https://t.co/FAuTrLDbeh
Blog post: https://t.co/OqznHl30qk