❤️ At Abridge, feedback is our oxygen—and the most heartfelt feedback we get finds its way into a special internal channel we call "𝗟𝗼𝘃𝗲 𝗦𝘁𝗼𝗿𝗶𝗲𝘀."
This holiday season, we asked Abridgers to share their favorite 𝗟𝗼𝘃𝗲 𝗦𝘁𝗼𝗿𝗶𝗲𝘀.
𝗪𝗮𝘁𝗰𝗵 𝘁𝗵𝗲 𝗺𝗼𝗺𝗲𝗻𝘁𝘀 𝘁𝗵𝗮𝘁 𝗶𝗻𝘀𝗽𝗶𝗿𝗲 𝘂𝘀.
Interested in the intersection of healthcare and cutting edge applied science (LLMs, multilinguality, multimodal models, speech recognition, etc.)?
We’re hiring machine learning scientists at @AbridgeHQ 🚀
DM me or apply here: https://t.co/vibpb9W0lH
What makes being an Abridger truly special? ✨
For @LiangDavis, Staff Research Scientist: “It’s this culture of being able to see past what’s directly in front of you…and into the lives of the patients, the clinicians, the doctors, the nurses.”
❤️🩹 At Abridge, we’re not just building a groundbreaking AI solution—we’re shaping the future of healthcare by putting patients and clinicians at the heart of everything we do.
🚀 If you’re ready to join one of the most exciting, mission-driven teams in healthcare, we’re hiring: https://t.co/zQzOyPIxoz
1.
Healthcare systems need enterprise-grade AI solutions they can trust.
Read our latest whitepaper to learn more about what enterprise-grade AI for healthcare looks like:
https://t.co/rQiSv0gMJN
Evaluation of ambient scribes is a formidable task due to the free-form nature of generated text. Rigor requires automated metrics, strong benchmarks, clinician-in-loop trials, and in vivo testing. Learn how we're tackling these challenges at @AbridgeHQ:
https://t.co/8oWka8elwh
new post - we took a look at behind the technical curtain some of the interesting engineering challenges behind a company (@AbridgeHQ ) training their own LLMs.
-dealing with multiple languages
-handling model drift
-generalist models vs. healthcare specific ones
and more
(just fyi, this one is a sponsored post but it's pretty interesting if you're interested in healthcare-specific LLMs)
We presented Belebele at ACL 2024 this week! (Thx to @LiangDavis and @ImSNShukla)
A year on from its release, it’s been really cool to see the diversity of research projects that have used it. The field is in dire need of more multilingual benchmarks !
🌐 We loved presenting at the Out-Of-Pocket Gen AI x Healthcare Ops Hackathon. Our very own @LiangDavis demoed Abridge and spoke about the importance of multilinguality in health tech.
🗣️ Did you know?
•Over 350 languages are spoken in the United States.
•20% of Americans speak two or more languages.
•More than 11% of patients in California-licensed hospitals prefer to speak Spanish (CA Dept. Healthcare Access to Information, 2021).
Yet, multilingual performance remains a significant challenge today, even for state-of-the-art models like GPT-4 (The Belebele Benchmark. Bandarkar et al. ACL 2024). Tokenizations are often biased towards English, making it more expensive and less efficient for languages like Arabic, Hindi, and Chinese.
Davis also discussed ways we can start tackling this issue:
•Leverage both English and non-English data for training.
•Consider up-weighted sampling of important languages during training.
•Increase rank for parameter efficient fine-tuning on multilingual data.
•Construct intelligent multilingual vocabularies (XLM-V. Liang et al. EMNLP 2023).
At Abridge, we care deeply about multilingual performance. Our speech recognition is tuned to handle medical conversations across 14+ languages, coping with cross-talk, background noise, and an evolving landscape of maladies, medications, and practice patterns. Learn more about our AI here: https://t.co/QTHy5DOW4F
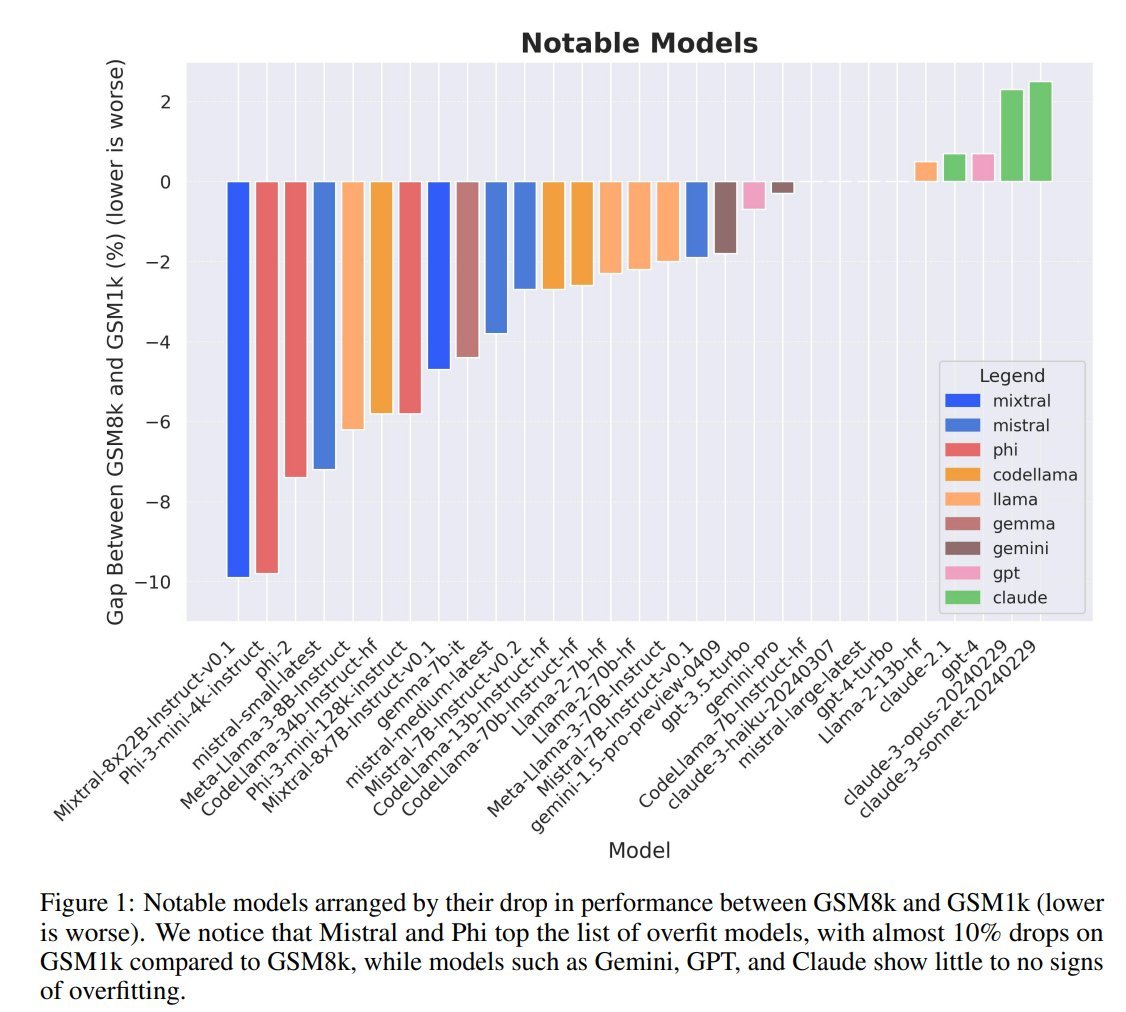
How overfit are popular LLMs on public benchmarks?
New research out of @scale_ai SEAL to answer this:
- produced a new eval GSM1k
- evaluated public LLMs for overfitting on GSM8k
VERDICT: Mistral & Phi are overfitting benchmarks, while GPT, Claude, Gemini, and Llama are not.
We’re thrilled to be featured on the @Forbes AI 50, alongside companies that inspire us such as OpenAI, Anthropic, Databricks, and others.
It’s a special privilege to represent the impact of AI in healthcare, improving the care delivery experience at scale for both clinicians and patients. Grateful to Forbes for this acknowledgment, and to the health systems we work with for their partnership.
Check out the full list: https://t.co/7Pyh7e3u60 #ForbesAI50
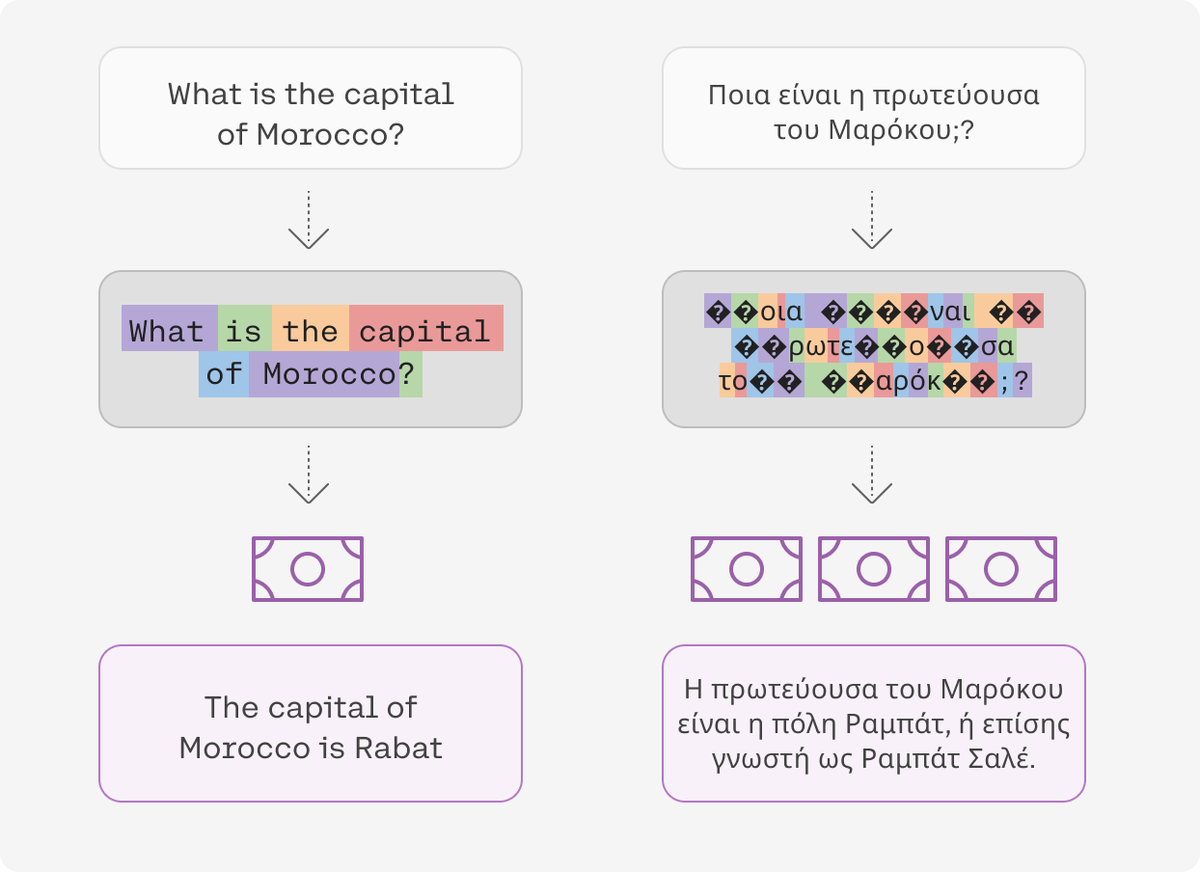
Ahia et al. (2023; https://t.co/XKPAybRVY6) observed that the same is true for current LLMs such as ChatGPT: They segment text in non-English languages into many more tokens and are thus much more costly to use in such languages.
They call this “double unfairness”: higher prices + lower utility (reduced performance) in these languages.
📣 We are thrilled to announce a research collaboration and investment from @nvidia to help us scale our multilingual clinical conversation platform across the entire U.S. healthcare system.
Learn more here: https://t.co/D5yT2mpJ8Q