S3 API underneath. The webapp is one way in. rclone, AWS CLI, any SDK are others. ~10MB binary. Files never move.
Looking for a few people with messy NAS setups to try it before launch. DM me your setup.
https://t.co/JjzffW2JXK
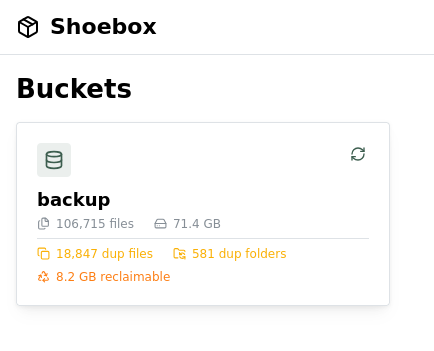
Pointed Shoebox at a directory. 106,715 files. Found 18,847 duplicates across 581 folders. 8.2 GB I can reclaim.
This is what that looks like in a browser.
#buildinpublic#selfhosted#rustlang
Started this to find duplicate photos. Built an S3 server. Then realized a terminal can't show you which photos are duplicated.
So I built a webapp too. Point a browser at your Shoebox instance and browse your duplicates visually. One curl command enables CORS.
@hboon Same energy as running your own home server. Once you stop metering every resource, you just… build. Hetzner's pricing makes that easy to forget about.
Started building a dedup tool. Accidentally built an S3 server.
Pointed it at a directory on my NAS. Opened Cyberduck. It just... connected. No config. No adapter. Just S3.
#buildinpublic#rustlang#selfhosted
The part that surprised me: I built this to find duplicate photos. But "S3 endpoint for local files" turns out to be useful for a dozen things I wasn't thinking about.
The best side projects are the ones that outgrow the original problem.
The thing I keep noticing: rclone connects. AWS CLI connects. No adapters. Implement the spec, the ecosystem shows up.
Files stay where they are. ~10MB binary.
The filesystem scanner just landed on the local S3 server.
Drop a file on disk. It appears in S3 automatically. No upload needed. The scanner walks the directory, indexes it, and watches for changes in real time.
#buildinpublic#rustlang
Building an S3 server for local files.
Point it at a directory, get an S3 endpoint. Files stay where they are. Works with rclone, AWS CLI, any S3 SDK.
Started this to find duplicate photos. Realized I'm building something bigger.
#buildinpublic#rustlang#selfhosted#selfhosting
Deduplication fell out of content hashing. But the real value is the API layer.
Make local files accessible via S3. The ecosystem just works. The photo problem was the entry point, not the whole story.
Next: auth, multipart uploads for large files, and the filesystem scanner that indexes what's already on disk. That's the part I actually built this for.
#buildinpublic#rustlang#selfhosted
Under the hood: SQLite for metadata, filesystem layer with symlink safety, S3-compatible XML error responses. 49 tests passing. The boring infrastructure that makes everything else possible.