Datatype : une variable font OpenType qui transforme des expressions texte en graphiques inline — barres, sparklines, camemberts. Sans JS, sans image, juste de la typographie et des ligatures.
https://t.co/r0v8m9KpHy
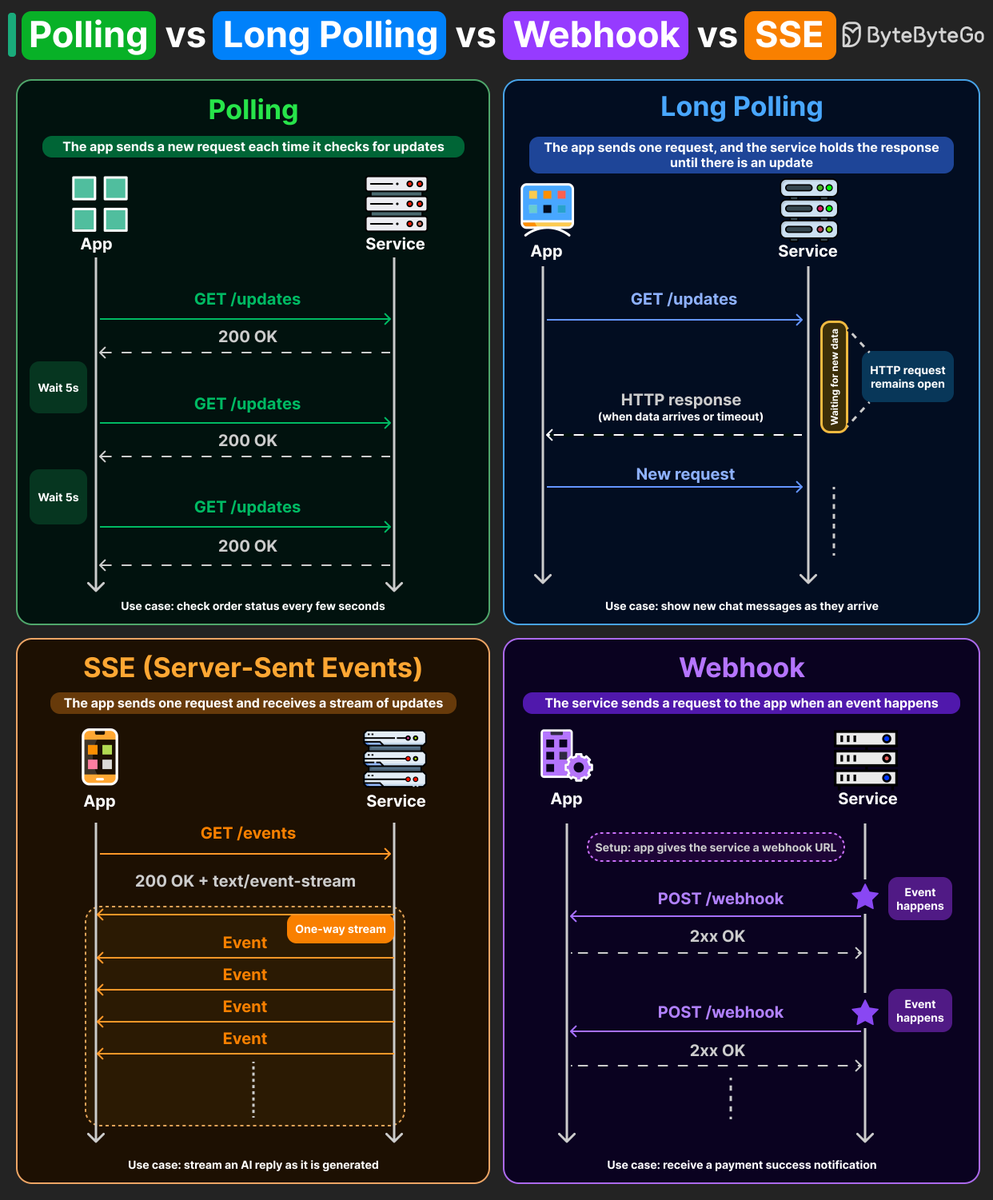
Polling vs Long Polling vs Webhooks vs SSE
Four ways to get updates from a server. Each one makes a different tradeoff between simplicity, efficiency, and real-time delivery.
Here's how they compare:
- Polling: The client sends a request every few seconds asking "anything new?" The server responds immediately, whether or not there's new data. Most of those requests come back empty, wasting client and server resources. For use cases like an order status page where a small delay is acceptable, polling is the simplest option to implement.
- Long Polling: The client sends a request, and the server keeps the HTTP connection open until new data is available or a timeout occurs. This means fewer empty responses compared to regular polling. Some chat applications used this pattern to deliver messages closer to real-time communication.
- Server-Sent Events (SSE): The client opens a persistent HTTP connection, and the server streams events through it as they're generated. It is one-way, lightweight, and built on plain HTTP. Many AI responses that appear token by token are delivered through SSE, streaming each chunk over a single open connection.
- Webhooks: Instead of the client asking for updates, the service sends an HTTP POST to a pre-registered callback URL whenever a specific event occurs. Stripe uses this for payment confirmations. GitHub uses it for push events. The client never polls or holds a connection open, it just waits for the server to call.
Many systems don't rely on a single pattern. You may use polling for order status, SSE for streaming AI responses, and webhooks for payment confirmations.
In one system design interview, I used Kafka.
In one system design interview, I used Redis.
In one system design interview, I used S3.
In ALL system design interviews, I used databases.
Databases are the backbone of every design, no matter the scale, stack, or domain.
If you understand how data is stored, queried, indexed, replicated, and partitioned, you already understand 70% of system design.
Don’t get distracted by every new shiny component; queues, caches, and orchestrators come and go.
But databases are forever.
Relational, NoSQL, time-series, vector, the patterns evolve, but the principles stay the same:
- Read and write paths
- Indexing and caching
- Transactions and isolation
- Replication and partitioning
Master how data flows, and you’ll see how every other part of the system connects.
Learn databases deeply.
Everything else is just optimization.
I've been collecting interface designs for 15+ years. every gesture, tool, menu that made me stop and think “wait how does this work”, “why does this matter?”, but also “who are the giants upon whom we build?”
Now i want to publish it: “Interface Lineage”.
next experiment in @GoogleAIStudio - an organic, procedural graph visualizing the movies as a growing ecosystem.
you can navigate through films (●), directors (▲), and actors (■), expanding subtrees with every click to discover hidden creative branches. everything is powered by Gemini and TMBD APIs.
was fun to build this one.
UUIDv4 vs UUIDv7 vs ULID, in practice:
1. UUIDv4: pure random. Great uniqueness. Terrible for DB indexes. Inserts scatter, B-tree bloats, cache misses. p99 gets weird at scale.
2. UUIDv7: time-ordered + random. Keeps “globally unique” but inserts are mostly sequential. Works nice with Postgres/MySQL primary keys.
3. ULID: also time-ordered, human-friendly, sortable as string. Good choice if you need lexicographic order in logs or URLs. Watch clock skew if you generate on many nodes.
In Production: default to UUIDv7 for primary keys. Use ULID when you want sortable strings. Avoid v4 for hot indexed tables.
Diagrams are becoming my primary way of reasoning about code with Agents. And I didn't find anything there that I'm happy to look at all day long.
Mermaid as a format is amazing - so we built something beautiful on top of it. It's called Beautiful Mermaid
https://t.co/HCE43DM7Gx
B-tree database lookups are way slower without a memory cache in place + a good replacement policy for OLTP.
MySQL uses a segmented LRU whereas Postgres uses a clock-sweep algorithm. Both good choices for different reasons.
StackOverflow всё
График ежемесячно заданных новых вопросов достиг дна.
Запущенный в 2008 году сайт, где люди искали друг у друга совета по тому, как исправить баги в коде и решить задачи, в своё время был главным ресурсом для разработчиков. Но сейчас ежемесячный объём новых постов упал практически до нуля https://t.co/3H7RbptMh4
Все скажут: «Понятно, у живых людей больше никто совета не спрашивает. Чёртовы нейросети, угробили проект!»
Это если вы сами никогда не пробовали спрашивать совета у других программистов в интернете, особенно в русскоязычном:
— Надо гуглить, прежде чем спрашивать.
— Это решается элементарно, но я не буду тратить на это своё время.
И моё любимое: на вопрос «Как сделать X и Y?» отвечать «А зачем?»
По графику видно, что снижение востребованности StackOverflow пошло задолго до запуска даже ChatGPT 3.5.
И как любит полушутя повторять бывший глава Google Эрик Шмидт, сегодня наконец-то доступны программисты, которые на самом деле делают то, о чём ты их просишь.
𝗕𝗶𝗴-𝗢 𝗡𝗼𝘁𝗮𝘁𝗶𝗼𝗻 𝗖𝗵𝗲𝗮𝘁 𝗦𝗵𝗲𝗲𝘁
Big O notation is a mathematical shorthand used to describe the runtime of algorithms.
It's a fundamental concept in computer science that helps us understand how an algorithm's performance changes as the input size grows.
𝗕𝗶𝗴-𝗢 𝗡𝗼𝘁𝗮𝘁𝗶𝗼𝗻 expresses the upper bound of an algorithm's runtime (in terms of space or time complexity). It tells us how the algorithm's runtime grows as the input size increases in the worst case.
Time complexity measures how long an algorithm takes to run, while space complexity measures how much memory an algorithm requires.
To analyze the Big O notation of an algorithm, we need to identify the dominant term in the runtime function.
The dominant term is the term that grows the fastest as the input size increases. All other terms can be ignored.
Examples of time complexity using Big-O notation:
🔵 𝗢(𝟭): 𝗖𝗼𝗻𝘀𝘁𝗮𝗻𝘁 𝘁𝗶𝗺𝗲. The runtime of the algorithm does not depend on the input size. An example is accessing a specific element of an array.
🔵 𝗢(𝗹𝗼𝗴 𝗻): 𝗟𝗼𝗴𝗮𝗿𝗶𝘁𝗵𝗺𝗶𝗰 𝘁𝗶𝗺𝗲. The runtime of the algorithm grows logarithmically with the input size. An example is using binary search to find an element in a sorted array.
🟡 𝗢(𝗻): 𝗟𝗶𝗻𝗲𝗮𝗿 𝘁𝗶𝗺𝗲. The runtime of the algorithm grows linearly with the input size. An example is finding an element in an unsorted array.
🟡 𝗢(𝗻 𝗹𝗼𝗴 𝗻): 𝗟𝗼𝗴-𝗹𝗶𝗻𝗲𝗮𝗿 𝘁𝗶𝗺𝗲. The runtime of the algorithm grows log-linearly with the input size. Examples include efficient sorting algorithms such as Quicksort and Heapsort.
🟠 𝗢(𝗻^𝟮): 𝗤𝘂𝗮𝗱𝗿𝗮𝘁𝗶𝗰 𝘁𝗶𝗺𝗲. The algorithm's runtime grows quadratically with the input size. Simple sorting algorithms, such as insertion or selection sort, are examples.
🔴 𝗢(𝟮^𝗻): 𝗘𝘅𝗽𝗼𝗻𝗲𝗻𝘁𝗶𝗮𝗹 𝘁𝗶𝗺𝗲. The runtime of the algorithm grows exponentially with the input size. An example is the recursive Fibonacci method.