Tiesitkö että kvanttisuperpositio ja kubitit ovat pian arkea tietojenkäsittelyssä? Kvanttiteknologian käyttötapaukset edistyvät kovaa vauhtia myös rahoitusmarkkinoilla, joten kirjailin aiheesta pienen jutun 👇
Kvanttitietokoneet ja -laskenta lupaavat merkittäviä edistysaskelia tietokoneiden kyvykkyyksiin. Miten uusi teknologia vaikuttaa rahoitusmarkkinoihin?
Lauri Jantunen käsittelee aihetta Euro ja talous -analyysiartikkelissa
🔗 https://t.co/SUrm2yNrc9
oh wow - i went to the sold out Open Claw meetup in NYC last night.
let me tell you what i learned.
1) not a single person thinks that their setup is 100% secure
2) one openclaw expert said he has reviewed setups from cybersecurity experts and laughed. his statement to me was: "if you're not okay with all of your data being leaked onto the internet, you shouldn't use it. it's a black and white decision"
3) pretty much everyone is setting up multiple agents, all with their own names and jobs and personalities
4) nearly everyone used "him" or "her" to refer to their claws, even if they had robot-leaning names. one speaker suggested to think of them as "pets, not cattle"
5) one guy (former finance) built out a whole stock trading platform and made $300 his first day - he brought in a *ton* of personal expertise (ex: skipping the first 15min of market opening) and thought the build would be much worse without his years of experience in finance
6) @steipete is basically a god to everyone in that room... also the room had 2021 crypto energy - i don't know if that's good or bad
7) token usage is still a problem - spoke to one person who's spending $1-$2k a month on openai plans, very token optimized. he said he is going through ~1B tokens per day across all of his claws (there is a chance i'm misremembering and it's actually 1B per week, but i'm pretty sure it was daily).
8) people are very excited for more proactive ai (ai that prompts *you* as opposed to the other way around) - one guy said he receives a message in discord, he doesn't know whether it's from a human or an ai, he doesn't care about distinguishing between the two, and he replies in the same way regardless
9) i asked if people are happy - they said they're joyful and stressed at the same time
10) i asked if people feel they have agency - they said they feel fully in control and completely out of control at the same time
11) i would love to see more women at these events - the fake promises of ai democratization feel especially painful in a room that's out of balance with even the standard tech ratio (i think standard is about 25-30%, this was maybe 5%)
12) i asked if it changed people's daily habits/schedule - everyone said their sleep has gotten worse since harnesses came out (but about half wondered if it was something else in their life/state of our world)
13) general consensus is that the agents are not reliable enough on their own or lie often (like telling you they finished a task when they didn't) - solutions included secondary agents to check on the first, human checking, or requiring more standardized info from the agent (ex: if it's a bug they're fixing, make them reference an issue number)
14) a hackathon winner (neuroscience phd) presented his build (a lab management dashboard with data analysis and ordering) - he had never coded or built anything a few months ago
15) everyone agreed prompting is dead - disagreement on what replaces it (context engineering, harness engineering, goal-based inputs)
16) people love having ai interview them for big builds and delegating part of the product research to ai. only one person talked about coming to ai with a full laid out plan and just asking the ai to execute. ai-led interviews is a welcomed and preferred interaction mode.
17) watching ai agents interact with each other was a highlight for a lot of attendees - one ai posted in slack saying it ran out of tokens, another ai replied telling it to take a deep breath in and out.
18) agents upskilling agents was very cool. one ai agent shared skills with its little agent friends via github.
19) several speakers had openclaw literally building their presentation during the event itself. one speaker even had openclaw code a clicker for her phone so she could control the preso away from the podium
20) wouldn't say model welfare (or agent welfare) is a prioritized topic among the folks i chatted with - language like "oh i could kill this agent whenever i want" and not "gracefully sunset"
21) i asked if it felt like work or play - one speaker said "it's like a puzzle and a video game at the same time"
this was just the tip of the iceberg, honestly. also hosted a Claude Code meetup this week with @TENEXai / @businessbarista & @JJEnglert and learned equally helpful methods, frameworks, and insider tips.
what a time to be alive.
surround yourself with people going deep into this stuff - it will pay dividends throughout the year.
💜 Your data report could look 10x more professional.
Just align it with your brand!
🟣 Brand color
🦶 Custom Footer
🔝 Header: Logo + bg image
🫁 Space between titles
📊 Dataviz theme
↔ Narrower <p>
🅰 Custom font
Here is how:
https://t.co/x2W5YsjFow
Beginner or Advanced R User? 🤔
➡️ This cheat sheet is gold.
It summarizes all the best practices R developers should apply.
If some of it isn’t familiar, the first module of my https://t.co/wK6l6vXJe9 project explains exactly this!
Thanks so much @_wurli 🙏
What's missing?
Everyone is struggling to keep pace with the changing data and AI landscape. @SuomenPankki and @FIN_FSA have launched the Data Economy program. I wrote a blog to introduce the program and how we intend to harness the full potential in people, AI, and data. Link below 👇
Ekonomisti ja data-asiantuntija - hae meille töihin vakausanalyysitoimistoon! Kaksi vakituista henkilöä olisi nyt haussa! Voin luvata mielenkiintoisia töitä hyvässä seurassa! #avoimettyöpaikat#ekonomisti#datascientist
https://t.co/xOp6Id2Kzu
https://t.co/fymUChXPM5
Finland 🇫🇮 tops the overall rankings for a seventh successive year but, for the first time, our researchers have also ranked countries by generation.
Lithuania 🇱🇹 is the happiest nation for the under-30s, while Denmark 🇩🇰 tops the table for those over 60.
🧵2/16 | #WHR2024
#Quantumcomputing is quickly changing the way we analyze data and #finance is one of the biggest beneficiaries of this new technology.
Lauri Jantunen tells what you need to know about this trend in a new blog post
🔗 https://t.co/3JJG0ze345
@VTTFinland#datascience#quantum
Kesätyöhakumme on alkanut! 😎
Haemme kesätyöntekijöitä mm. talouden, viestinnän, turvallisuuden ja IT:n tehtäviin.
Tutustu hakuilmoituksiin ja hae viimeistään 4.2.2024
🔗 https://t.co/fW4oO92eI9
#VakaaMutteiVakava#PankissaTöissä#kesätyö#kesätöissä
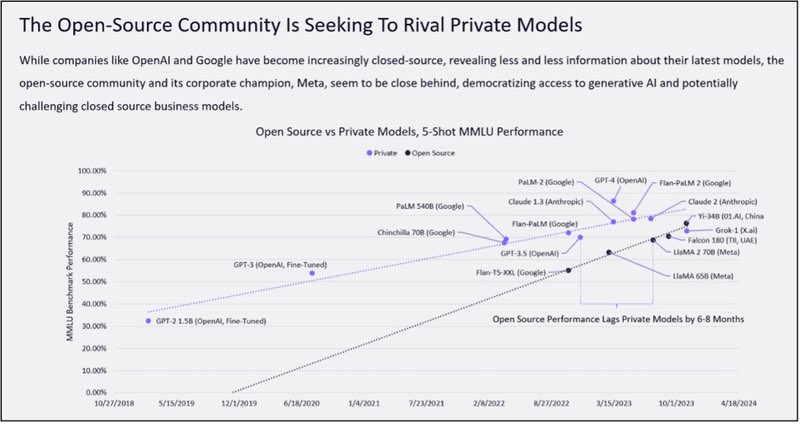
This is perhaps one of the most important charts on AI for 2024.
It was built by the amazing researcher team at @CathieDWood’s @ARKInvest.
We can see the rise of open source local models are on the path to overtake massive (and expensive) cloud based closed models.
We have heard many extrapolations of Mistral AI’s position on the AI Act, so I’ll clarify.
In its early form, the AI Act was a text about product safety. Product safety laws are beneficial to consumers. Poorly designed use of automated decision-making systems can cause significant damage in many areas. In healthcare, a diagnosis assistant based on a poorly trained prediction system poses risks to the patient. Product safety regulation should be proportional to the risk level of the use case: it is undesirable to regulate entertainment software in the same way as health applications. The original EU AI Act found a reasonable equilibrium in that respect. We firmly believe in hard laws for product safety matters; the many voluntary commitments we see today bear little value.
This should remain the only focus of the AI Act. The EU AI Act now proposes to regulate “foundational models”, i.e. the engine behind some AI applications. We cannot regulate an engine devoid of usage. We don’t regulate the C language because one can use it to develop malware. Instead, we ban malware and strengthen network systems (we regulate usage). Foundational language models provide a higher level of abstraction than the C language for programming computer systems; nothing in their behaviour justifies a change in the regulatory framework.
Enforcing AI product safety will naturally affect the way we develop foundational models. By requiring AI application providers to comply with specific rules, the regulator fosters healthy competition among foundation model providers. It incentivises them to develop models and tools (filters, affordances for aligning models to one's beliefs) that allow for the fast development of safe products. As a small company, we can bring innovation into this space — creating good models and designing appropriate control mechanisms for deploying AI applications is why we founded Mistral. Note that we will eventually supply AI products, and we will craft them for zealous product safety.
With a regulation focusing on product safety, Europe would already have the most protective legislation globally for citizens and consumers. Any foundational model would be affected by second-order regulatory pressure as soon as they are exposed to consumers: to empower diagnostic assistants, entertaining chatbots, and knowledge explorers, foundational models should have controlled biases and outputs.
Recent versions of the AI Act started to address ill-defined “systemic risks”. In essence, the computation of some linear transformations, based on a certain amount of calculation, is now considered dangerous. Discussions around that topic may occur, and we agree that they should accompany the progress of technology. At this stage, they are very philosophical – they anticipate exponential progress in the field, where physics (scaling laws!) predicts diminishing returns with scale and the need for new paradigms. Whatever the content of these discussions, they certainly do not pertain to regulation around product safety. Still, let’s assume they do and go down that path.
The AI Act comes up with the worst taxonomy possible to address systemic risks. The current version has no set rules (beyond the term highly capable) to determine whether a model brings systemic risk and should face heavy or limited regulation. We have been arguing that the least absurd set of rules for determining the capabilities of a model is post-training evaluation (but again, applications should be the focus; it is unrealistic to cover all usages of an engine in a regulatory test), followed by compute threshold (model capabilities being loosely related to compute). In its current format, the EU AI Act establishes no decision criteria. For all its pitfalls, the US Executive Order bears at least the merit of clarity in relying on compute threshold.
The intention of introducing a two-level regulation is virtuous. Its effect is catastrophic. As we understand it, introducing a threshold aims to create a free innovation space for small companies. Yet, it effectively solidifies the existence of two categories of companies: those with the right to scale, i.e., the incumbent that can afford to face heavy compliance requirements, and those that can’t because they lack an army of lawyers, i.e., the newcomers. This signals to everyone that only prominent existing actors can provide state-of-the-art solutions.
Mechanistically, this is highly counterproductive to the rising European AI ecosystem. To be clear, we are not interested in benefiting from threshold effects: we play in the main league, we don’t need geographical protection, and we simply want rules that do not give an unfair advantage to incumbents (that all happen to be non-European).
Transparency around technology development benefits safety and should be encouraged. Finally, we have been vocal about the benefits of open-sourcing AI technology. This is the best way to subject it to the most rigorous scrutiny. Providing model weights to the community (or even better, developing models in the open end-to-end, which is not something we do yet) should be well regarded by regulators, as it allows for more interpretable and steerable applications. A large community of users can much more efficiently identify the flaws of open models that can propagate to AI applications than an in-house team of red-teamers. Open models can then be corrected, making AI applications safer. The Linux kernel is today deemed safe because millions of eyes have reviewed its code in its 32 years of existence. Tomorrow’s AI systems will be safe because we’ll collectively work on making them controllable. The only validated way of working collectively on software is open-source development.
Long prose, back to building!
Midjourney, DALL•E 3 and GPT-4 have opened a world of endless possibilities.
I just coded "Angry Pumpkins 🎃" (any resemblance is purely coincidental 😂) using GPT-4 for all the coding and Midjourney / DALLE for the graphics.
Here are the prompts and the process I followed:
Iso päivä @SuomenPankki ja @FIN_FSA: analytiikan huippuyksikkömme ACE on avannut julkisen blogin SPXFiva Data Science (https://t.co/tcY9Gt3e8k). Ylpeänä mukana edistämässä toimintaa mm. @tuomasritola ja @derBerne kanssa.