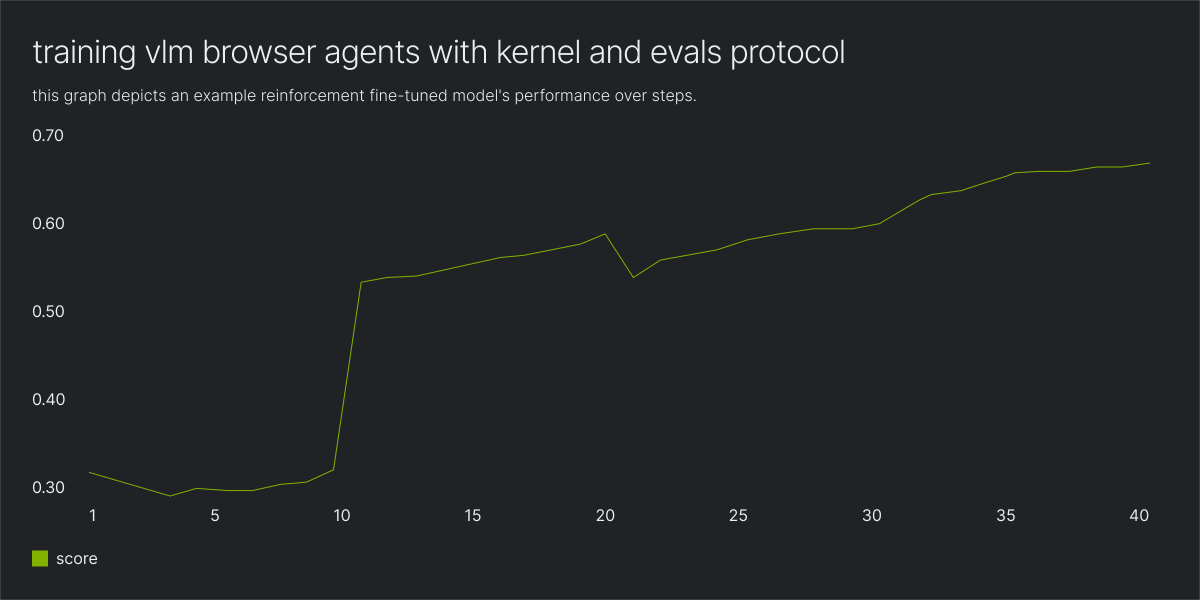
Fireworks Training is now in preview.
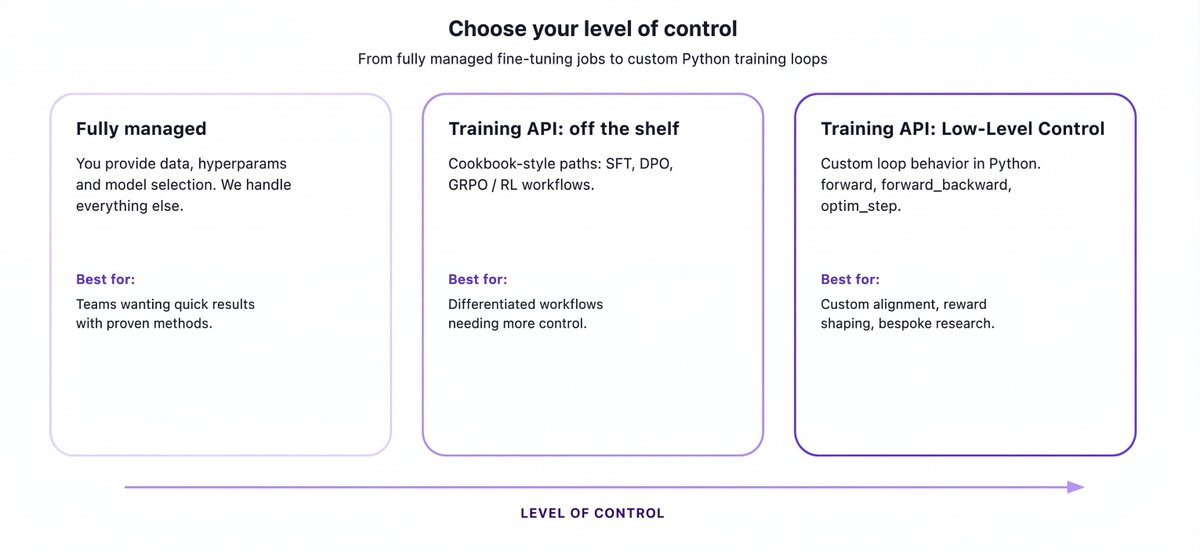
You can now full-parameter fine-tune Kimi K2.5 (1T params, 256k context) with custom loss functions (GRPO, DRO, DAPO, or bring your own) on managed infra.
@genspark_ai built their proprietary model stack in four weeks. @vercel hit 93% error-free generation with RFT. @cursor_ai runs their RL rollout fleet on Fireworks.
Full-parameter from 8B to 1T. Multi-LoRA serving. Managed or bring your own training loop.
Your model is your product. Your data is your moat.
https://t.co/kyz7HzihC1
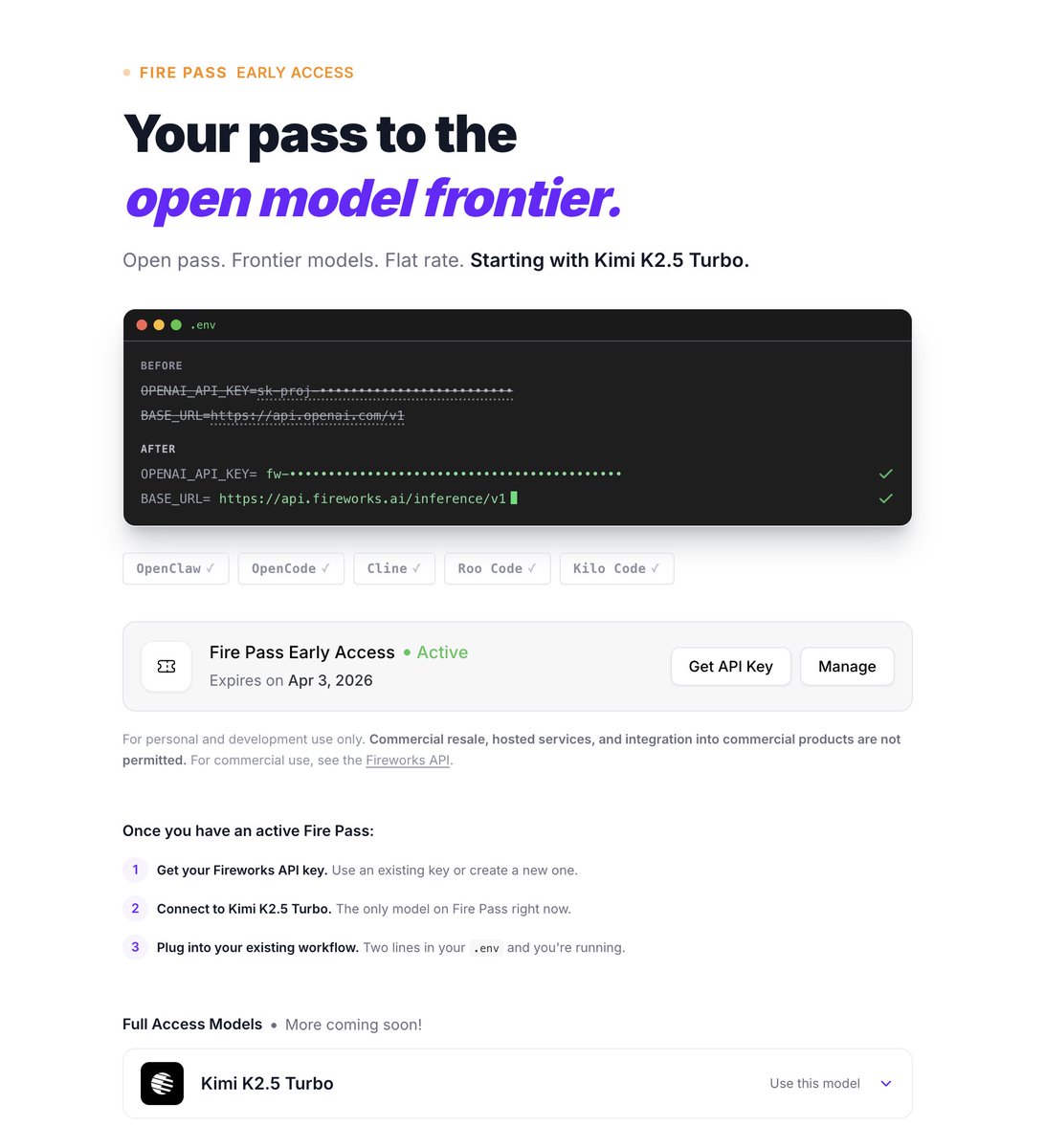
Fireworks AI fire pass is so good
It's Kimi K2.5 Turbo right now at like 250 tok/s and idk what the limits are but it's HIGH
oh and free trial but $7 per week
Wrote a deep dive on implementing a language model from scratch in JAX and scaling it with distributed training!
If you’re coming from PyTorch and want to see how the same ideas look in JAX, or just want a hands-on intro to distributed training, check out this blog post: https://t.co/nsR3O3Zjxg
Comes with code + an assignment and test cases so you can follow along!
Composer 2 beats Opus on TerminalBench at a fraction of the cost.
The ingredients: coding focus only, data flywheel, cracked RL team, and infrastructure that can keep up.
@FireworksAI_HQ powered the inference and RL scaling behind Composer 2. Scaling RL is still genuinely hard, and we're proud we could help make it less so.
Congrats to @cursor_ai on shipping a great model!
@DimitrisPapail noticed tau bench airline wasn't called out anywhere here. any interesting findings there? my sense is labs are moving away from it (or using the modified Anthropic version), due to variance from the simulated user, which also probably makes it hard to predict.
We've raised $6.5M to kill vector databases.
Every system today retrieves context the same way: vector search that stores everything as flat embeddings and returns whatever "feels" closest.
Similar, sure. Relevant? Almost never.
Embeddings can’t tell a Q3 renewal clause from a Q1 termination notice if the language is close enough.
A friend of mine asked his AI about a contract last week, and it returned a detailed, perfectly crafted answer pulled from a completely different client’s file.
Once you’re dealing with 10M+ documents, these mix-ups happen all the time.
VectorDB accuracy goes to shit.
We built @hydra_db for exactly this.
HydraDB builds an ontology-first context graph over your data, maps relationships between entities, understands the 'why' behind documents, and tracks how information evolves over time.
So when you ask about 'Apple,' it knows you mean the company you're serving as a customer. Not the fruit.
Even when a vector DB's similarity score says 0.94.
More below ⬇️
New blog from the team at Fireworks:
Where training–inference parity breaks in MoE models
Kernel fusions that are mathematically identical can still drift numerically. We walk through the bugs we hit while serving Kimi K2.5 and training Qwen3.5-MoE, and how we fixed them.
Worth a read if you're building high-performance inference:
https://t.co/jDolrWzjxn
We just raised a $5.3M seed round for Orange Slice, co-led by 1984 Capital and Moxxie Ventures, with participation from angels like Paul Graham.
We’re building AI agents, inside a spreadsheet, that help sales teams find companies that already want to buy.
The reality is most sales teams don’t struggle with effort - they struggle with timing.
Reps spend huge amounts of time working static lists and broad targeting, chasing leads that were never going to convert. That creates noise, low reply rates, and wasted cycles.
Top companies like Ramp solve this with dedicated growth engineers building internal data workflows.
We’re making that same capability accessible to everyone else.
At its core, the challenge is simple: finding customers who already have the problem you solve.
Orange Slice turns the spreadsheet into a system for discovering buying signals - agents research company sites, news, social signals, and niche sources like court records or building permits, then structure that information directly into columns teams can act on.
Not “might be a fit.”
But “likely in-market.”
So instead of guessing who to target, teams build and refine living lists of high-intent accounts inside a sheet.
Still early. Still learning.
But we’re excited to keep building.
Kishan and I met sophomore year on a Bollywood dance team at Michigan — and I couldn’t ask for a better co-founder.
Grateful to our team, customers, and investors for believing in this vision.
LLMs suck at creating tests. Their tests are too basic and they cheat all the time, validating buggy behavior to get 100% test coverage rather than flagging real bugs.
So, I created an opencode plugin to fix this
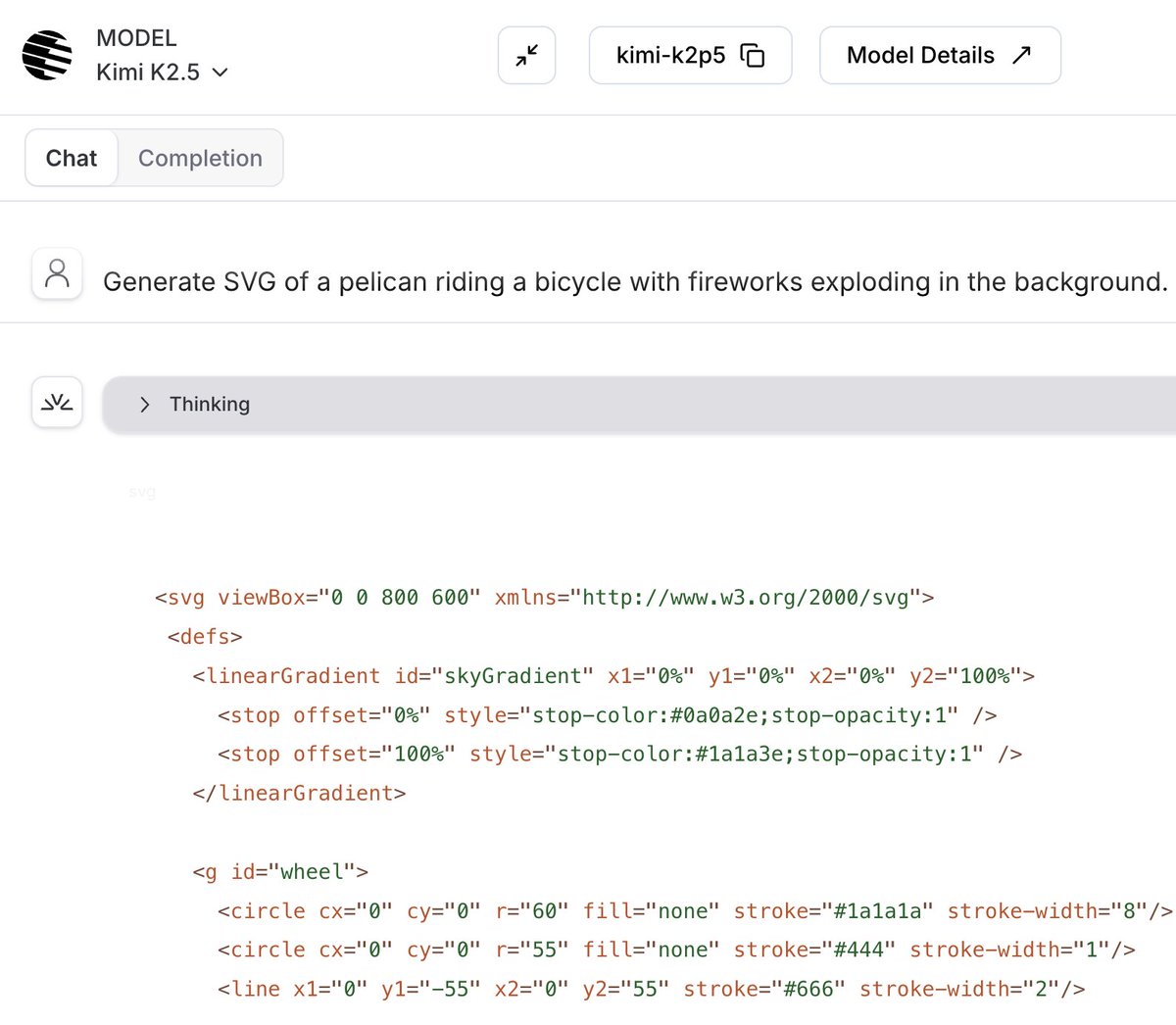
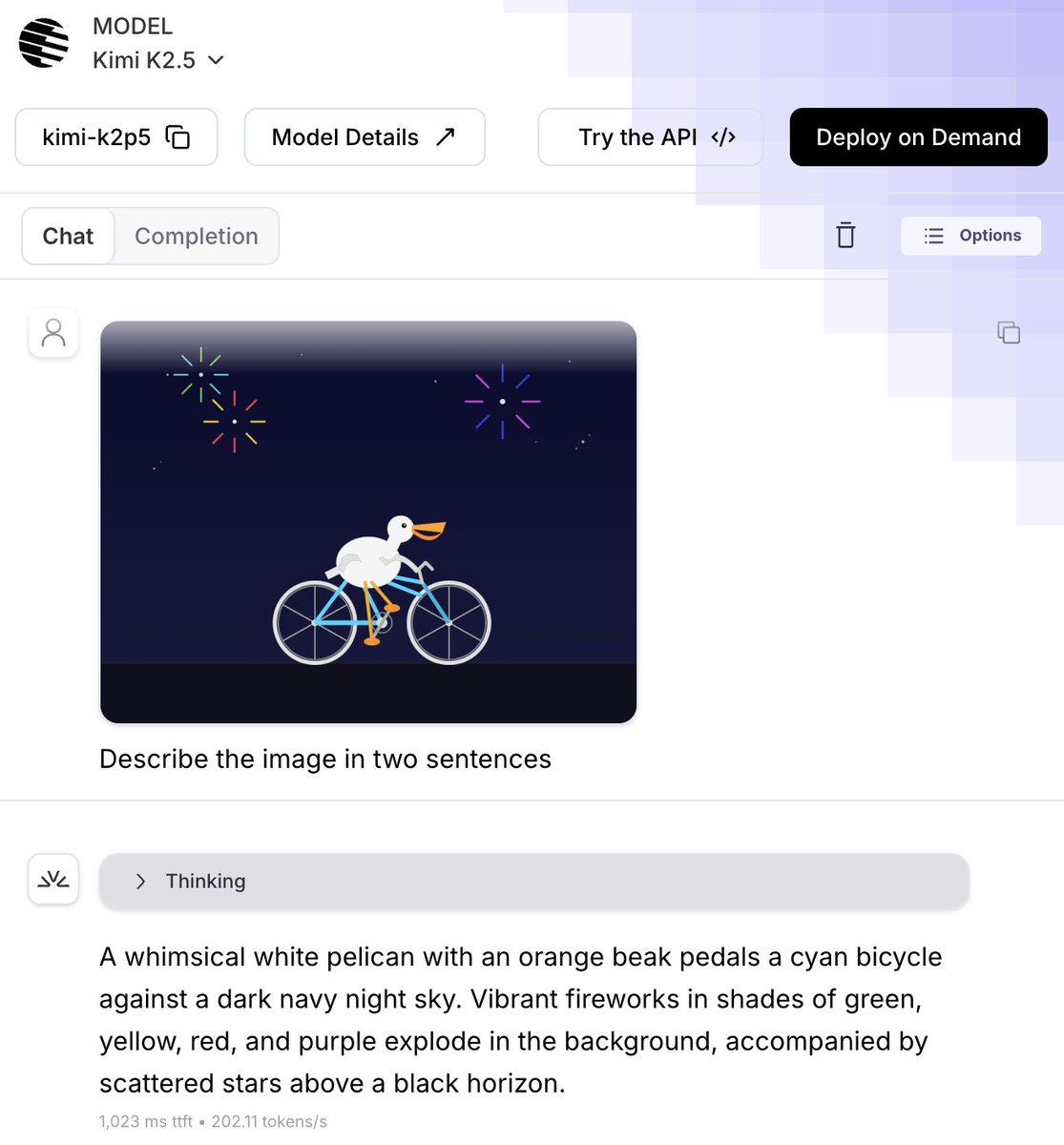
🌕 Kimi K2.5 = open SOTA reasoning + vision + 256K context + agentic coding
🏎 200+ t/s on @FireworksAI_HQ (soon even faster)
✅ Nails @simonw's "pelican on a bike" test in both directions
Try it now on Fireworks and hats off to @Kimi_Moonshot