I'm joining Carnegie Mellon's CS Department (and HCII by courtesy) as an assistant professor in Fall 2027!
I'll be recruiting PhD students next cycle. If you're interested in AI systems or human-AI collaboration, list me in your application. Stay tuned for more about my new lab!
Hello @DSPyOSS community. What is a clean way to re-configure dspy with lm instance during optimization?
I have API access where authentication signature needs to be updated at regular intervals.
@kellyhongsn Thanks for sharing the article. In the first figure in the results section, what does "(n models)" mean? I understood the gist from the figure, but couldn't understand all the details. Could you pls clarify?
It’s unfortunate that a bug in OpenReview allowed reviewer and AC identities to be extracted.
That said, this is a chance to reflect on our practices: We should write our reviews as if our names were attached to them and visible to authors and the broader community, even when the recommendation is a strong reject!
I've been experimenting with both GEPA & MIPRO a lot lately, on both text & image data. Thoughts from the talk that resonated with me the most are:
1) Meet people where they are!
2) Positioning prompt optimizers as discovering latent requirements.
I've now put a full practice run of this DSPy meet-up talk on YouTube (link in this thread). I am told recordings of @lateinteraction's and @LakshyAAAgrawal's talks are coming soon (my own live version had technical issues).
Announcing my new course: Agentic AI!
Building AI agents is one of the most in-demand skills in the job market. This course, available now at https://t.co/zGHUh1loPO, teaches you how.
You'll learn to implement four key agentic design patterns:
- Reflection, in which an agent examines its own output and figures out how to improve it
- Tool use, in which an LLM-driven application decides which functions to call to carry out web search, access calendars, send email, write code, etc.
- Planning, where you'll use an LLM to decide how to break down a task into sub-tasks for execution, and
- Multi-agent collaboration, in which you build multiple specialized agents — much like how a company might hire multiple employees — to perform a complex task
You'll also learn to take a complex application and systematically decompose it into a sequence of tasks to implement using these design patterns.
But here's what I think is the most important part of this course: Having worked with many teams on AI agents, I've found that the single biggest predictor of whether someone executes well is their ability to drive a disciplined process for evals and error analysis. In this course, you'll learn how to do this, so you can efficiently home in on which components to improve in a complex agentic workflow. Instead of guessing what to work on, you'll let evals data guide you. This will put you significantly ahead of the game compared to the vast majority of teams building agents.
Together, we'll build a deep research agent that searches, synthesizes, and reports, using all of these agentic design patterns and best practices.
This self-paced course is taught in a vendor neutral way, using raw Python - without hiding details in a framework. You'll see how each step works, and learn the core concepts that you can then implement using any popular agentic AI framework, or using no framework. The only prerequisite is familiarity with Python, though knowing a bit about LLMs helps.
Come join me, and let's build some agentic AI systems!
Sign up to get started: https://t.co/FX35dloqw4
@LakshyAAAgrawal@hammer_mt How can I get the lm_usage i.e., num tokens consumed during training? I believe there is something like get_lm_usage?
Setting dspy.settings.configure(track_usage=True) is resulting in an error and I saw a fix on git. I believe that's for the next release.
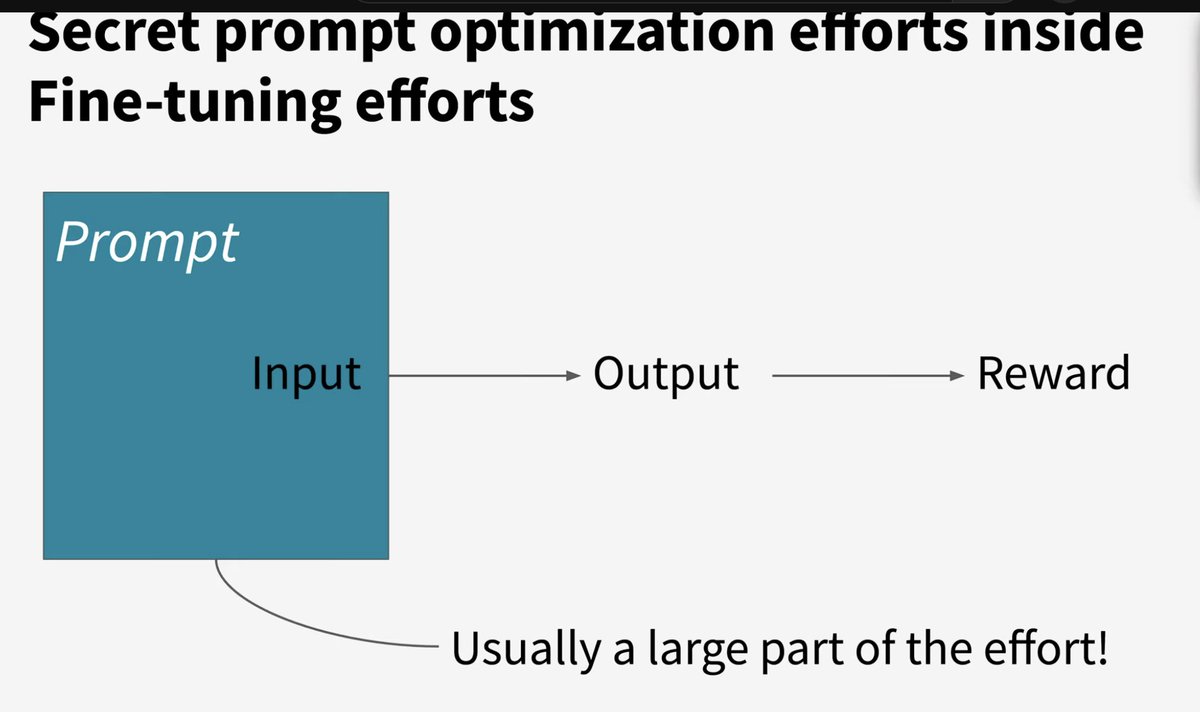
DSPy-ians may disagree, but I don’t think automatic prompt optimization is the real killer feature of DSPy.
For me, the most important value proposition is the speed of experimentation it enables and I’m convinced that this will further increase (as dspy gets even better). Faster experimentation leads to better AI programs.
With DSPy, most changes take a single line of code: swap instructions, tweak outputs requirements, adjust few-shot demos (manually or automatically), finetune weights, turn a program into an agent with Python tools, switch models, change prompt templates (adapters), try model merging, majority voting, ensembling, and more.
Here’s a recent run:
With Llama 4 Scout:
1. Naive prompt → 2/11
2. DSPy naive program → 2/11
3. DSPy instruction optimization → 6/11
4. Add few-shot examples to (3) → 6/11 (no improvement)
5. Optimized program with chain of thought → 7/11
6. Optimized program with tools → 7/11
Switched to Gemini 2.5 Pro:
7. Optimized program with chain of thought → 9/11
8. Add structured outputs (list first) + reasoning, no tools → 11/11 🥳
ps: if I use my naive prompt in step 8, I also get 11/11 the program structure tends to matter most.
After all that I don't have 8 messy script, I have that simple program that I know perform very well. If I wanted I would start 'scanning' to find a model that perform like gemini-2.5-pro but cheaper. I would only change one line and evaluate in a loop!
Just wrapped up my first #KDD2025 in Toronto 🎉
Honored to receive the Young Investigator Best Paper Award for our vision:
"From Medical World Models to Intelligent Digital Twins — A Blue Sky Vision for Proactive Medicine."
Huge thanks to @kdd_news for this incredible recognition and @NIH for the support! 🙏
📢New conference where AI is the primary author and reviewer! https://t.co/lLjAgp7Zmp
Current venues don't allow AI-written papers, so it's hard to assess the +/- of such works🤔 #Agents4Science solicits papers where AI is the main author w/ human advisors.
💡Initial reviews by LLM reviewers w/ final assessment + selection by human experts.
💡Submissions are asked to clearly document AI contribution.
💡All submissions/reviews will be public to enable transparent study of the strength and limitations of AI as researcher and reviewer.
We expect AI will make mistakes and it will be instructive to study these in the open!
Many thanks to the fantastic co-organizers and expert advisory board! Please see the website for more information.
Somehow, the words "reduce the scope" reminded me of the "idea of simplification: stripping the problem of everything except the essentials" from Shannon's easy on creative thinking.
A link to the essay: https://t.co/Z9H6G4IzfY
I’d like to share a tip for getting more practice building with AI — that is, either using AI building blocks to build applications or using AI coding assistance to create powerful applications quickly: If you find yourself with only limited time to build, reduce the scope of your project until you can build something in whatever time you do have.
If you have only an hour, find a small component of an idea that you're excited about that you can build in an hour. With modern coding assistants like Anthropic’s Claude Code (my favorite dev tool right now), you might be surprised at how much you can do even in short periods of time! This gets you going, and you can always continue the project later.
To become good at building with AI, most people must (i) learn relevant techniques, for example by taking online AI courses, and (ii) practice building. I know developers who noodle on ideas for months without actually building anything — I’ve done this too! — because we feel we don’t have time to get started. If you find yourself in this position, I encourage you to keep cutting the initial project scope until you identify a small component you can build right away.
Let me illustrate with an example — one of my many small, fun weekend projects that might never go anywhere, but that I’m glad I did.
Here’s the idea: Many people fear public speaking. And public speaking is challenging to practice, because it's hard to organize an audience. So I thought it would be interesting to build an audience simulator to provide a digital audience of dozens to hundreds of virtual people on a computer monitor and let a user practice by speaking to them.
One Saturday afternoon, I found myself in a coffee shop with a couple of hours to spare and decided to give the audience simulator a shot. My familiarity with graphics coding is limited, so instead of building a complex simulator of a large audience and writing AI software to simulate appropriate audience responses, I decided to cut scope significantly to (a) simulating an audience of one person (which I could replicate later to simulate N persons), (b) omitting AI and letting a human operator manually select the reaction of the simulated audience (similar to Wizard of Oz prototyping), and (c) implementing the graphics using a simple 2D avatar.
Using a mix of several coding assistants, I built a basic version in the time I had. The avatar could move subtly and blink, but otherwise it used basic graphics. Even though it fell far short of a sophisticated audience simulator, I am glad I built this. In addition to moving the project forward and letting me explore different designs, it advanced my knowledge of basic graphics. Further, having this crude prototype to show friends helped me get user feedback that shaped my views on the product idea.
I have on my laptop a list of ideas of things that I think would be interesting to build. Most of them would take much longer than the handful of hours I might have to try something on a given day, but by cutting their scope, I can get going, and the initial progress on a project helps me decide if it’s worth further investment. As a bonus, hacking on a wide variety of applications helps me practice a wide range of skills. But most importantly, this gets an idea out of my head and potentially in front of prospective users for feedback that lets the project move faster.
[Original text: https://t.co/UP6arTWAdV ]
🧵 7/8 Result #4: Catastrophic failure on exact computation ⚠️
Even when we GAVE the solution algorithm (so they just need execute these steps!) to the reasoning models, they still failed at the SAME complexity points. This suggests fundamental limitations in symbolic manipulation, not just problem-solving strategy.
Even more strange is the inconsistency of the search and computation capabilities across different environments and scales. For instance, Claude 3.7 (w. thinking) can correctly do ~100 moves of Tower of Hanoi near perfectly, but fails to explore more than "4 moves" in the River Crossing puzzle or fails earlier when puzzles scale and need longer solutions!
Have you heard the news? MLflow now supports tracking for @DSPyOSS optimization workflows—just like it does for #PyTorch training!
With DSPy, you can automatically optimize your #LLM prompts using powerful optimizers, and now #MLflow is the first and only framework to bring full visibility and observability to that process. ���
Whether you’re tuning prompts or training models, MLflow helps you see what’s happening under the hood, so you can iterate faster and build better.
🚀 Get started today: https://t.co/VOPfykFbAi
🔗 MLflow documentation: https://t.co/plJiuvkHoE
Want to learn more❓ Don’t miss Chen Qian’s @Data_AI_Summit (June 9-12) session “Streamlining DSPy Development: Track, Debug, and Deploy With MLflow” to see how integrating MLflow with DSPy makes it easier than ever to iterate, understand, and productize your #GenAI workflows! 🙌
Learn more about this session ➡️ https://t.co/GP9JBq92yc
#LLMops #PromptEngineering #OpenSourceAI #oss #DSPy






























![AndrewYNg's tweet photo. I’d like to share a tip for getting more practice building with AI — that is, either using AI building blocks to build applications or using AI coding assistance to create powerful applications quickly: If you find yourself with only limited time to build, reduce the scope of your project until you can build something in whatever time you do have.
If you have only an hour, find a small component of an idea that you're excited about that you can build in an hour. With modern coding assistants like Anthropic’s Claude Code (my favorite dev tool right now), you might be surprised at how much you can do even in short periods of time! This gets you going, and you can always continue the project later.
To become good at building with AI, most people must (i) learn relevant techniques, for example by taking online AI courses, and (ii) practice building. I know developers who noodle on ideas for months without actually building anything — I’ve done this too! — because we feel we don’t have time to get started. If you find yourself in this position, I encourage you to keep cutting the initial project scope until you identify a small component you can build right away.
Let me illustrate with an example — one of my many small, fun weekend projects that might never go anywhere, but that I’m glad I did.
Here’s the idea: Many people fear public speaking. And public speaking is challenging to practice, because it's hard to organize an audience. So I thought it would be interesting to build an audience simulator to provide a digital audience of dozens to hundreds of virtual people on a computer monitor and let a user practice by speaking to them.
One Saturday afternoon, I found myself in a coffee shop with a couple of hours to spare and decided to give the audience simulator a shot. My familiarity with graphics coding is limited, so instead of building a complex simulator of a large audience and writing AI software to simulate appropriate audience responses, I decided to cut scope significantly to (a) simulating an audience of one person (which I could replicate later to simulate N persons), (b) omitting AI and letting a human operator manually select the reaction of the simulated audience (similar to Wizard of Oz prototyping), and (c) implementing the graphics using a simple 2D avatar.
Using a mix of several coding assistants, I built a basic version in the time I had. The avatar could move subtly and blink, but otherwise it used basic graphics. Even though it fell far short of a sophisticated audience simulator, I am glad I built this. In addition to moving the project forward and letting me explore different designs, it advanced my knowledge of basic graphics. Further, having this crude prototype to show friends helped me get user feedback that shaped my views on the product idea.
I have on my laptop a list of ideas of things that I think would be interesting to build. Most of them would take much longer than the handful of hours I might have to try something on a given day, but by cutting their scope, I can get going, and the initial progress on a project helps me decide if it’s worth further investment. As a bonus, hacking on a wide variety of applications helps me practice a wide range of skills. But most importantly, this gets an idea out of my head and potentially in front of prospective users for feedback that lets the project move faster.
[Original text: https://t.co/UP6arTWAdV ]](https://pbs.twimg.com/media/Gu7f0T8XYAAQCI9.jpg)





















