Medicine discovers the bitter lesson: frontier LLMs (here GPT 5.2, Opus 4.6, Gemini 3.1) outperform specialized "clinical AI" (e.g. OpenEvidence) in a blind test.
Even funnier that hospital IT are more likely to approve the *specialized* versions despite them being worse.
Les modèles d’intelligence artificielle sont capables d’analyser des données en continu, d’extraire des informations cohérentes à partir de sources multiples et de réaliser des tâches administratives chronophages. Autant d’aptitudes utiles à la médecine qui voit l’IA s’installer, loin de la recherche, au chevet des patientes et des patients.
Si elle s’impose aussi vite, c’est parce que la médecine est devenue un domaine saturé de données. Imagerie, constantes vitales, analyses biologiques, parcours de vie et comptes rendus cliniques composent une information massive et fragmentée. C’est là que l’IA trouve sa place en venant compléter les capacités humaines.
Mais comment développer une IA fiable, souveraine et confidentielle sans qu’elle remplace l’humain pour autant? Deux projets menés à l’UNIGE explorent ce potentiel.
Lire l’article du Journal 👉 https://t.co/jg4BuXxGqw
#IA #médecine #données
AI will create more jobs than any other technology in history.
The doomers' fundamental error isn't just the lump of labor fallacy. It's deeper than that.
They assume a finite problem space.
This is the fundamental error of AI and job doomers. They look at the economy and see a fixed amount of work to be done, a pie that can only be sliced thinner as machines take bigger bites. They see humans a competitive resource for a finite amount of work and a finite amount of problems to solve that must be eliminated.
This is fundamentally, totally and completely wrong.
The pie isn't fixed. It never was. And the reason it isn't fixed is baked into the very nature of technology itself.
Technology is nothing but abstraction stacking. And abstraction stacking is infinite. Therefore the work is infinite.
The hammer didn't reduce the amount of work. It moved the work up the stack. And the new work was more complex, more varied, and more interesting than the old work.
Complexity breeds more complexity and more variety.
Once you have houses instead of mud huts, you have a cascade of new problems that didn't exist before. Plumbing. Wiring. Insulation. Roofing materials that don't rot. Drainage systems so the foundation doesn't flood. Fire codes so your neighbor's bad wiring doesn't burn down the whole block.
Each of those problems becomes a job. A plumber. An electrician. An insulator. A roofer. A civil engineer. A building inspector. None of those jobs existed when we lived in mud huts.
They exist because we solved the mud hut problem.
Think of all of human technological development as a stack of abstraction layers, each one built on top of the ones below it.
At the bottom: raw survival. Finding food. Building shelter. Making fire. These are the base-layer problems.
Each major technology wave solved a base-layer problem and in doing so created an entirely new layer of problems above it:
Agriculture solved "how do we reliably eat?" — and created problems of land ownership, irrigation, crop rotation, storage, trade, taxation, and governance.
Writing solved "how do we remember things across generations?" — and created problems of literacy, education, record-keeping, law, bureaucracy, and literature.
The printing press solved "how do we spread knowledge at scale?" — and created problems of intellectual property, censorship, journalism, publishing, public opinion, and democratic discourse.
The steam engine solved "how do we generate mechanical power without muscles?" — and created problems of factory design, worker safety, urban planning, railroad engineering, coal mining, labor relations, and environmental pollution.
Electricity solved "how do we deliver energy anywhere?" — and created problems of grid design, power generation, appliance manufacturing, electrical safety codes, utility regulation, and an entire consumer electronics industry.
The Internet solved "how do we connect all human knowledge?" — and created problems of cybersecurity, digital privacy, online commerce, content moderation, network infrastructure, cloud computing, social media dynamics, and an entire digital economy that employs tens of millions.
Notice the pattern?
Each solution didn't just solve a problem.
It created an entirely new problem space that was larger, more complex, and more varied than the one it replaced.
The stack grows. It never shrinks.
It's turtles all the way down and all the way up.
🚨 WE ARE HIRING!
The Data Science for Digital Health group @UNIGE is looking for two talented researchers to join our team in Geneva 🇨🇭:
1️⃣ PhD Candidate 2️⃣ Postdoctoral Researcher
Join us to shape the future of #DigitalHealth and #AI! 🧵👇
This #SNSF funded project is a collaboration with Prof. Caroline Samer @HUG.
Our goal is to leverage advanced #NLP & #ML to innovate risk assessment methodologies in clinical trials. 💊🤖
A unique chance to apply code to real-world medical challenges.
📢 PhD opportunity @UNIGEnews & @HEIG_VD! We're seeking a talented student (applied math/theoretical physics background) for a cutting-edge project: Optimizing LLMs for Exceptional Health Situation Management.
Whether you like it or not, the future of AI will not be canned genies controlled by a "safety panel". The future of AI is democratization. Every internet rando will run not just o1, but o8, o9 on their toaster laptop. It's the tide of history that we should surf on, not swim against. Might as well start preparing now.
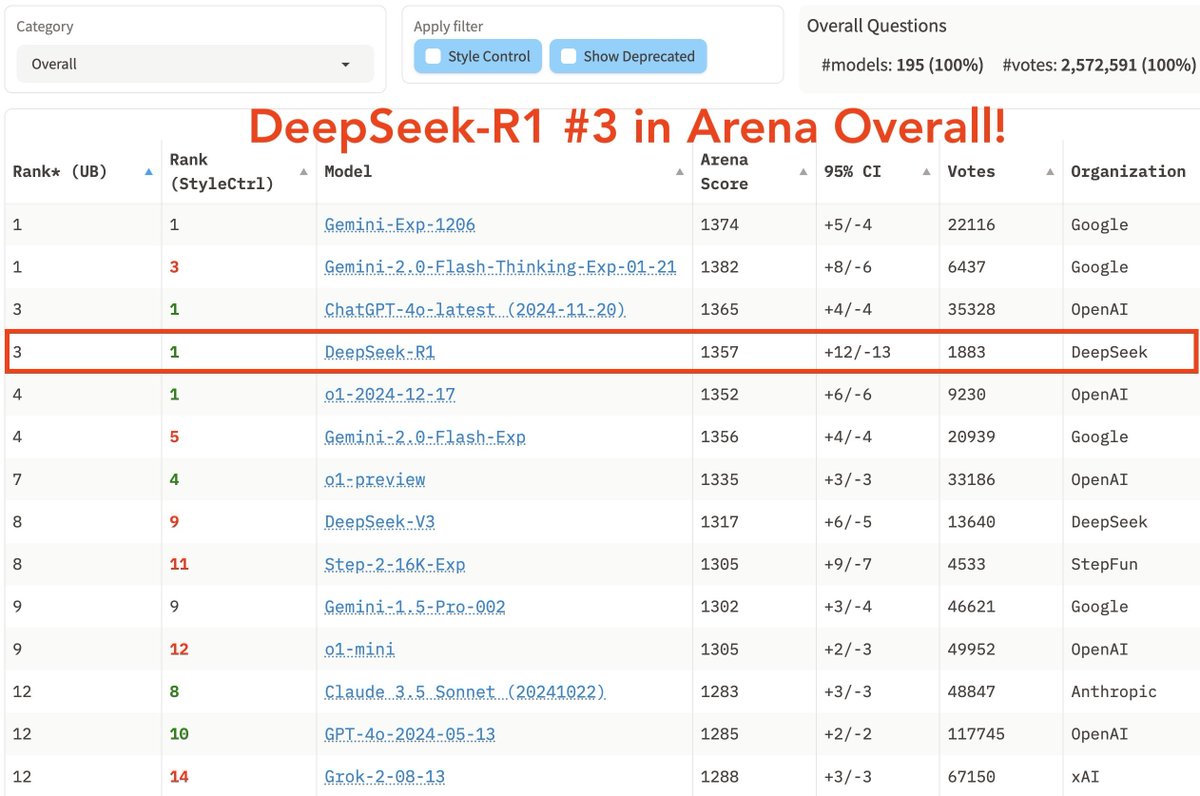
DeepSeek just topped Chatbot Arena, my go-to vibe checker in the wild, and two other independent benchmarks that couldn't be hacked in advance (Artificial-Analysis, HLE).
Last year, there were serious discussions about limiting OSS models by some compute threshold. Turns out it was nothing but our Silicon Valley hubris. It's a humbling wake-up call to us all that open science has no boundary. We need to embrace it, one way or another.
Many tech folks are panicking about how much DeepSeek is able to show with so little compute budget. I see it differently - with a huge smile on my face. Why are we not happy to see *improvements* in the scaling law? DeepSeek is unequivocal proof that one can produce unit intelligence gain at 10x less cost, which means we shall get 10x more powerful AI with the compute we have today and are building tomorrow. Simple math! The AI timeline just got compressed.
Here's my 2025 New Year resolution for the community:
No more AGI/ASI urban myth spreading.
No more fearmongering.
Put our heads down and grind on code.
Open source, as much as you can.
Acceleration is the only way forward.
📢 Join our Data Science for Digital Health group @UNIGEnews ! We're hiring a PhD, Postdoc & Research Associate to work on cutting-edge ML in healthcare: infectious disease risk, AI for emergency medicine & clinical trial safety. Apply now!
Pour les gens qui parlent français et qui sont du côté de Genève. @ylecun donnera un exposé vendredi prochain (11 octobre) à 18h30.
"Comment les machines pourraient-elles atteindre l'intelligence humaine?"
https://t.co/u98BdWkjXf
We are hiring a postdoctoral researcher in Natural Language Processing at LISN for the European FAIRClinical project. More details: https://t.co/t4U4Cdflbr
The new Ground Truths is on a very concerning @NEJM prospective multicenter study today
2 big firsts:
1. Micro/nano plastics found in majority (58%) of patient carotid artery atherosclerotic plaques
2. Carried a 4.5 fold increased risk of major adverse outcomes
[link in profile]
There're now multiple, very well resourced companies that "can't afford to lose" spending billions to compete to build better LLMs. I expect this competition to go on for years. This is going to great for innovation, and also for everyone building applications on top of LLMs.
Você conhece (e até fala!) palavras em tupi, mas já ouviu outras línguas indígenas brasileiras?
Pois já pode ouvi-las e conhecer seus falantes na 2ª parte do nosso especial: https://t.co/zZ8WSDMsYB
Conheça algumas com @_camillacosta 👇
`Decoding speech perception from non-invasive brain recordings`,
led by the one an only @honualx
is just out in the latest issue of Nature Machine Intelligence:
- open-access paper: https://t.co/1jtpTezQzM
- full training code: https://t.co/Al2alBxeUC
Very proud of SIB’s new website https://t.co/VQ0TMNulP5 with fresh content on our aims, organisation, and impact!
What a long way we have come since SIB’s first website 25 years ago—screenshot below
(Trivia question: what was the « Important Announcement » back in 1998 about?)
📅 Day 2 (Tuesday, Sep. 12) of our event next week promises two captivating keynotes:
🎙️ @mmbronstein on physics-inspired learning on graphs
🎙️ @SteveMacfeely discussing steps towards a global data governance framework
🔗 Explore the full agenda here: https://t.co/PabTL5RvNH























![EricTopol's tweet photo. The new Ground Truths is on a very concerning @NEJM prospective multicenter study today
2 big firsts:
1. Micro/nano plastics found in majority (58%) of patient carotid artery atherosclerotic plaques
2. Carried a 4.5 fold increased risk of major adverse outcomes
[link in profile] https://t.co/wLa93LLKzu](https://pbs.twimg.com/media/GIBV3qxbYAA_G_i.jpg)

































