Drowning in the sea of Discrete Diffusion papers? 🌊
We got you.
Join our Reading Group!
From theory → empirics, and language → molecules — we’ll decode the chaos together 💫
Join the cult—uh, I mean community 😇
👉 Google Group: https://t.co/kV9efqBBTu
(1 / 2)
Discrete Diffusion Tutorial @CVPR tomorrow (Wednesday).
Tutorial name: The Principles of Diffusion Models
Real-Time Continuous & Discrete Diffusion
Location: Colorado Convention Center, Four Seasons 4 - Rooms 301 / 302
Dm me if you'd like to attend it remotely on Zoom.
w/ @JCJesseLai@yukimitsu
📢 June 1 (Mon): ELF: Embedded Language Flows
🤔Unlike their image-domain counterparts, today’s leading diffusion language models (DLMs) primarily operate over discrete tokens.
💡The authors show that continuous DLMs can be made effective with minimal adaptation to the discrete domain. They propose Embedded Language Flows (ELF), a class of diffusion models in continuous embedding space based on continuous-time Flow Matching. Unlike existing DLMs, ELF predominantly stays within the continuous embedding space until the final time step, where it maps to discrete tokens using a shared-weight network.
🔧This formulation makes it straightforward to adapt established techniques from image-domain diffusion models, e.g., classifier-free guidance (CFG).
📈Experiments show that ELF substantially outperforms leading discrete and continuous DLMs, achieving better generation quality with fewer sampling steps. These results suggest that ELF offers a promising path toward effective continuous DLMs.
This Monday, Keya Hu (@HuLillian39250) and Linlu Qiu (@linluqiu) will present their jointly led paper ELF.
📢 June 1 (Mon): ELF: Embedded Language Flows
🤔Unlike their image-domain counterparts, today’s leading diffusion language models (DLMs) primarily operate over discrete tokens.
💡The authors show that continuous DLMs can be made effective with minimal adaptation to the discrete domain. They propose Embedded Language Flows (ELF), a class of diffusion models in continuous embedding space based on continuous-time Flow Matching. Unlike existing DLMs, ELF predominantly stays within the continuous embedding space until the final time step, where it maps to discrete tokens using a shared-weight network.
🔧This formulation makes it straightforward to adapt established techniques from image-domain diffusion models, e.g., classifier-free guidance (CFG).
📈Experiments show that ELF substantially outperforms leading discrete and continuous DLMs, achieving better generation quality with fewer sampling steps. These results suggest that ELF offers a promising path toward effective continuous DLMs.
This Monday, Keya Hu (@HuLillian39250) and Linlu Qiu (@linluqiu) will present their jointly led paper ELF.
Collaborators: Yiyang Lu (@Lyy_iiis), Hanhong Zhao (https://t.co/RVF0H3VcOw), Tianhong Li (https://t.co/R96TYajSe3), Yoon Kim (https://t.co/m5xnoVV3hs), Jacob Andreas (@jacobandreas), Kaiming He (https://t.co/t62JoAhU8s)
Paper link: https://t.co/u3oX5TbxBs
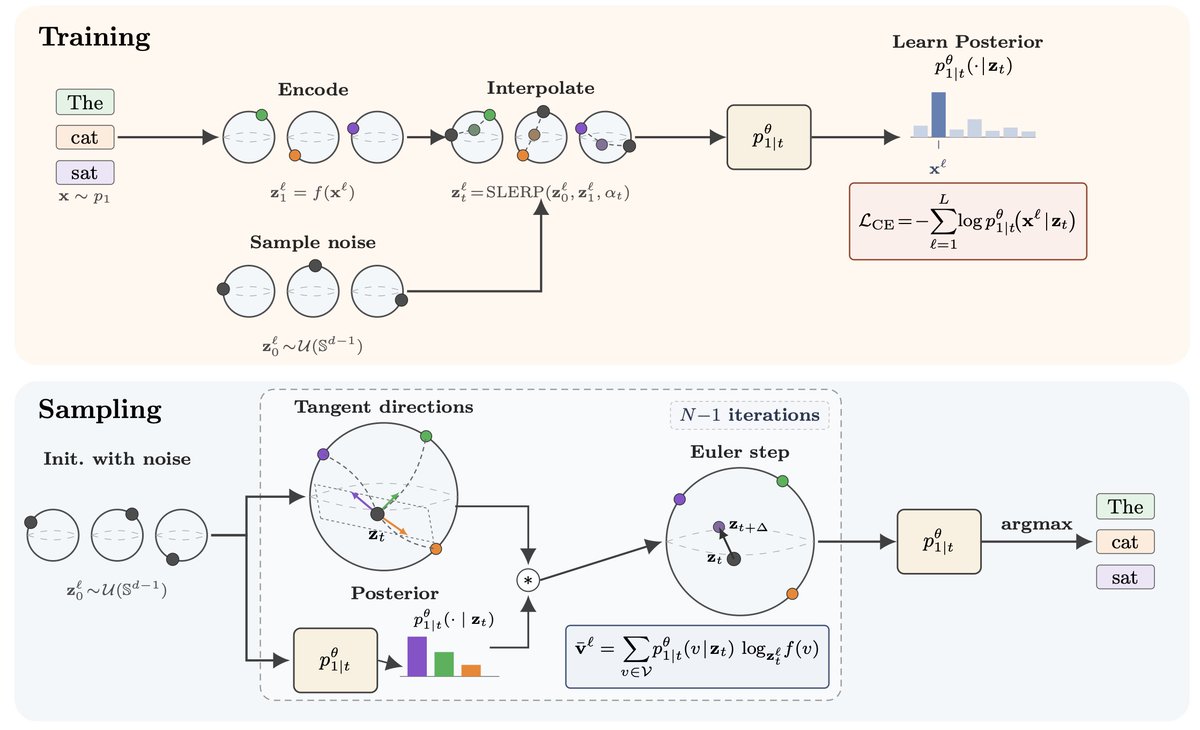
📢 May 25 (Mon): Language Modeling with Spherical Geometry 📷
💡Join us to hear Justin (@jdeschena) and Jannis (@JChemseddine) present their recent work on (Hyper)spherical language modeling!
⚖️Discrete Diffusion and Continuous Flow Language Models (DLMs / FLMs) have emerged as interesting alternatives to autoregressive models. Yet they face fundamental tensions: discrete diffusion samples from a factorized distribution that is strictly less expressive than AR. FLMs avoid factorized sampling but typically add Gaussian noise on one-hot vectors or embeddings. It is far from clear that this kind of noise is well suited to text generation.
🤔Both papers ask the same question: what if the natural geometry for language flows isn't Euclidean space or the probability simplex, but the sphere? The hint has been there for a while: prior work like CDCD (@sedielem et al.) already operates on normalized vectors, and empirically, the cosine distance outperforms the Euclidean one for comparing word embeddings (think of word2vec, GloVe, or retrieval systems).
🧭By lifting tokens onto Sᵈ⁻¹, the authors develop tools for spherical language modeling via SLERP and vMF paths. The vMF path has the added benefit of a closed-form score, enabling principled predictor–corrector samplers on the sphere.
📈 Working with the sphere leads to concrete performance improvements: on code generation with TinyGSM, prior FLMs reach roughly 0% accuracy, while flows on the hypersphere reach 12–18% 🚀. This still lags behind the AR and discrete diffusion baselines, but it strongly suggests that spherical embedding geometry is a natural noise model for tokens. At matched NFE, a properly tuned PC sampler with vMF paths clearly improves the accuracy on Sudoku. And as a bonus, training with rotations avoids materializing one-hot vectors, making it cheaper than standard FLM training⚡️.
🔗 Language Modeling with Hyperspherical Flows: https://t.co/FERfcYZKfZ
🔗 Spherical Flows for Sampling Categorical Data: https://t.co/tKc5EthyIv
🤝 Joint work with Caglar Gulcehre (@caglarml), Gregor Kornhardt (@gregorkornhardt), and Gabriele Steidl (https://t.co/VKLrbhpFVX)
Join our reading group next Monday!
This is especially interesting, as my recent work RePlaid also relies on spherical geometry (length-normalized embeddings)!
Topic: Language Modeling with Spherical Geometry
Presenters: Justin Deschenaux (@jdeschena), Jannis Chemseddine (@JChemseddine)
Did I mention continuous DLMs are back? I think I might have mentioned it before🤔
This one revisits Plaid (https://t.co/aRmOAbZ3pB), a continuous DLM trained with likelihood loss, and rigorously shows how it holds up against a recent discrete method. Pretty well, looks like!
📢 May 25 (Mon): Language Modeling with Spherical Geometry 📷
💡Join us to hear Justin (@jdeschena) and Jannis (@JChemseddine) present their recent work on (Hyper)spherical language modeling!
⚖️Discrete Diffusion and Continuous Flow Language Models (DLMs / FLMs) have emerged as interesting alternatives to autoregressive models. Yet they face fundamental tensions: discrete diffusion samples from a factorized distribution that is strictly less expressive than AR. FLMs avoid factorized sampling but typically add Gaussian noise on one-hot vectors or embeddings. It is far from clear that this kind of noise is well suited to text generation.
🤔Both papers ask the same question: what if the natural geometry for language flows isn't Euclidean space or the probability simplex, but the sphere? The hint has been there for a while: prior work like CDCD (@sedielem et al.) already operates on normalized vectors, and empirically, the cosine distance outperforms the Euclidean one for comparing word embeddings (think of word2vec, GloVe, or retrieval systems).
🧭By lifting tokens onto Sᵈ⁻¹, the authors develop tools for spherical language modeling via SLERP and vMF paths. The vMF path has the added benefit of a closed-form score, enabling principled predictor–corrector samplers on the sphere.
📈 Working with the sphere leads to concrete performance improvements: on code generation with TinyGSM, prior FLMs reach roughly 0% accuracy, while flows on the hypersphere reach 12–18% 🚀. This still lags behind the AR and discrete diffusion baselines, but it strongly suggests that spherical embedding geometry is a natural noise model for tokens. At matched NFE, a properly tuned PC sampler with vMF paths clearly improves the accuracy on Sudoku. And as a bonus, training with rotations avoids materializing one-hot vectors, making it cheaper than standard FLM training⚡️.
🔗 Language Modeling with Hyperspherical Flows: https://t.co/FERfcYZKfZ
🔗 Spherical Flows for Sampling Categorical Data: https://t.co/tKc5EthyIv
🤝 Joint work with Caglar Gulcehre (@caglarml), Gregor Kornhardt (@gregorkornhardt), and Gabriele Steidl (https://t.co/VKLrbhpFVX)
In short: @sedielem and @__ishaan continuous methods for language modeling is competitive with discrete diffusion methods outside the compute-optimal regime.
This matters because frontier LLMs often overtrain smaller models rather than train larger compute-optimal ones, since smaller models are cheaper and faster to serve.
🔥 New paper: Language Modeling with Hyperspherical Flows
Recent flow language models (FLMs) all use Gaussian noise. Makes sense for images, but not necessarily for text 🫠 We propose to add noise by rotating embeddings on 𝕊^{d−1} instead 🌐
w/ @caglarml
(1/9)
📢Excited to share our new paper:
Continuous Diffusion Scales Competitively with Discrete Diffusion for Language
We introduce RePlaid 🌊, a continuous diffusion language model (DLM) with
🏅Discrete likelihood bound
🏅Scaling laws competitive with SOTA discrete DLMs
How? Dive in👇[🧵1/12]
Paper: https://t.co/Q00fmvtHmy
Work done with my amazing collaborators: @WeiGuo01@ShuibaiZ69721@ssahoo_@YongxinChen1@ArashVahdat@MardaniMorteza@jwthickstun
📢 May 18 (Mon): IDLM: Inverse-distilled Diffusion Language Models
🤔Diffusion Language Models (DLMs) have recently achieved strong results in text generation. However, their multi-step sampling leads to slow inference, limiting practical use.
💡To address this, the authors extend Inverse Distillation, a technique originally developed to accelerate continuous diffusion models, to the discrete setting. However, this extension introduces both theoretical and practical challenges.
🔧To overcome these challenges, the authors first provide a theoretical result demonstrating that their inverse formulation admits a unique solution, thereby ensuring valid optimization. They then introduce gradient-stable relaxations to support effective training.
📊As a result, experiments on multiple DLMs show that their method, Inverse-distilled Diffusion Language Models (IDLM), reduces the number of inference steps by 4×—64×, while preserving the teacher model’s entropy and generative perplexity.
This Monday, David Li (https://t.co/8geY1UUQ72) and Nikita Gushchin (https://t.co/L4nc4Gz7ZC) will present their jointly led paper, which was recently accepted at ICML 2026.
Collaborators of this work include: Dmitry Abulkhanov (@dabulkhanov_), Eric Moulines (https://t.co/tK9ctSzw0r), Ivan Oseledets (@oseledetsivan), Maxim Panov (@maxim_panov), Alexander Korotin (https://t.co/RTSk7HAc3v)
Paper link: https://t.co/L8MniD5GBu
📢 May 11 (Mon): Unifying Masked Diffusion Models with Various Generation Orders and Beyond
🤔AR generates left-to-right; masked diffusion generates in any order; and block diffusion generates block-wise left-to-right, with random order within each block. Can we unify all these frameworks and further learn the generation order jointly with token prediction?
💡The authors propose OeMDM, a unified masked diffusion framework that can express various generation orders, and LoMDM, which jointly learns the generation order and the diffusion model.
🔍Everything comes down to the scheduler: by making the forward and reverse schedulers maximally flexible, it becomes possible to describe all generation orders, even learnable generation orders, within the masked diffusion framework.
📈LoMDM achieves SOTA among discrete diffusion models across all benchmarks, and even outperforms block diffusion models, which strongly benefit from left-to-right bias!
This Monday, Chunsan Hong (@ChunsanHong) will present his paper, which received Spotlight at ICML 2026.
Collaborators of this work include: Sanghyun Lee, Jong Chul Ye (https://t.co/ul6KGZ82jG)
Paper link: https://t.co/ClDvJ4FHRG
📢 May 18 (Mon): IDLM: Inverse-distilled Diffusion Language Models
🤔Diffusion Language Models (DLMs) have recently achieved strong results in text generation. However, their multi-step sampling leads to slow inference, limiting practical use.
💡To address this, the authors extend Inverse Distillation, a technique originally developed to accelerate continuous diffusion models, to the discrete setting. However, this extension introduces both theoretical and practical challenges.
🔧To overcome these challenges, the authors first provide a theoretical result demonstrating that their inverse formulation admits a unique solution, thereby ensuring valid optimization. They then introduce gradient-stable relaxations to support effective training.
📊As a result, experiments on multiple DLMs show that their method, Inverse-distilled Diffusion Language Models (IDLM), reduces the number of inference steps by 4×—64×, while preserving the teacher model’s entropy and generative perplexity.
This Monday, David Li (https://t.co/8geY1UUQ72) and Nikita Gushchin (https://t.co/L4nc4Gz7ZC) will present their jointly led paper, which was recently accepted at ICML 2026.
Collaborators of this work include: Dmitry Abulkhanov (@dabulkhanov_), Eric Moulines (https://t.co/tK9ctSzw0r), Ivan Oseledets (@oseledetsivan), Maxim Panov (@maxim_panov), Alexander Korotin (https://t.co/RTSk7HAc3v)
Paper link: https://t.co/L8MniD5GBu






















![zhihanyang_'s tweet photo. 📢Excited to share our new paper:
Continuous Diffusion Scales Competitively with Discrete Diffusion for Language
We introduce RePlaid 🌊, a continuous diffusion language model (DLM) with
🏅Discrete likelihood bound
🏅Scaling laws competitive with SOTA discrete DLMs
How? Dive in👇[🧵1/12]
Paper: https://t.co/Q00fmvtHmy
Work done with my amazing collaborators: @WeiGuo01 @ShuibaiZ69721 @ssahoo_ @YongxinChen1 @ArashVahdat @MardaniMorteza @jwthickstun](https://pbs.twimg.com/media/HIpwk2wXkAA7ebW.jpg)





















