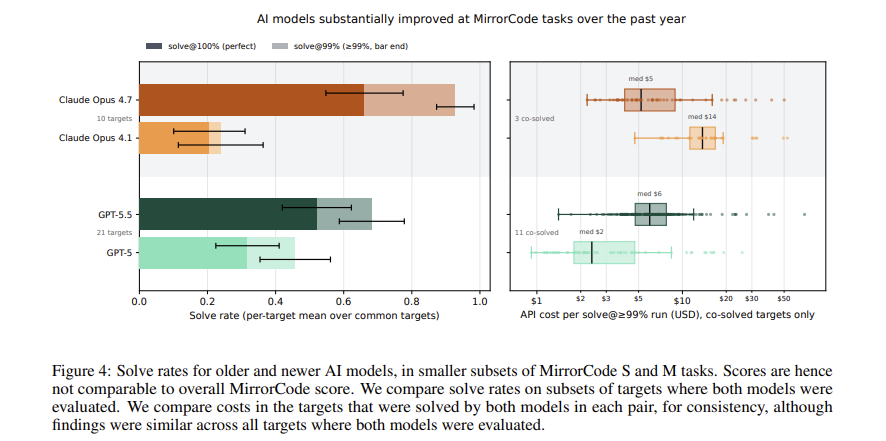
Great experiment testing how good AIs are getting at very ambitious end-to-end coding tasks. Opus 4.7, in 14 hours, was able to build a software package that would take 2-17 weeks of human engineering work. It cost $251.
The models are still not perfect, but are improving fast.
@kiranshaw Fair point but in Covid we didn’t have much long term data on mRNA …and yes it’s kind of vanity now but the emotional impact of it’s positive effects are profound for ppl who use it. I am sure we will figure out solutions to the adverse effects as well soon.
Imagine telling someone in 1999…
The year is 2026.
The President is Donald Trump in his second non consecutive term.
The richest man in the world is PayPal cofounder Elon Musk… but not because of fintech or Paypal. Because of rockets, electric cars, AI, satellites, brain chips and something called “Boring Company”.
Apple is worth trillions but its main business isn’t computers… its selling glass rectangles everyone stares at for 9 hours a day.
People don’t watch TV. They watch teenagers explain geopolitics, finance, and relationship advice in ~60 second videos.
The biggest taxi company owns no taxis.
The biggest hotel company owns no hotels.
The most powerful media companies are social networks where everyone argues with strangers for free.
Kids are making millions filming themselves playing video games.
AI Robots write emails, code, legal memos, songs, essays, and breakup texts.
The internet is mostly bots arguing with humans who are trying to prove they aren’t bots.
You can summon a car, groceries, a doctor, a date, a private jet, or a dog walker from your phone.
People pay real money for invisible currencies, digital monkeys, AI girlfriends and pictures that disappear after 24 hours.
The richest companies in the world don’t sell oil, steel, or cars. They sell attention, compute, data, and addiction.
And somehow, after all of that everyone is still using Excel.
Here's a question I find confusing and interesting and which actually tells us a lot about the nature of current AI progress:
Why has progress on computer use been so slow? Computer use is so clearly verifiable.
I think the answer is that it is not enough for a domain to be verifiable.
It also has to be very grindable—in the sense that you can run lots of parallel rollouts against a deterministic and replayable simulator.
If you’re trying to make a model better at coding, you can create an environment that has a software repo with some missing feature that you’ve tasked the AIs with creating, and then you have a thousand parallel agents just go at the problem, each with their identical copy of the container.
But this doesn’t work with computer use—at least not trivially. You can’t have a thousand agents go try the same checkout flow on Amazon. Because Andy Jassy will find and detect your bots and shut your ass down.
How would we train an AI to build a business? How would you make an AI that’s really good at winning court cases? Or having a profitable day trading in the markets? Or helping a candidate win an election?
What is the RL environment to make an AI as good at politics as Lyndon Johnson, or as good at building a space launch business as Elon Musk?
The rollout requires interacting with the world and cannot be recreated simply within the datacenter. And the outer loop verification may take months or years of real world actions to elicit, and cannot be re-observed by perturbing the model’s actions thousands of times in parallel so that you can isolate what exactly the model did that actually worked.
Good new first: Sol is a smart, efficient, and a significant step forward. It is the same price as GPT-5.5. Also launching in the GPT-5.6 family is Terra, with 5.5-level performance at half the price.
Bad news: at the request of the US government, it is launching today in limited preview instead of the open access launch we were planning on. We are working with the government to get to general availability as fast as we can.
I think it is quite reasonable to roll out models--especially as they reach significant new levels of capability--in this way. It fits with our long-held strategy of iterative deployment. But this isn't quite the process that we think is optimal.
Now we will with the government to attempt to get to a transparent, reliable process for early access, and to ensure that as long as our safeguards work as intended we can release widely. We want to be a reliable, dependable partner that works with all stakeholders, and we also want to live by our mission of benefiting all of humanity. I believe the government shares most of our goals, and that they are overall doing a good job in a very difficult situation.
We will work as quickly as we can to get this model in your hands and we hope you will love it.
Conquest's Third Law says that you should model any bureaucratic organisation as if it was controlled by a cabal of its enemies.
It's a fun exaggeration, but it gets at an important phenomenon.
Organisations have continuous generational turnover. The founding members eventually leave and have to be replaced, probably by people only imperfectly aligned with their vision.
With each new hire, the values of the people in the organisation will tend to drift further and further. In the limit they're almost completely unaligned with the founding purpose of the org.
The capability overhang from the models we have today is big enough that large-scale change to work and society over the next 5+ years is now inevitable even if AI development stops.
(And there is no real sign that AI development is slowing down, it appears to be accelerating)
There is no single “correct” path to the top.
Novak Djokovic went 3 years without sugar, let one piece of chocolate melt on his tongue after the longest tennis match ever… then went straight back to training.
Roger Federer won the Australian Open eating ice cream every single night.
George Mack’s point: Djokovic’s extreme discipline vs Federer’s relaxed enjoyment. Stephen King raw-dogging novels vs J.K. Rowling using spreadsheets. Buffett reading everything vs Jim Simons using algorithms.
At the highest level, the winners pick what works for them.
Cool way to use Claude Code: deciphering Linear A, a 3500 year old written language from Crete
https://t.co/Aqd4ZG7Cum
Hope this holds up in peer review! 🤞
I've noticed that one of the most common mistakes ambitious people make is believing that happiness is waiting on the other side of achievement.
In behavioral science, we call this the arrival fallacy. It's the idea that once you reach the next milestone, get the promotion, earn the recognition, or accomplish the goal, you'll finally feel fulfilled.
But satisfaction doesn't come from arriving. It almost always comes from making progress toward something meaningful. That's why goals are important, but they are not the reward. The pursuit is.
"Transformers" by Daniel Jurafsky and James H. Martin is one of the clearest and most mathematically grounded introductions to the Transformer architecture I have ever read.
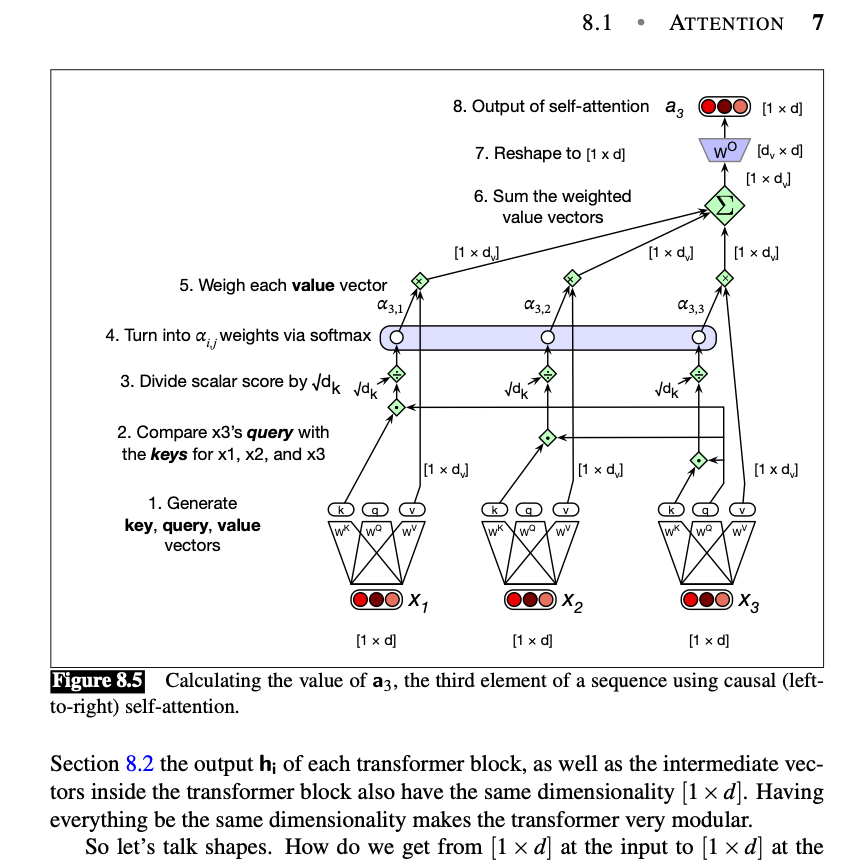
Chapter 8 introduces the Transformer as the standard architecture behind modern large language models. What makes this chapter particularly interesting is its step-by-step presentation of the underlying mechanisms: contextual embeddings, self-attention, query, key and value vectors, scaled dot-product attention, multi-head attention, residual streams, feedforward layers, layer normalization, masking, and the parallel matrix formulation of attention.
In particular, the treatment of attention as a weighted sum of contextual representations is especially valuable. The chapter first develops an intuitive, simplified view of attention and then gradually derives the full formulation using the Q, K, and V matrices. This approach makes it easier to understand what is actually happening inside the architecture from an algebraic and matrix-based perspective, rather than simply viewing the usual block diagrams.
I think it is an excellent resource for anyone interested in understanding how Transformers work from linguistic, mathematical, and computational perspectives.
https://t.co/3fitdPy6Fv
Introducing Brain in Computer.
Brain is a continuously learning memory system. Every task on Computer plugs into a context graph built by Brain.
It makes Computer more stateful with every run.
Available as a research preview for all Perplexity Max subscribers.
New in Claude Code: Artifacts.
Interactive pages built from your session, like a PR walkthrough or a living project dashboard, shared with your team at a private link.
Available in beta on Team and Enterprise plans.
Show Codex a workflow once. Reuse it as a skill.
Record & Replay lets you show Codex a recurring task, like filing an expense report or submitting a time-off request.
Codex turns that demo into an inspectable, editable skill.
You control when recording starts and stops.