Member of Technical Staff @ Open Athena. Creator of Levanter and Marin. Previously Research Engineering @StanfordCRFM, co-founder at Semantic Machines ⟶ MSFT.
Quoting @dlwh : we are at risk of losing the reputation of spiky loss runs!
This run incorporates some stability techniques from my past projects: Hyperball, Gated Norm, and Gated Attention. Excited to see the next run from Marin!
Building momentum at Marin! Upgrading from Dense -> 129B parameter MoEs -> architecture improvements -> optimizer improvements gives our pretraining recipe an estimated 6x cumulative learning speedup, accounting for MFU. Includes community contributions. https://t.co/5dPB9uBiSp
Not only do we want to train a good model, we want to know it'll be good before we even start training.
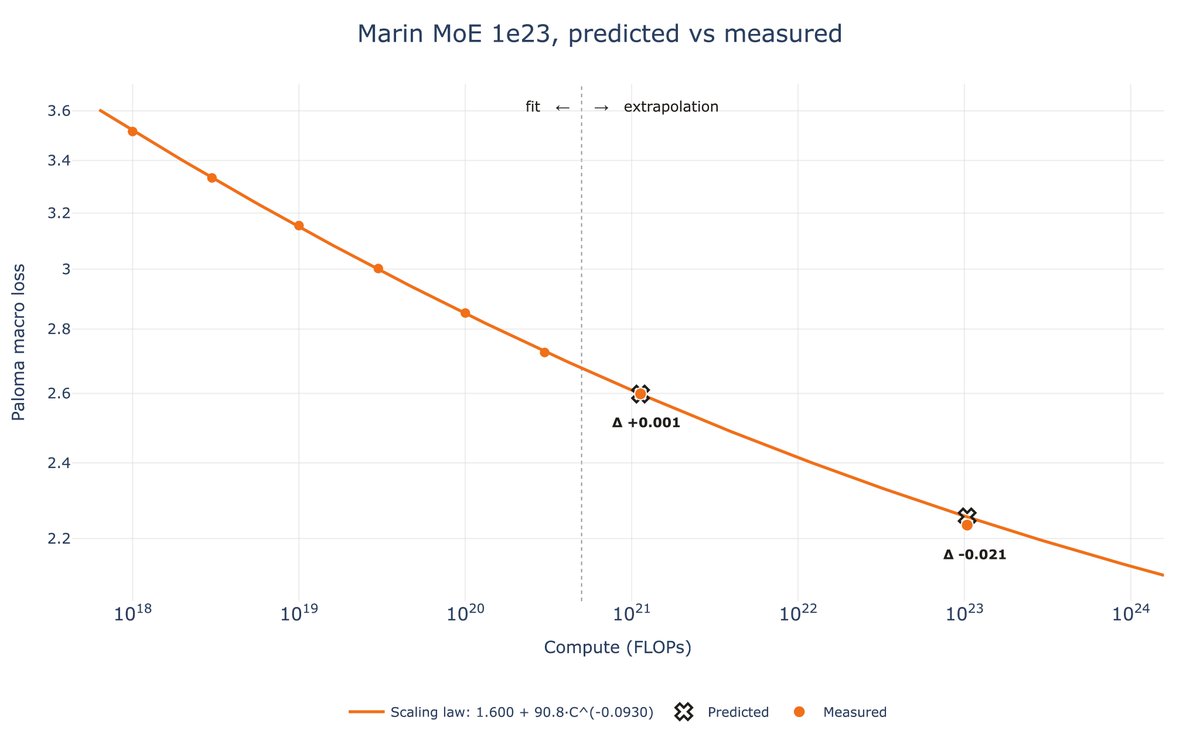
About a month ago, the Marin team launched a 129B (16B active) 1e23 FLOPs MoE run and preregistered a loss of 2.252. The run finished this past week and landed at 2.234.
https://t.co/OptaVa7jIO
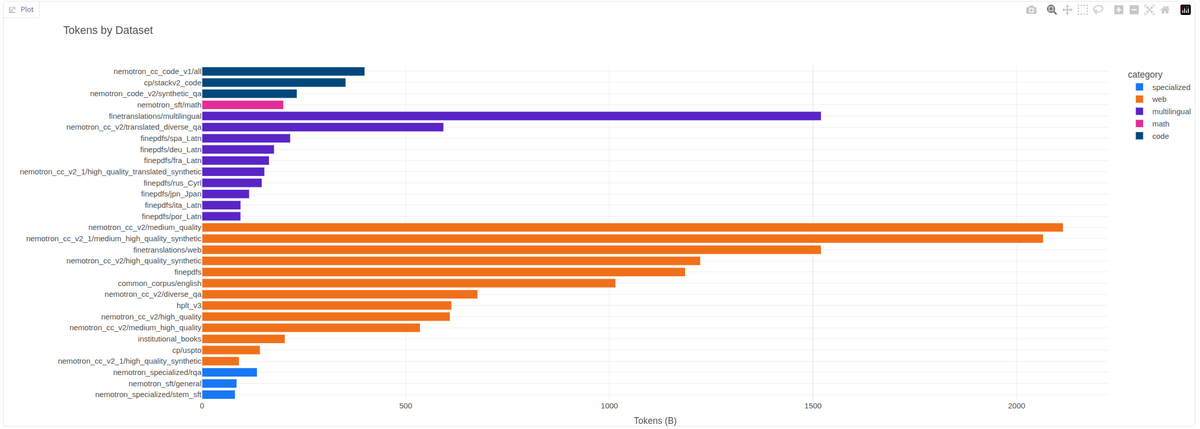
For the next Marin model, we are putting together a new data mix. Currently we have 18T tokens, but could use more. So if you are sitting on some secret stash of high quality tokens, please let us know! Pre-training, mid-training, SFT data all welcome.
Introducing SWE-ZERO-12M-trajectories: the largest agentic trace dataset in the open, 5.7x larger than the previous largest.
112B tokens · 12M trajectories · 122K PRs · 3K repos · 16 languages
https://t.co/aVqCc4J5tr
Also, Will is underselling the blog post. The interactive figures are excellent: they make the scaling intuition concrete, including what transfers and what breaks.
Worth reading https://t.co/Dh5EajzrDr
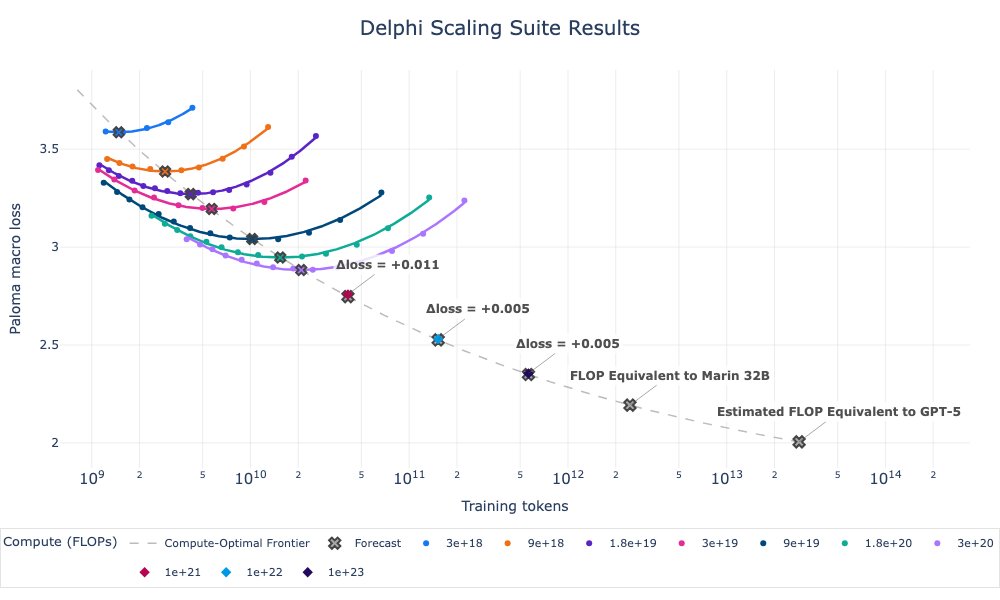
Marin’s Delphi scaling suite is out!
With the right scaling recipe, small runs predicted a 1e23 FLOP run within 0.2%, extrapolating 300× past the largest run in the fit.
To train better open models, we need predictable scaling.
Delphi is Marin’s first step: we pretrained many small models with one recipe, then extrapolated 300× to predict a 25B-param / 600B-token run with just 0.2% error.
Getting there took some work 🧵
Releasing
SpectraX is a JAX-native neural-network library built around true MPMD pipeline parallelism. Each physical rank compiles and runs its own XLA program — no shared shard_map HLO, no SPMD-same-shape constraint. Heterogeneous stages (eg, embed → blocks → head), nine pipeline schedules (GPipe, 1F1B, ZeroBubble, Interleaved, DualPipeV, …), and a unified https://t.co/vYOljO1K4k()/spx.jit() entry point that dispatches to SPMD or MPMD from the same training script.
https://t.co/GWPCsQVUwI
So cool to see that open-source, with open experimentation (and with the help of someone posting blog posts about their personal research), can yield a very robust method for MoE balancing. This method seems more elegant than all other methods I have seen. Open source is Awesome!
Researchers' brilliant ideas often get lost in the sea of endless SOTA claims on weak baselines. At Marin we battle-test ideas in an open arena, where anyone's idea can be promoted to the next hero run. One that recently rose up was @Jianlin_S MoE Quantile Balancing, used in our last 1e22 and ongoing 130B run. Animated visuals of how QB performed are available in the OpenAthena blog. https://t.co/BDSsonuNH7
Lots more to do! MoEs are next, and we think the curve bending and loss spikes at the higher scales may be related (even though the lower scale runs were spike free)
Marin Delphi is finished! Will et al produced a stable scaling formula that yielded results almost exactly in line with predictions, at 1% the flop budget (and we suspect we can do somewhat less now)
How far do Marin's scaling laws extrapolate? At least 100x, apparently!
Despite spooky spikes, our 1e23 Delphi finished on forecast. The compute-optimal ladder costs ~1e21 FLOPs to train. Good scaling science lets you “run” this (not tiny) experiment at 1/100th the cost.
@MatharyCharles this one has qk-norm and adamh (hyperball constraint on weight norms). I think the LR is just too hot (and some data issues). no z-loss I think
Our 1e23 "Delphi" (~25B param model trained for ~600B tokens) run for Marin has entered its learning rate decay phase.
Lots of spikes at this scale, very scary! Despite that, the run is looking on track to be close to our pre-registered scaling laws predictions. Stay tuned...
@WilliamBarrHeld has pointed out that we started hitting spikes with the 1e23 at around the same loss value as where 1e22 saw some spikes. Probably the WSD LR stays too hot too long.