Second for second, @tylercowen packs more substance into a talk than anyone I'm aware of. This is a clear, non-hysterical, and somewhat soothing discussion of our AI future.
Very excited to share our interview with @polynoamial on AI for math — the Erdős unit distance problem, saturating the IMO, the future of math research, and more!
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Three days left to apply for the Financial Literacy Research Boot Camp at @Stanford .
If you're an early-career researcher in economics, finance, personal finance or a related field, I hope you'll consider applying.
This five-day, full-immersion workshop is one of the ways the Stanford Initiative for Financial Decision-Making is working to build the next generation of financial literacy researchers.
Space is limited. The application deadline is April 30, 2026. For full details and instructions, visit: https://t.co/52JzshWSgU
Most economists lack the tech setup to fully leverage AI (e.g. Docker container w/ R for Claude Code in yolo mode). You can see my setup + instructions in the `ralph-wiggum-asset-pricing` repo 🧵
I've revised the AI-generated "Hedging the Singularity" paper and algo. My goal was "human as Clockmaker": I set up the agentic loop, and then AI generates a paper good enough to put my name on it.
I couldn't get there. It was both disappointing and relieving. 🧵
I’m organizing the Econometric Society Summer School in Structural Estimation. Broader than the summer school with Luke Tayolor: more methods (not just SMM), more topics. Tell your students to apply! Deadline: April 15.
https://t.co/y5CYcAeZNk
Inspired by @karpathy's post on LLM knowledge bases, and in preparation for a talk on using AI in business research at @SmealCollege, I spent a few hours on Claude Code putting together a knowledge base on the topic. Sharing in case anyone finds it useful:
https://t.co/BSIl42hZXD
It's kind of funny that Nature is publishing misleading clickbait, where the clickbaity lead is "look you can't trust anything in Nature!!"
I wish it was an April Fool's joke, but I'm afraid this is sincere.
Clicking through, there are several replication exercises, and all except one have success well over 50%.
Why do this? Why undermine your own institution for clicks? It boggles the mind.
It was a privilege to celebrate Pete Kyle 1985 seminal work at the "The Kyle '85 Conference: Market Structure, Liquidity, and Asset Pricing" at the University of Maryland this week. Pete is a true giant in finance research! The program:
https://t.co/VWCy1hP9eU
@malcolmwardlaw@NainsiDwiv50980 I was excited about this package but my test results were disappointing, I'll stick with Mistdal OCR, which has been consistently great.
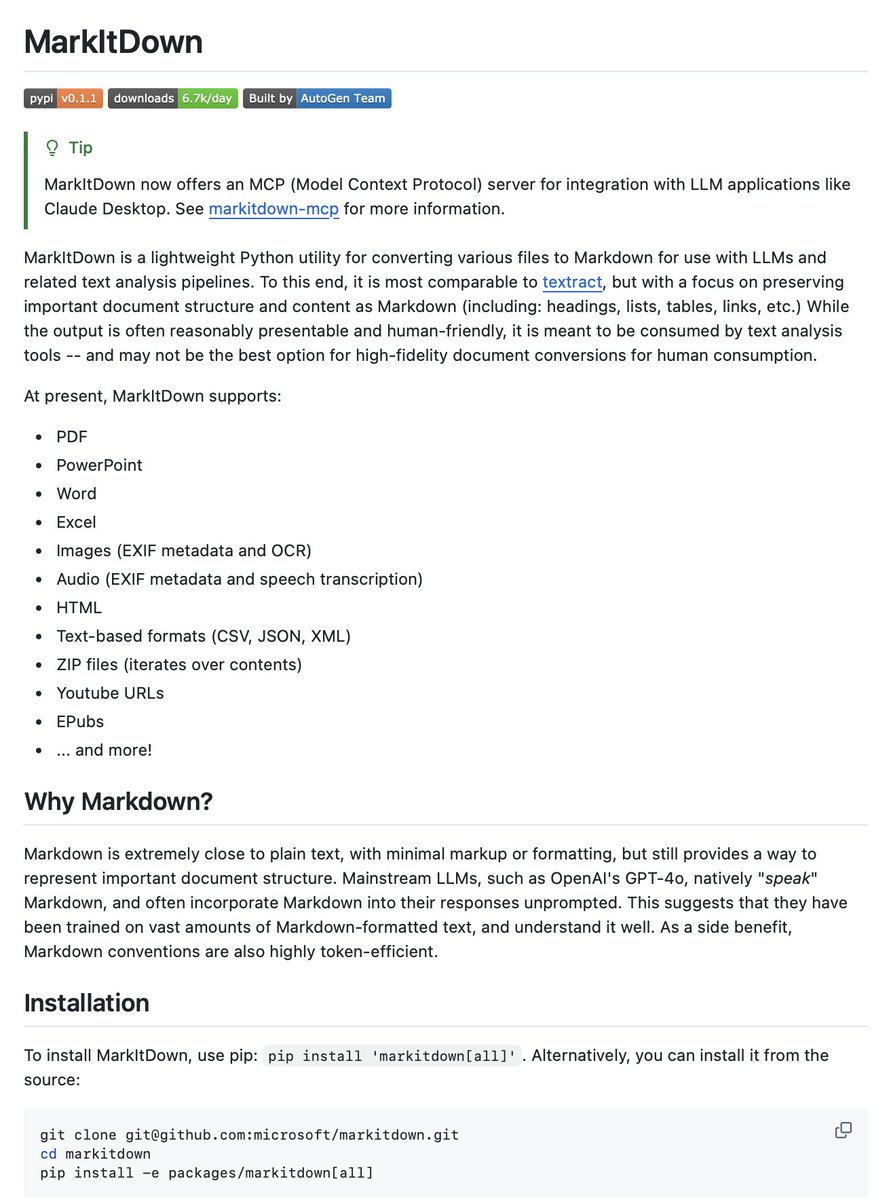
Microsoft just changed the game 🤯
They open-sourced a tool that converts literally any file into clean markdown for LLMs in under 60 seconds.
- Converts 10+ file formats out of the box.
- Run via command line, Python API, or Docker.
- Built-in MCP server for direct Claude Desktop integration.
100% open source.
Link in comments 👇
@ProfStefanNagel Yes, it's getting worse. I just assume I'm not getting money back for 1 in 5 invited seminars. Typically due to lengthy forms or incompetent admin.