Some new results I found surprising that I’m tweeting for Chris (who isnt on here). With enough compute, the best data filter for LMs (on DCLM) might be no filter. Why? Large models can tolerate a surprising amount of nominally 'low quality' data, and can sometimes even benefit.
If you're doing applied AI research (especially system design, benchmarks, evals, efficiency, or ops) you should be submitting to the Conference on AI and Agentic Systems... https://t.co/xGRBKOqXgJ
🧵(4/6) 𝐑𝐞𝐚𝐥-𝐰𝐨𝐫𝐥𝐝 𝐈𝐦𝐩𝐚𝐜𝐭. TGPT achieves a significant improvement over a production model on transaction classification. TGPT excels at generating realistic future transaction trajectories, opening up new avenues for forecasting and personalization.
🧵(3/6) 3𝐃-𝐓𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐞𝐫 𝐀𝐫𝐜𝐡𝐢𝐭𝐞𝐜𝐭𝐮𝐫𝐞. We design a new architecture, specifically to model and fuse the complex, multi-modal nature of transaction data. This approach hierarchically encodes transaction features, individual transactions, and their sequences.
🧵(4/6) 𝐑𝐞𝐚𝐥-𝐰𝐨𝐫𝐥𝐝 𝐈𝐦𝐩𝐚𝐜𝐭. TGPT achieves a significant improvement over a production model on transaction classification. TGPT excels at generating realistic future transaction trajectories, opening up new avenues for forecasting and personalization.
🧵(3/6) 3𝐃-𝐓𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐞𝐫 𝐀𝐫𝐜𝐡𝐢𝐭𝐞𝐜𝐭𝐮𝐫𝐞. We design a new architecture, specifically to model and fuse the complex, multi-modal nature of transaction data. This approach hierarchically encodes transaction features, individual transactions, and their sequences.
Introducing Eigent — the first multi-agent workforce on your desktop.
Eigent is a team of AI agents collaborating to complete complex tasks in parallel. It is your long-term working partner with fullly customizable workers and MCPs.
Public beta available to download for MacOS, Windows. 100% open-source on Github. Comment for 500 extra credits.
📣 Our spicy ICML 2025 position paper: “Graph Learning Will Lose Relevance Due To Poor Benchmarks”.
Graph learning is less trendy in the ML world than it was in 2020-2022. We believe the problem is in poor benchmarks that hold the field back - and suggest ways to fix it!
🧵1/10
Visa President of Technology Rajat Taneja rebuilt the company’s data platform from scratch, helping position it for the generative AI boom. https://t.co/fJ6NUr4ccW
There is a lot of unconscious emphasis of the DeepSeek model being “Chinese” and implicit connection with the Sino-US relationship or the GPU power.
In my eyes, the success of DeepSeek has little to do with that. It is simple intelligence and pragmatism at work: given a limit of computation and manpower present, produce the best outcome with smart research. Same with the AlexNet model when Alex Krizhevsky needed to make magic with 2 GPUs, and not a supercluster.
There are a lot of super smart AI people and companies in the world. In terms of the Chinese ethnic group, people I had the privilege to have worked with include (but are not limited to)
- Kaiming He who is the OG of modern computer vision.
- Song Han who founded DeePhi, OmniML and now professor at MIT.
- the DMLC folks who created early frameworks like MxNet and TVM.
- Bing Xu who did MxNet, was coauthor of GAN, founded HippoML and is now at NVidia.
- Orbeus, a startup on early CV applications and now the foundation of AWS ReKognition.
And many more. They ace in the frontier of AI, whether it’s research, product, small startups, or big companies.
AI should bring us closer rather than more separate. I was saddened by the discriminative comments given by Professor Rosalind Picard at NeurIPS, but was too busy to put my thoughts together and say something. Looking back at 2024, I think what really stood out is the fundamental seek for AI breakthrough - collect what we have, use our brain, and achieve our best. It’s like the Olympics: faster, higher, stronger, together.
How far is an LLM from not only understanding but also generating visually?
Not very far!
Introducing MetaMorph---a multimodal understanding and generation model.
In MetaMorph, understanding and generation benefit each other. Very moderate generation data is needed to elicit visual generation from an LLM, when trained jointly with visual understanding.
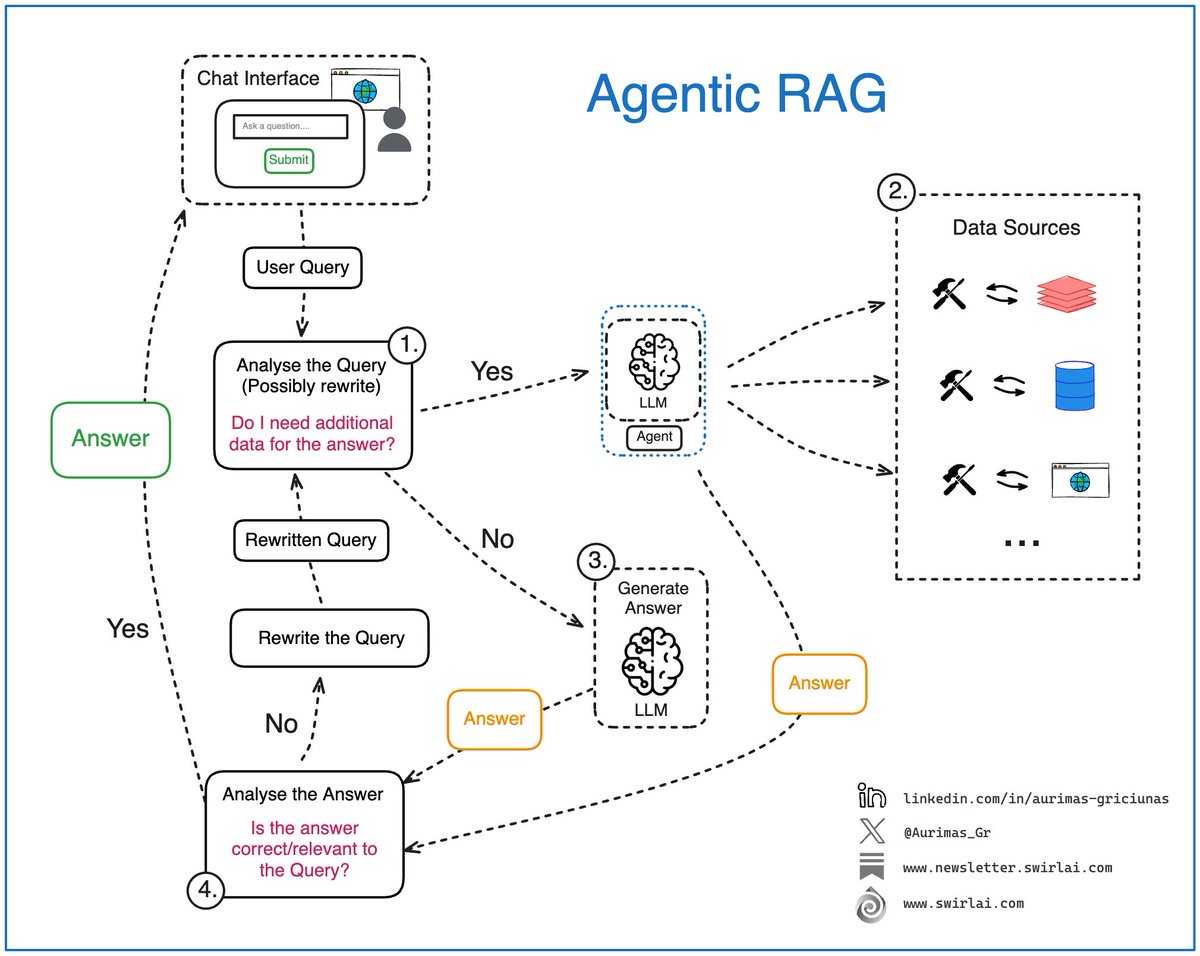
What is 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚?
In real world applications, simple naive RAG systems are rarely used nowadays. To provide correct answers to a user query, we are always adding some agency to the RAG system.
However, it is important to 𝗻𝗼𝘁 𝗴𝗲𝘁 𝗹𝗼𝘀𝘁 𝗶𝗻 𝘁𝗵𝗲 𝗯𝘂𝘇𝘇 𝗮𝗻𝗱 𝘁𝗲𝗿𝗺𝗶𝗻𝗼𝗹𝗼𝗴𝘆 and understand that there is 𝗻𝗼 𝘀𝗶𝗻𝗴𝗹𝗲 𝗯𝗹𝘂𝗲𝗽𝗿𝗶𝗻𝘁 to add the mentioned agency to your RAG system and you should adapt to your use case. My advice is to not get stuck on terminology and think about engineering flows.
Let’s explore some of the moving pieces in Agentic RAG:
𝟭. Analysis of the user query: we pass the original user query to a LLM based Agent for analysis. This is where:
➡️ The original query can be rewritten, sometimes multiple times to create either a single or multiple queries to be passed down the pipeline.
➡️ The agent decides if additional data sources are required to answer the query.
𝟮. If additional data is required, the Retrieval step is triggered. In Agentic RAG case, we could have a single or multiple agents responsible for figuring out what data sources should be tapped into, few examples:
➡️ Real time user data. This is a pretty cool concept as we might have some real time information like current location available for the user.
➡️ Internal documents that a user might be interested in.
➡️ Data available on the web.
➡️ …
𝟯. If there is no need for additional data, we try to compose the answer (or multiple answers) straight via an LLM.
𝟰. The answer (or answers) get analyzed, summarized and evaluated for correctness and relevance:
➡️ If the Agent decides that the answer is good enough, it gets returned to the user.
➡️ If the Agent decides that the answer needs improvement, we try to rewrite the usr query and repeat the generation loop.
The real power of Agentic RAG lies in its ability to perform additional routing pre and post generation, handle multiple distinct data sources for retrieval if it is needed and recover from failures in generating correct answers.
What are your thoughts on Agentic RAG? Let me know in the comments! 👇
#RAG #LLM #AI
I am hiring a research intern, working LLM (Llama 3+) safety. The internship is expected to start in Summer/Spring 2025, based in New York City. Please drop me an email at [email protected] (Subject starts with "[2025 Intern]")
Learn more here: https://t.co/hpeYKwP0nG
Respectfully disagree. It's the structure of language and words that make LLMs effective. Pure speech, time series, or video without linguistic co-supervision don't yield the same results. Language provides the minimal conceptual units that enable these models to work.
Excited to share Just read twice: going beyond causal language modeling to close quality gaps between efficient recurrent models and attention-based models!!
There’s so much recent progress on recurrent architectures, which are dramatically more memory efficient and asymptotically faster than attention 💨 But there’s no free lunch 🥪 these models can’t fit all the information from long contexts into the limited memory, degrading in-context learning quality. Is all lost?