A Survey of Large Language Models for Text-Guided Molecular Discovery: from Molecule Generation to Optimization
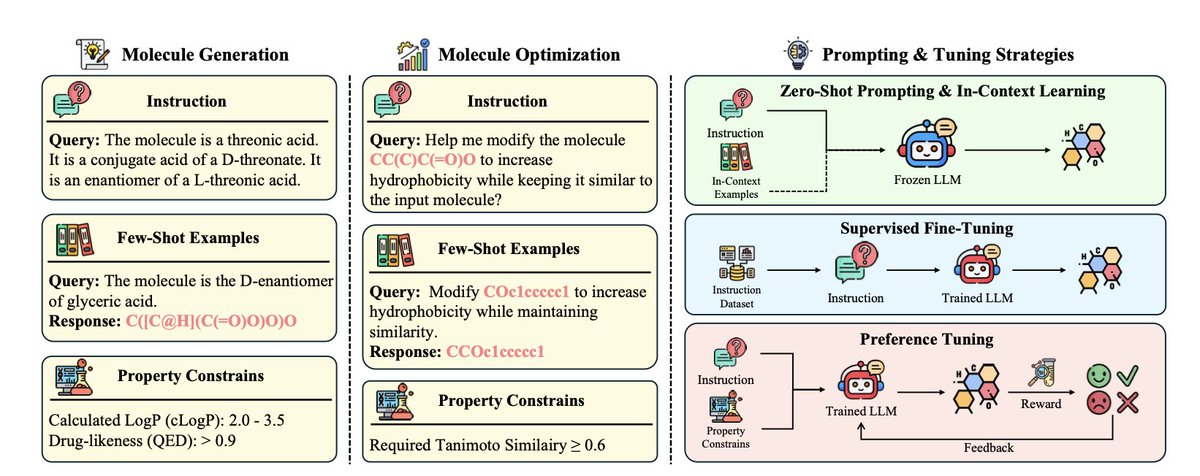
1.This is the first focused survey on using large language models (LLMs) for molecule generation and optimization, introducing a novel taxonomy based on learning paradigms—covering both tuning-free (e.g., zero-shot, in-context learning) and tuning-based (e.g., supervised fine-tuning, preference tuning) methods.
2.The survey highlights how LLMs are uniquely positioned for molecular discovery due to their emergent capabilities—such as in-context learning, reasoning, and instruction following—which allow them to generalize across diverse chemical tasks without task-specific retraining.
3.In molecule generation, LLMs are deployed via prompting strategies (e.g., LLM4GraphGen, MolReGPT) or adapted through supervised datasets (e.g., Mol-Instructions, LlaSMol, ChatMol). Preference-tuned models like SmileyLlama and Mol-MoE show improved fidelity to molecular constraints.
4.For molecule optimization, the review examines how LLMs refine existing molecules through goal-directed editing. Strategies include zero-shot optimization (LLM-MDE), retrieval-augmented prompting (ChatDrug), and evolution-based in-context learning (MOLLM, LLM-EO).
5.The survey identifies a trend toward hybrid frameworks combining fine-tuned worker models with external reasoning agents (e.g., MultiMol, DrugAssist), often leveraging GPT-4o or domain-specific scoring functions to enhance candidate selection and validation.
6.Multi-modal modeling is a growing focus, with models like UniMoT and Molx-Enhanced LLM incorporating graph or 3D inputs into LLMs via specialized tokenizers and embedding schemes, enabling structurally-aware generation and optimization.
7.Benchmarking frameworks are categorized into structure-based (validity, uniqueness, diversity) and property-based (LogP, QED, synthetic accessibility, Pareto-optimality) metrics. The paper also provides a detailed summary of standard datasets for pretraining and evaluation.
8.The survey emphasizes the limitations of current LLMs: hallucinations, lack of transparency, and domain-incoherent outputs. Future work should prioritize trustworthy generation, interpretability, and error-aware prompting to enhance reliability.
9.Emerging directions include LLM-driven agent frameworks that integrate external tools (e.g., retrosynthesis engines, docking software) for iterative design, as well as cross-modal models that jointly encode chemical topology, text, and spatial information.
10.A continuously updated repository of LLM-centric molecular research is provided at github, making this survey a central resource for the field.
💻Code: https://t.co/UxjZHjKwSK
📜Paper: https://t.co/DxzJMudNWX
#LLM #MoleculeGeneration #MolecularOptimization #DrugDiscovery #ChemLLM #AI4Science #InContextLearning #SMILES #MolecularDesign #LargeLanguageModels
📣 We are seeking exceptional postdoctoral candidates on AI4Health at Northwestern University! Please share with anyone who might be interested in this exciting opportunity! #Postdoc#AI4Health#ML#AI#LLM#MedicalAI#Northwestern
🚨 Call for Workshop Papers at #KDD2024 🚨
Submit your paper to the KDD’24 Workshop on Resource-Efficient Learning for Knowledge Discovery
📆 June 30
https://t.co/bhRQN0vwmx
***Internship Opportunity***
We're hiring interns.
Come, join us in building an ML platform reinvented for real-time. You'll gain hands-on experience in building ML systems from the ground up.
💸 Stipend: ₹1L/month
🗓️ Start Date: May/June 2024
📍 Location: Virtual
🚀 Career Path: We'll roll out PPOs to top performers
Open Roles:
1. ML
2. Infra
3. DevOps
4. Streaming Systems
5. UI/UX
If you're interested, please fill out this form:
https://t.co/mz64pL6xW9
#internship #hiring
We heard that you missed the benefits of the standard registration.
Don't worry, the deadline has been extended to February 18th.
Register today:
https://t.co/PX75CIVcvW
#WSDM2024#WSDMCUP2024#sigkdd#sigmod#sigir#sigweb#acm
📢 Interested in statistical machine learning and data science? Don't forget to submit your application to our Ph.D. program before Jan 5th!
Details can be found at: https://t.co/m0gbMQBCG4
If you are also attending NeurIPS, feel free to talk to me!
#WSDM2024 is open for registration. Make sure to grab your spot soon. Early registration ends December 17th! Come learn from industry and academia experts such as @Google's VP Elizabeth Hamon Reid from and Nicolas Cristin (@nc2y). Register now at https://t.co/PX75CIVcvW
🎉 Exciting News! 📢 Our paper on "GRENADE: Graph-Centric Language Model for Self-Supervised Representation Learning on Text-Attributed Graphs" has been accepted at #EMNLP findings! 📚🔍
Thanks for the co-authors @kaize0409, Kyumin Lee.
State tuned for the preprint and code.
Working with Prof. Liu and Prof. Wang (my former phd and visiting phd students) to organize a special issue on Data Centric AI. Mathematics is a very decent journal. We are looking forward to your discussions on such interesting topics.
We are pleased to announce the call for Workshop Proposals for the #WSDM2024, which will take place for the first time in LATAM at Mérida, México
https://t.co/m4o3NhPfh2
Proposals Due: October 5, 2023
Acceptance Notifications: November 2, 2023
Happy to chat about research if you are around! Also, I'm recruiting students to join my group at Northwestern University. Let me know if you are interested!
Heading to Long Beach for KDD'23! This time I will present our recent work "Learning Strong Graph Neural Networks with Weak Information". If you are interested in data-efficient graph learning, you are welcome to join the oral and poster sessions!