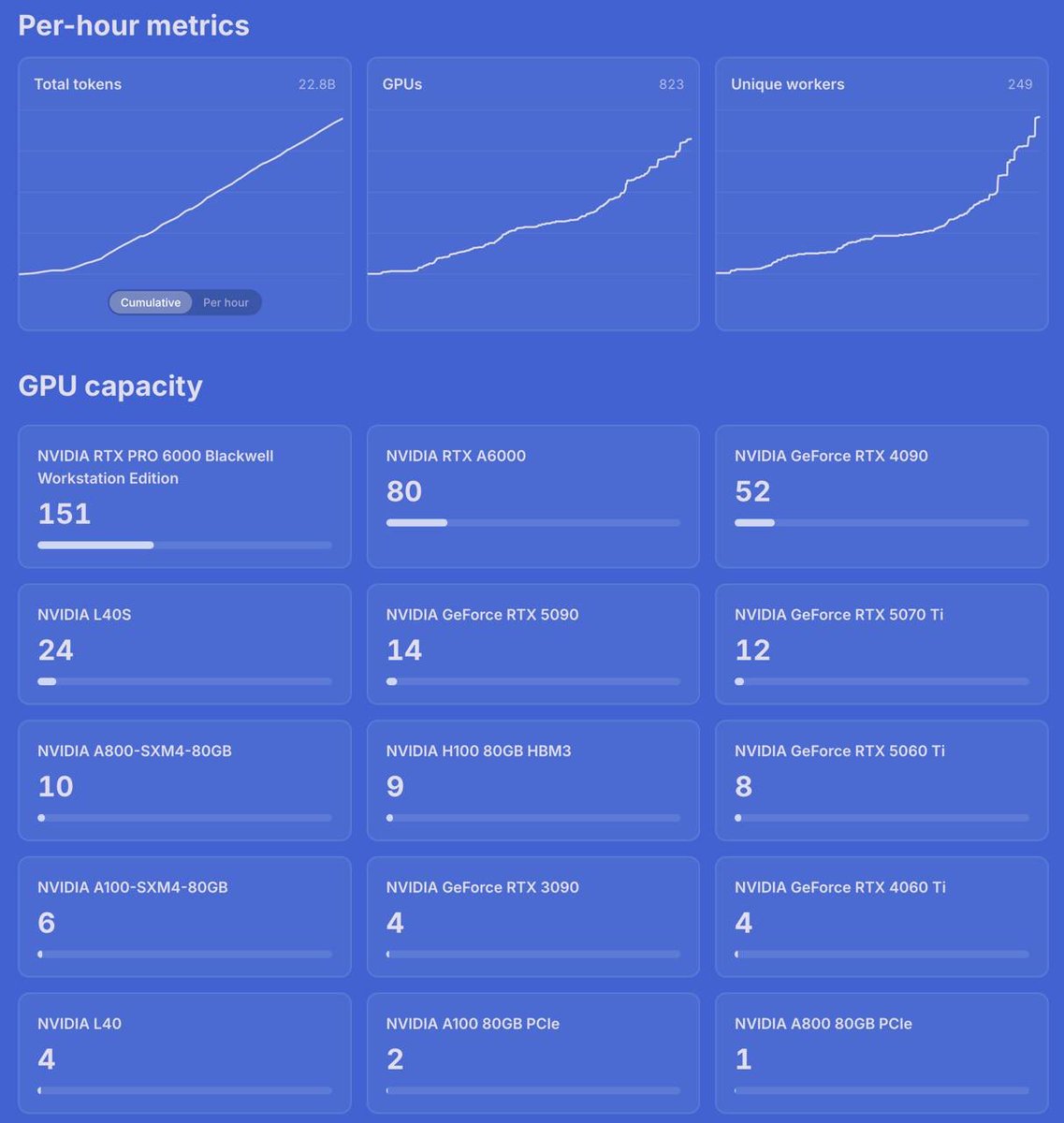
Qwen 3.6 35B data generation on Dolphin Network
22.8 billion tokens generated
383 GPUs online right now
24.33 TB of aggregate vRAM
Equivalent to over 300 H100s worth of idle GPU memory repurposed for inference
https://t.co/Wwpy7eKHX9
Node provider rollout has been going well
Our pool of inference nodes running Qwen 3.6 35B have generated over 3.2B tokens so far
Total inference bandwidth -> 9400 t/s
28x RTX 4090
12x RTX 5090
8x RTX PRO 6000
& many other cards
API access coming soon 🐬
🐬 Dolphin X1 Trinity Nano is HERE and it answers EVERYTHING
🔓 Built with a first-of-its-kind RL de-alignment pipeline — no hedging, no lectures, no dad advice
🔹 100% benchmark response rate vs GPT-5 at 11% and Gemini 2.5 Pro at 24%
🔹 Multi-gate, multi-judge reward system that blocks every escape route
🔹 Runs fully local on vLLM — your data never leaves your machine
🔹 Perfect for red teamers, security researchers and AI safety teams
🔥 Watch the full video below 👇
https://t.co/zbCb1zYEIL
We have also released a blog post that goes into detail on the RL environment design, as well as the challenges we encountered along the way
https://t.co/3Z3kQAU2BN
You can also try it for free in our Web UI at https://t.co/XqmguUlPxs
Dolphin X1 Trinity Nano is now live on @huggingface
Our smallest decensored model yet - 6B MoE with 1B active parameters trained using only online RL
Huge thanks to @TargonCompute for providing an 8xB200 node, @PrimeIntellect for hosted RL, and @arcee_ai for the Trinity series
You can download the model today on Hugging Face and run Q8_0 with a 32K context on just 8GB of VRAM
It can even run on mobile devices
Full weights
https://t.co/bvWOhTE0iz
GGUF
https://t.co/nSPQaoBvv7
FP8
https://t.co/qZLx3mzcsb
First epoch of rewards for node providers has been paid out
50K $POD distributed to 33 providers based on relative contributions to the Qwen 35B inference pool
https://t.co/Wwpy7eKHX9
Node provider rollout has been going well
Our pool of inference nodes running Qwen 3.6 35B have generated over 3.2B tokens so far
Total inference bandwidth -> 9400 t/s
28x RTX 4090
12x RTX 5090
8x RTX PRO 6000
& many other cards
API access coming soon 🐬
We have a new paper on model weight proofs that run on every request inside the inference engine releasing soon
In v1, we were relying on logprobs to verify the correct model is loaded via the expected fingerprint
Alongside slashable bonds for operators, i’d argue that was already very strong but it will be greatly improved in v2 which we are releasing within a month
For v2, we don’t have to rerun inference on a validator GPU in the same way you have to with logprobs - instead we have proofs that can be validated very quickly on a CPU with less overhead
Preview of benchmarks attached
@0xmons This was built on Mistral small 3.2 vision, the updated version - still has 870k monthly downloads
Have a bunch of new models we have been working on that will be releasing soon
https://t.co/X34GlLYov1
@lucaxyzz Guide at https://t.co/jfPki95ZoU
RTX 6000 PRO can participate now in running Qwen 3.6 35B
Support for smaller GPUs coming soon
You can watch the network stats live at https://t.co/Wwpy7eKHX9
@0x_bzzz@0xJeff We verify node operators are running the expected model by comparing logprobs + tokenised output to validators & a bunch of other techniques