The top Hermes integrations to give your agent superpowers:
1. Obsidian
It works as a Karpathy-style second brain, but one that talks back.
Every note, page, and backlink in the vault becomes live context. The agent doesn't just store knowledge, it reasons over it across everything that's been written and saved.
2. Playwright
It gives Hermes a real browser instead of a read-only window to the web.
It clicks, fills forms, and navigates pages the way a person would, then runs UI tests across Chromium, Firefox, and WebKit. This lets you turn Hermes from something that reads the web into something that can act on it.
3. InsForge
It puts a full agentic backend behind one semantic layer.
Auth, database, storage, and edge functions are all accessible without wiring five services together. The agent reasons about backend primitives directly instead of juggling disconnected APIs.
GitHub: https://t.co/jW3qHLCmS3
(don't forget to star 🌟)
4. GitHub
It connects code, issues, and pull requests, turning Hermes into an engineering teammate that can actually read the repo.
5. Bright Data
It hands agents web access that does not get blocked.
It pulls live search results, full pages, and clean structured data from places like X, LinkedIn, and Reddit, handling the proxies, CAPTCHAs, and rendering underneath so the agent just gets usable data back.
GitHub: https://t.co/w9C83iyoYn
(don't forget to star 🌟)
6. Sequential thinking
It upgrades how Hermes reasons rather than what it connects to.
Most integrations give the agent new senses. This one gives it a better mindset. It forces Hermes to break a hard problem into ordered steps and revise its own plan as it goes, instead of committing to the first answer that looks right.
7. Google workspace
It connects Gmail, Calendar, Drive, Docs, and Sheets in one place.
The agent that can't check the inbox, read the calendar, or write to a shared doc is basically decorative. This should probably be the first integration anyone enables.
8. Zapier
It acts as the layer that connects Hermes to everything else in the world.
This single connector reaches thousands of downstream apps. Hermes can fire off a workflow, update a record, or move data between tools without anyone writing the glue code.
9. Stripe
It surfaces revenue, refunds, subscription changes, and failed charges through a single question instead of clicking through dashboards.
It turns Stripe from a payment processor into a queryable business intelligence layer.
10. Slack
It handles channel-based automation inside Slack.
Hermes can live inside specific channels with its own workflow in each. Support tickets from email get scanned, categorized, and dropped into the right channel every morning without anyone lifting a finger. It can also read on-call threads and post status updates so the team stops switching tabs to stay in sync.
11. Graphiti
It builds real-time knowledge graphs of structured relationships from conversations and documents.
Instead of flat vector similarity, the agent traverses typed connections between entities. That is the difference between finding similar text and understanding how things actually relate.
GitHub: https://t.co/aFsgR0kYb2
(don't forget to star 🌟)
12. Figma
It gives the agent design context it can actually read.
Hermes can pull a frame, read the tokens and layout, and turn it into code that respects the system down to the spacing. With FigJam it goes the other way too, generating architecture diagrams and ERDs straight from a prompt. It is underrated for anyone who lives between design and engineering.
To dive deeper into Hermes, my co-founder wrote a full deep dive covering the Hermes agent's architecture, memory system, self-evolving skills, GEPA optimization, and how to set up multiple specialized agents.
Read it below.
One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]
How to set up Claude Code so it runs like a full dev team:
5 folders. That's the entire system.
1. CLAUDE.md → Memory.
Your repo's constitution. Naming rules, structure, expectations. One global file for all projects, one local file per repo.
2. skills/ → Knowledge.
Reusable workflows Claude auto-invokes by matching the task description. No slash commands. It just knows.
3. hooks/ → Guardrails.
Shell scripts that run before and after every tool call. Block dangerous commands. Auto-lint on save. Ping Slack on deploy. Deterministic. Not AI.
4. subagents/ → Delegation.
Isolated agents with their own context window. A code reviewer that only sees the diff. A test runner with custom permissions. Keeps your main session clean.
5.plugins/ → Distribution.
Bundle the whole system into one install. Every teammate gets the same skills, same hooks, same agents. Aligned from day one.
This is the Agent Development Kit. Five layers, one stack.
To learn how and get the full Claude guide:
1. Go to https://t.co/xViEAXTX7v
2. Subscribe free by just writing your email.
3. Open my welcome email and get the free resources.
Repost ♻️ to help someone in your network.
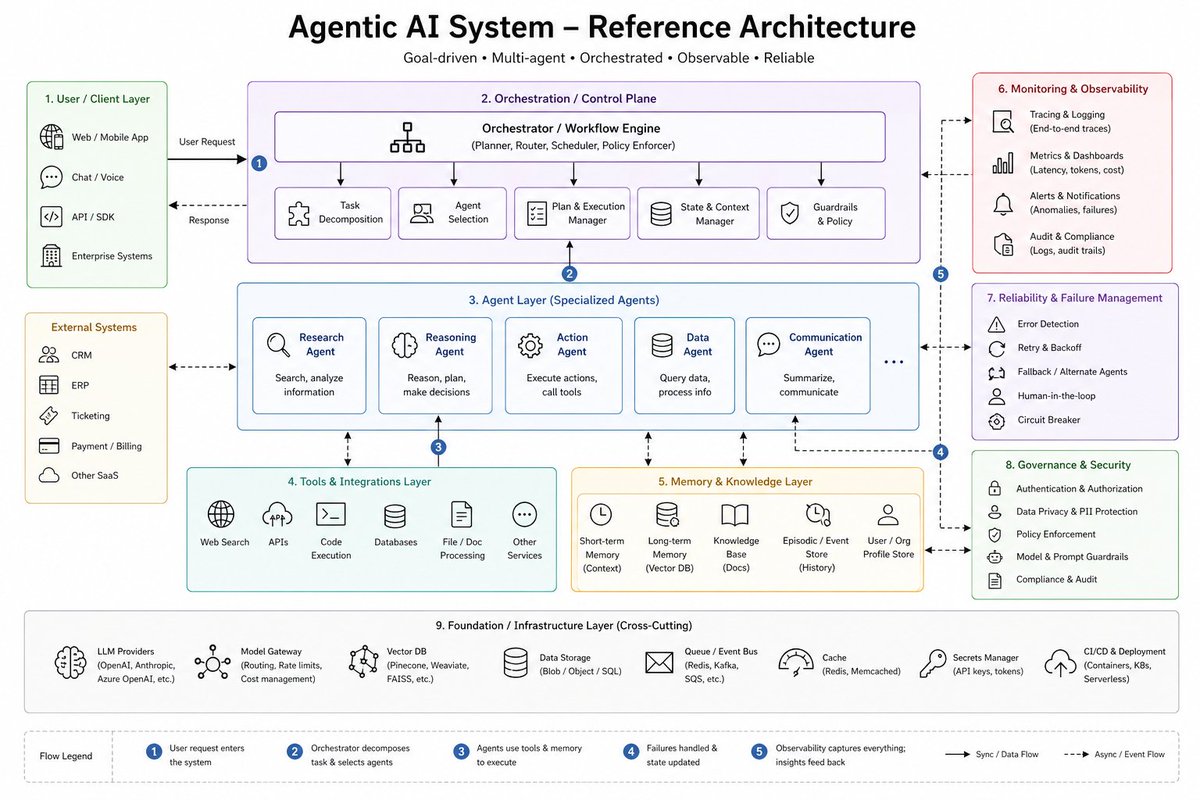
After reading @AnthropicAI blog on Agentic AI. spent some time to create a mental model to understand how to design, and explain Agentic AI architecture
Define a task/goal - what you want agent to do achieve?
1. Orchestration layer : it is your control panel
3. Agents layer: this layers made of agents (multi /specialised)
4. tools: your tools are made of this layer (web search, DB, APIs etc)
5. memory: this is the brain to store information - long or short term etc.
6. monitoring : This is the most crucial to monitor each and every step
7. Reliability & failure management: identify errors, retry, fallback, involve human
8. Governance and security: compliance, audit, auth etc.
Karpathy's LLM Wiki idea. I built it a month ago using Gemini 3.1 Flash Lite and Google ADK.
An Always-on AI agent running 24/7, continuously processing, and connecting information into memory.
Same pattern. Just an LLM that reads, thinks, and writes.
100% opensource.
RAG is broken and nobody's talking about it.
Stanford researchers exposed the fatal flaw killing every "AI that reads your docs" product in existence.
It’s called "Semantic Collapse," and it happens the second your knowledge base hits critical mass. If you've noticed your AI getting "dumber" as you add more data, this is exactly why.
Right now, companies are dumping thousands of documents into their AI, thinking it’s getting smarter.
When you add a document to RAG, it converts it into a high-dimensional vector.
Under 10,000 documents, this works perfectly. Similar concepts cluster together.
But past 10,000 documents, the space fills up. The clusters overlap. The distances compress.
Everything starts to look "relevant."
It is a mathematical law called the Curse of Dimensionality. In a 1000-dimensional space, 99.9% of your data lives on the outer edge. All points become equidistant from each other.
That perfect, relevant document you are looking for now has the exact same mathematical similarity as 50 completely irrelevant ones.
The Stanford findings are brutal:
At 50,000 documents, precision drops by 87%. Semantic search actually becomes worse than old-school keyword search.
Adding more context doesn’t fix the AI. It makes the hallucinations worse.
Your "nearest neighbor" search isn't finding the best answer anymore. It's finding everyone.
We thought RAG solved hallucinations.
It didn't. It just hid them behind math.
Holy shit. The biggest unsolved problem in AI agents isn't reasoning it's memory. Your agent forgets everything between sessions.
MemFactory just open-sourced the first unified framework for training agents to manage their own memory via reinforcement learning. Extract.
Update. Retrieve. All trainable. All modular. Runs on one GPU.
Every AI agent built today is amnesiac by design. It can reason. It can plan.
It can use tools. But the moment a session ends, everything it learned about you, your preferences, your context, and your history disappears.
The next conversation starts from zero.
This is not a minor inconvenience it is the fundamental barrier between AI assistants and AI agents that actually work over days, weeks, and months. The field has known this for years.
The solutions have been fragmented, task-specific, and impossible to combine. Memory-R1 handles structured CRUD operations on a memory bank. MemAgent compresses history into a fixed-length recurrent state.
RMM optimizes retrieval through retrospective reflection. Each works.
None can be combined. Each lives in its own repository with its own data format, its own training pipeline, and its own set of assumptions. MemFactory ends that fragmentation.
The core insight is that memory management is a decision problem, not a retrieval problem. Current systems treat memory as a database store things, look things up.
MemFactory treats memory as a policy an agent that learns when to extract new information, when to update existing memories, when to delete contradicted facts, and what to retrieve for any given query.
That policy is trained via reinforcement learning, specifically Group Relative Policy Optimization, which eliminates the need for a separate critic model and cuts training memory requirements in half.
This matters because memory-augmented agents already have saturated context windows from dialogue history and retrieved content.
The last thing they need is a training algorithm that doubles the memory footprint.
The architecture is four layers that compose like Lego blocks.
The Module Layer decomposes memory into atomic operations:
> Extractor parses raw conversations into structured memory entries,
> Updater decides whether each new piece of information should be added, modify an existing entry, delete a contradiction, or left alone,
> Retriever fetches relevant memories using semantic search or LLM-based reranking.
The Agent Layer assembles these modules into a complete memory policy and executes rollout trajectories during training.
The Environment Layer standardizes any dataset into the format the agent needs and computes reward signals format rewards for structural compliance, LLM-as-a-judge scores for quality.
The Trainer Layer runs GRPO to update the memory policy based on those rewards. Every module plugs into every other module through standardized interfaces.
You can swap the retriever in Memory-R1 for an LLM-based reranker without touching anything else.
The results from training a MemAgent-style architecture through MemFactory on two base models:
→ Qwen3-1.7B base: average score 0.3118 across three evaluation sets
→ Qwen3-1.7B after MemFactory RL: 0.3581 14.8% relative improvement
→ Qwen3-4B-Instruct base: average score 0.6146
→ Qwen3-4B-Instruct after MemFactory RL: 0.6595 7.3% relative
improvement
→ 4B model gains hold on out-of-distribution benchmarks the memory policy transfers to unseen tasks
→ Entire training and evaluation pipeline runs on a single NVIDIA A800 80GB GPU
→ 250 training steps on simplified long-context data no massive compute cluster required
→ Three ready-to-use agent architectures out of the box: MemoryR1Agent, MemoryAgent, MemoryRMMAgent
> The out-of-distribution result is the one that matters most. The 1.7B model improved on in-domain tasks but slightly degraded on the OOD benchmark the learned policy was too specific to the training distribution.
The 4B model improved on both.
This is the capability threshold at which a memory policy becomes genuinely general: large enough to abstract principles about what information is worth keeping, not just pattern-match on training examples.
A memory agent that only remembers the right things in familiar situations is not much better than no memory at all.
The 4B result suggests that threshold is reachable with models that fit on a single consumer GPU.
> The fragmentation problem MemFactory solves is deeper than it looks. When every memory implementation has its own pipeline, researchers cannot compare approaches fairly.
Two systems that nominally differ by one design choice say, CRUD operations versus recurrent state compression actually differ simultaneously in data format, reward structure, training algorithm, and evaluation protocol.
Nobody knows which choice caused which outcome.
MemFactory puts all three major paradigms under the same training loop, the same reward computation, and the same evaluation framework.
Now you can actually isolate what matters.
Your agent forgets everything. This is the infrastructure to fix that.














![AndrewYNg's tweet photo. One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]](https://pbs.twimg.com/media/HJvWmCHagAAnTxQ.jpg)