Mine and @songandyliu's ICML paper is now out on Arxiv! https://t.co/0lqlGpWsei
This is 2 years of PhD research in action. We use Stein Discrepancies to accurately estimate truncated densities without knowing a functional boundary.
I've been testing something that makes me forget I ever needed to code.
The next version of Elysia is about to change how you build AI workflows.
We're excited to share that the Weaviate team has started building the next version of Elysia – and it's bringing some pretty promising capabilities to the table.
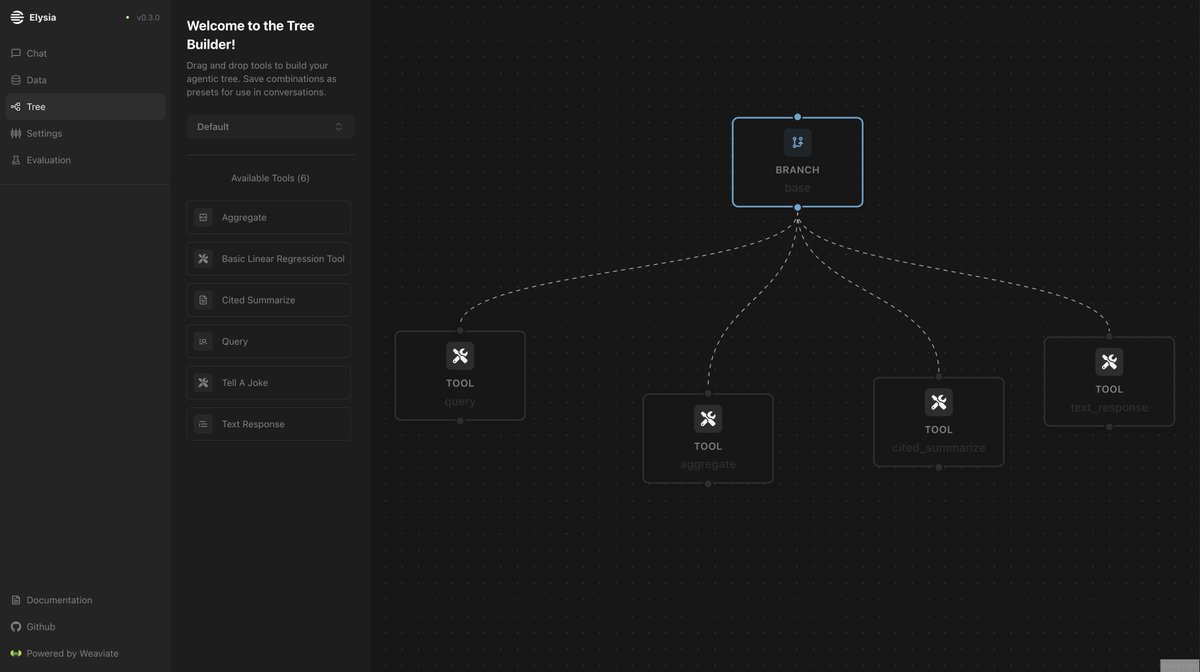
The headline feature: Pipeline Builder. ⚒️ 🤓
Here's what it does:
With the Pipeline Builder, you can now create your own custom tools and orchestrate custom decision trees directly in the frontend.
This means you get complete flexibility to design workflows for any use case you need – whether that's specialized data retrieval, multi-step reasoning processes, or entirely custom agentic behaviors – all while harnessing the complete Elysia infrastructure.
For context, Elysia's existing architecture already supports custom tools and conditional branching in Python; however, bringing this capability to the frontend opens up the framework to a much wider range of users and use cases. You can iterate faster, experiment with different configurations, and build sophisticated agentic workflows without context-switching between code and interface.
You can read more about Elysia in our recent blog post, GitHub and Documentation
Blog Post: https://t.co/GNDL92oz9D
GitHub: https://t.co/j9LKpjs7zU
Documentation: https://t.co/pWaaQr1E4H
Google just proved that bigger isn't always better.
Their 308M parameter model is outperforming models 2x its size.
Google just released 𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝗚𝗲𝗺𝗺𝗮, and it's proving that lightweight embedding models can punch way above their weight class.
At just 308M parameters (578MB), it's the new state-of-the-art for models under 500M parameters across MTEB multilingual, English, and code benchmarks. But the really impressive part is that it ranks 8th overall on MTEB(Multilingual, v2) - that's 𝟭𝟳 𝗽𝗹𝗮𝗰𝗲𝘀 above the second-best sub-500M model, and it's delivering performance 𝗰𝗼𝗺𝗽𝗮𝗿𝗮𝗯𝗹𝗲 𝘁𝗼 𝗺𝗼𝗱𝗲𝗹𝘀 𝗻𝗲𝗮𝗿𝗹𝘆 𝗱𝗼𝘂𝗯𝗹𝗲 𝗶𝘁𝘀 𝘀𝗶𝘇𝗲.
There are three key parts of their training recipe that sets it apart:
𝟭. 𝗘𝗻𝗰𝗼𝗱𝗲𝗿-𝗗𝗲𝗰𝗼𝗱𝗲𝗿 𝗜𝗻𝗶𝘁𝗶𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻
Instead of starting from a decoder-only Gemma 3 model, they first adapted it to encoder-decoder, then used just the encoder. By basing EmbeddingGemma off an LLM that already has world and language understanding, it gives it a stronger starting point.
𝟮. 𝗧𝗵𝗿𝗲𝗲-𝗟𝗼𝘀𝘀 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴
They combine three different loss functions, instead of just having one:
• Contrastive loss (NCE) with in-batch negatives and hardness weighting
• Spread-out regularization to ensure embeddings utilize the full space (for quantization and ANN retrieval)
• Embedding matching distillation from Gemini Embedding - not just learning from relevance scores, but directly aligning the embedding space with the teacher model
𝟯. 𝗠𝗼𝗱𝗲𝗹 𝗦𝗼𝘂𝗽𝗶𝗻𝗴
Rather than just averaging checkpoints from the same training run, they use optimization techniques to find multiple specialized training mixtures. Each mixture creates an "expert" model in different domains, and averaging all their parameters creates a final model that's actually better than individual models.
Extras:
• Matryoshka embeddings supporting 768, 512, 256, and 128 dimensions
• Quantization-aware training - maintains quality even at int4 precision
• 100+ languages from Gemma 3 pretraining
• Exceptional performance on low-resource languages (check their XTREME-UP results)
Is it the absolute best embedding model? No - Gemini Embedding still leads overall. But that's not really the point. EmbeddingGemma proves you can achieve state-of-the-art performance in a small package that's actually deployable on-device, in low-latency applications, and in resource-constrained environments.
This makes good embeddings accessible for use cases that I'm seeing more and more: offline applications, privacy-sensitive deployments, and high-throughput scenarios where inference cost actually matters.
Full paper: https://t.co/B7CZClx2EA
Shoutout to the EmbeddingGemma team at @GoogleDeepMind for this awesome open source work 💙
and to @drdannywilliams for helping me with this video! 🫶
We just released our complete guide to Context Engineering.
(These 6 components are the future of production AI apps)
Every developer hits the same wall when building with Large Language Models: the model is brilliant but fundamentally disconnected. It can't access your private documents, has no memory of past conversations, and is limited by its context window.
The solution isn't better prompts. It's 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 - the discipline of architecting systems that feed LLMs the right information in the right way at the right time.
Our new ebook is the blueprint for building production-ready AI applications through 6 core components:
1️⃣ 𝗔𝗴𝗲𝗻𝘁𝘀: The decision-making brain that orchestrates information flow and adapts strategies dynamically
2️⃣ 𝗤𝘂𝗲𝗿𝘆 𝗔𝘂𝗴𝗺𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻: Techniques for transforming messy user requests into precise, machine-readable intent through rewriting, expansion, and decomposition
3️⃣ 𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹: Strategies for chunking and retrieving the perfect piece of information from your knowledge base (semantic chunking, late chunking, hierarchical approaches)
4️⃣ 𝗣𝗿𝗼𝗺𝗽𝘁𝗶𝗻𝗴 𝗧𝗲𝗰𝗵𝗻𝗶𝗾𝘂𝗲𝘀: From Chain of Thought to ReAct frameworks - how to guide model reasoning effectively
5️⃣ 𝗠𝗲𝗺𝗼𝗿𝘆: Architecting short-term and long-term memory systems that give your application a sense of history and the ability to learn
6️⃣ 𝗧𝗼𝗼𝗹𝘀: Connecting LLMs to the outside world through function calling, the Model Context Protocol (MCP), and composable architectures
We're not just teaching you to prompt a model - we're showing you how to architect the entire context system around it. This is what is going to take AI from demo status to actual useful production applications.
Each section includes practical examples, implementation guidance, and real-world frameworks you can use today.
Download it here: https://t.co/Z7IRWNGMZc
Is vanilla RAG already outdated?
After trying Elysia, I think it might be.
Elysia is an agentic RAG system built with Weaviate Agents that 𝗱𝘆𝗻𝗮𝗺𝗶𝗰𝗮𝗹𝗹𝘆 𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝘀 𝗱𝗮𝘁𝗮 𝗾𝘂𝗲𝗿𝗶𝗲𝘀 𝗯𝗮𝘀𝗲𝗱 𝗼𝗻 𝘂𝘀𝗲𝗿 𝗿𝗲𝗾𝘂𝗲𝘀𝘁𝘀.
Try it here: https://t.co/P1POPp8l5n
Unlike vanilla RAG systems that use semantic search for everything, Elysia:
- Analyzes user requests to determine optimal search strategies
- Can perform filtered, sorted database queries (e.g., "show 10 most recent open GitHub issues")
- Handles contextual follow-up questions by referencing previous results
- Uses a decision tree with four main tools: query, aggregate, summarize, and text response
@drdannywilliams and @aestheticedwar1 built the whole app from scratch:
- Built with Python, NextJS, and FastAPI
- Uses DSPy to optimize prompts from larger teacher models for smaller, faster inference
- Currently in alpha (free, no signup)
- Will be open-sourced in its beta release (in a couple months)
- Future plans include web search capabilities, data visualization, and user-created tools
The alpha version includes sample datasets of GitHub issues, Slack conversations, emails, weather data, fashion e-commerce, ML Wikipedia articles, and Weaviate documentation for you to test out!
This will retire 90% of RAG systems with dignity (and a sad song playlist). Powered by DSPy: If you're still building "text in, text out" chatbots that only perform blind vector and text searches, you're not gonna make it!
My team just dropped Elysia, and it's not just an incremental successor to Verba… It's a whole rethink of how we interact with our data using AI.
𝗪𝗵𝗮𝘁 𝗶𝘀 𝗘𝗹𝘆𝗶𝘀𝗮?
An open-source platform for building agentic RAG architectures. It learns from your preferences, intelligently categorizes, labels, and searches through your data, and provides complete transparency into its decision-making process.
The long & exciting feature list:
• 𝗧𝗿𝗮𝗻𝘀𝗽𝗮𝗿𝗲𝗻𝘁 𝗗𝗲𝗰𝗶𝘀𝗶𝗼𝗻-𝗧𝗿𝗲𝗲 𝗔𝗴𝗲𝗻𝘁𝘀: Elysia’s core is a customizable decision tree, and it visualizes its entire reasoning process, showing you why it chooses a specific tool or path.
It enables advanced error handling, self-healing from failed queries, and prevents infinite loops. You can also add custom tools and branches to build complex, state-aware workflows.
• 𝗗𝗮𝘁𝗮 𝗔𝘄𝗮𝗿𝗲𝗻𝗲𝘀𝘀: Before it even attempts a query, Elysia performs a full analysis of your data collections. This eliminates the blind search problem plaguing most RAG systems and allows for far more complex and accurate query generation.
• 𝗗𝘆𝗻𝗮𝗺𝗶𝗰 𝗗𝗮𝘁𝗮 𝗗𝗶𝘀𝗽𝗹𝗮𝘆𝘀: Your RAG pipeline shouldn't be limited to text, right? That’s why Elysia analyzes each query's results and chooses the best way to display them, from tables and charts to product cards and GitHub tickets. It also features a comprehensive data explorer with search, sorting, and filtering capabilities.
• 𝗛𝘆𝗽𝗲𝗿-𝗣𝗲𝗿𝘀𝗼𝗻𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝘃𝗶𝗮 𝗙𝗲𝗲𝗱𝗯𝗮𝗰𝗸: It uses your positively-rated queries as few-shot examples to improve future responses. This allows you to use smaller, faster models that perform like larger ones over time, cutting costs without sacrificing quality for most use cases.
• 𝗖𝗵𝘂𝗻𝗸-𝗢𝗻-𝗗𝗲𝗺𝗮𝗻𝗱: Elysia chunks documents at query time. It performs initial searches on document-level vectors and only chunks relevant documents on the fly, storing them in a parallel quantized collection with cross references for future use.
𝗧𝗵𝗲 𝗦𝘁𝗮𝗰𝗸
Elysia is built from scratch on Weaviate, using its native features like named vectors, a variety of search types, filters, cross references, quantization, etc. It uses DSPy for LLM interactions and is delivered as a production-ready application via FastAPI, serving a NextJS frontend as static HTML.
Also available as a Python package via pip:
𝗽𝗶𝗽 𝗶𝗻𝘀𝘁𝗮𝗹𝗹 𝗲𝗹𝘆𝘀𝗶𝗮-𝗮𝗶
Type: 𝗲𝗹𝘆𝘀𝗶𝗮 𝘀𝘁𝗮𝗿𝘁
Connect your Weaviate cluster and go explore what’s possible.
In Pedion Elysion - pip install elysia-ai
Welcome to Elysia, your open-source agentic RAG framework with a fully end-to-end frontend application on top of it and built on top of @weaviate_io - easily installable through one single pip install and one single command:
start elysia
Most AI applications are chatbots stuck in a text-only world. We show you how our framework dynamically decides not just what to say, but also 𝗵𝗼𝘄 to show it.
It’s a complete rethink of RAG applications that brings transparency, intelligence, and visual flexibility to your data interactions. + we have an epic trailer ❤️🔥
NOW AVAILABLE!!!!111
Read more about Elysia in our newest blog post: https://t.co/w42zBNc6aZ
Try out free live demo: https://t.co/zMSdYpl8ay
Install it now: https://t.co/j9LKpjs7zU
Have you tried out agentic RAG yet?
This is how Elysia does it 🔽
Try out the demo here: https://t.co/P1POPp7NfP
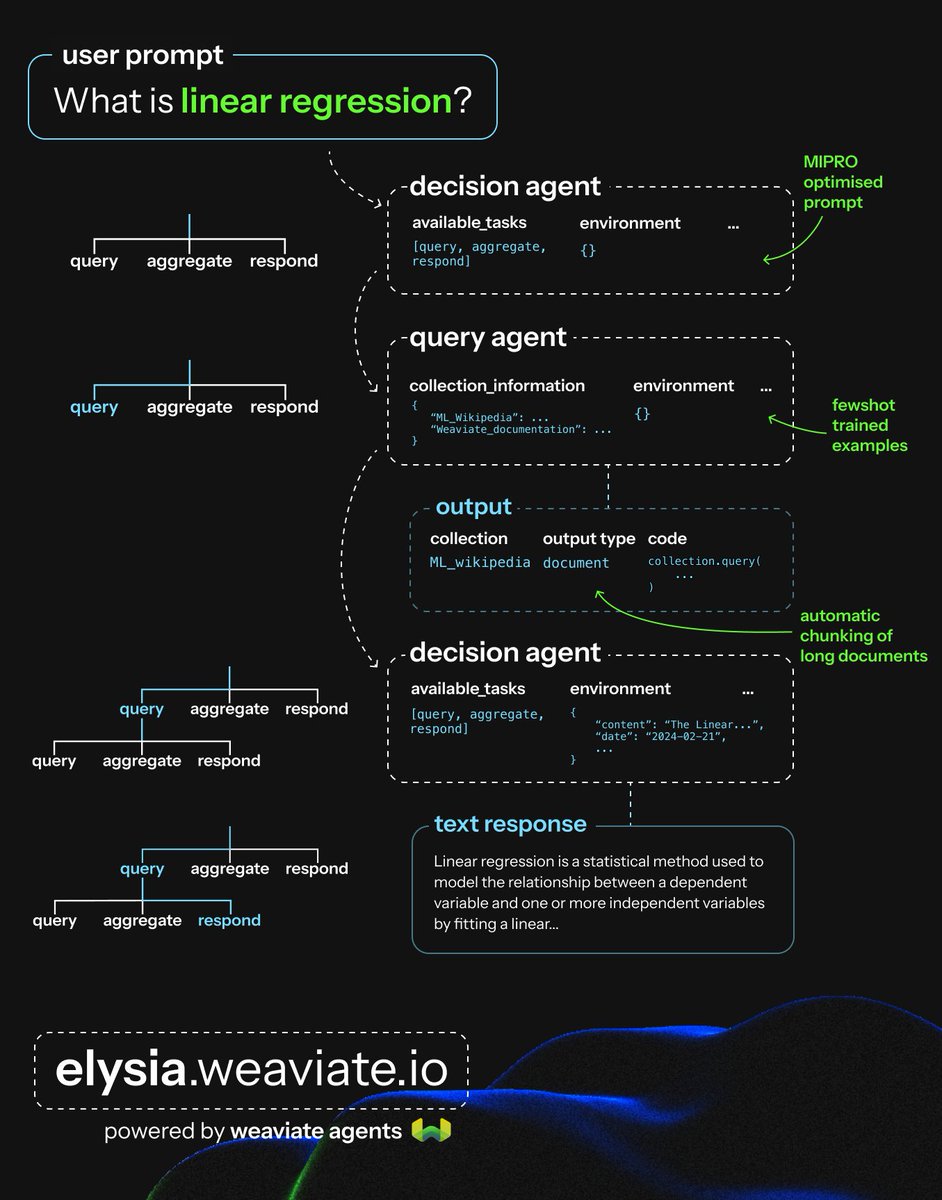
𝗪𝗵𝗲𝗻 𝗮 𝘂𝘀𝗲𝗿 𝗾𝘂𝗲𝗿𝘆 𝗰𝗼𝗺𝗲𝘀 𝗶𝗻:
1) The decision agent is pre-trained with a MIPRO optimised prompt: it reads the user prompt and 𝗱𝗲𝗰𝗶𝗱𝗲𝘀 𝘄𝗵𝗶𝗰𝗵 𝘁𝗮𝘀𝗸 𝗯𝗲𝘀𝘁 𝗳𝗶𝘁𝘀.
2) 𝗙𝗼𝗿 𝗮 𝘂𝘀𝗲𝗿 𝗽𝗿𝗼𝗺𝗽𝘁 𝗿𝗲𝗾𝘂𝗶𝗿𝗶𝗻𝗴 𝗿𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹, Elysia will choose the query task, and then use a separate query agent to create an optimized query for the vector database (@weaviate_io).
The query agent will make its own decisions on the components necessary, including:
• choosing the right collection within the database,
• writing the text query,
• and applying any filters or limits as necessary.
3) The outputs are returned, and then 𝗽𝗮𝘀𝘀𝗲𝗱 𝗯𝗮𝗰𝗸 𝘁𝗼 𝘁𝗵𝗲 𝗱𝗲𝗰𝗶𝘀𝗶𝗼𝗻 𝗮𝗴𝗲𝗻𝘁 𝘁𝗼 𝗱𝗲𝗰𝗶𝗱𝗲 𝘄𝗵𝗮𝘁 𝘁𝗮𝘀𝗸 𝘁𝗼 𝗱𝗼 𝗻𝗲𝘅𝘁. Some cases might require additional queries or aggregations, but in this example, it simply uses the retrieved context to generate a response.
In production Q&A systems, I’ve found that 𝘂𝘀𝗲𝗿 𝗾𝘂𝗲𝗿𝗶𝗲𝘀 𝗮𝗿𝗲 𝗿𝗮𝗿𝗲𝗹𝘆 𝗻𝗶𝗰𝗲𝗹𝘆 𝗳𝗼𝗿𝗺𝗮𝘁𝘁𝗲𝗱 𝗾𝘂𝗲𝘀𝘁𝗶𝗼𝗻𝘀 𝘄𝗶𝘁𝗵 𝘀𝘁𝗿𝗮𝗶𝗴𝗵𝘁𝗳𝗼𝗿𝘄𝗮𝗿𝗱 𝘄𝗼𝗿𝗱𝘀 that work well for retrieval, even with vector search. The nice thing about using agentic systems is it doesn’t matter if the user question is vague, or misspelled, or has a lot of random other words - the agent will figure out how best to format the query for the database to get the best content, and therefore provide the best response.
Learn more about the Weaviate Query Agent: https://t.co/fz9scS2prz
How do you build an end-to-end agentic RAG app?
Lucky for you, you can just run two commands: ‘pip install elysia-ai’ and ’elysia start’
I wrote a massive blog post detailing all the things we built into this 𝗼𝗽𝗲𝗻 𝘀𝗼𝘂𝗿𝗰𝗲 𝗲𝗻𝗱-𝘁𝗼-𝗲𝗻𝗱 𝗮𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚 𝗳𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸: https://t.co/185SQ8oQUj
But if you don't have time to read though that, here’s the TLDR version 🔽
Instead of the typical "text in, text out" approach, Elysia uses a decision tree architecture where intelligent agents determine the best tools to use, evaluate results, and decide whether to continue or complete their tasks. It's an AI that actually thinks through problems step-by-step in a controllable, user-understandable format.
The three main things that set Elysia apart:
1️⃣ 𝗗𝗲𝗰𝗶𝘀𝗶𝗼𝗻 𝗧𝗿𝗲𝗲𝘀 𝘄𝗶𝘁𝗵 𝗦𝗺𝗮𝗿𝘁 𝗔𝗴𝗲𝗻𝘁𝘀: Each node has a decision agent with global context awareness. They evaluate past actions, current state, and future possibilities to choose the optimal tool. Plus, they can handle errors intelligently – if something fails, they'll try a different approach rather than just giving up.
2️⃣ 𝗗𝘆𝗻𝗮𝗺𝗶𝗰 𝗗𝗶𝘀𝗽𝗹𝗮𝘆𝘀: Elysia chooses from seven display formats – tables, e-commerce cards, tickets, conversations, documents, charts, and more. It analyzes your data structure and automatically picks the most appropriate way to present information.
3️⃣ 𝗔𝘂𝘁𝗼𝗺𝗮𝘁𝗶𝗰 𝗗𝗮𝘁𝗮 𝗘𝘅𝗽𝗲𝗿𝘁𝗶𝘀𝗲: Unlike traditional RAG systems that perform blind searches, Elysia analyzes your collections first. It understands your data structure, creates summaries, generates metadata, and uses this knowledge to handle complex queries intelligently.
The frontend displays the entire decision tree as it's traversed, showing you exactly why it made each choice. No more black-box AI systems – you get complete transparency into the reasoning process.
We built Elysia to be the successor to Verba, taking everything we learned about RAG applications and pushing it to the next level. It's not just about retrieving and generating anymore – 𝗶𝘁'𝘀 𝗮𝗯𝗼𝘂𝘁 𝗰𝗿𝗲𝗮𝘁𝗶𝗻𝗴 𝗔𝗜 𝗮𝘀𝘀𝗶𝘀𝘁𝗮𝗻𝘁𝘀 𝘁𝗵𝗮𝘁 𝘁𝗿𝘂𝗹𝘆 𝘂𝗻𝗱𝗲𝗿𝘀𝘁𝗮𝗻𝗱 𝗰𝗼𝗻𝘁𝗲𝘅𝘁 𝗮𝗻𝗱 𝗽𝗿𝗲𝘀𝗲𝗻𝘁 𝗶𝗻𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻 𝗲𝗳𝗳𝗲𝗰𝘁𝗶𝘃𝗲𝗹𝘆.
GitHub: https://t.co/yOuCcIMDOv
Demo: https://t.co/P1POPp7NfP
Get started: https://t.co/7NS3SzRVeq
@arnaudvl3@philipvollet I'm not saying that asking "what is the data about" to every LLM data interface will cause that issue, but that there will likely be at least a few questions which can cause LLMs to make mistakes, since they're non-deterministic
@arnaudvl3@philipvollet Relying on LLMs to perform tasks will always have issues like this, unfortunately :( The demo uses gemini-2.5-flash for queries, which will not be as effective as say, Claude 4 Sonnet, which would probably reduce the issue somewhat, but will be slower. This is still in beta!
@_arindam@femke_plantinga Check out algorithm 2 of the paper: https://t.co/c11B8igMGR
Long late chunking is what we called overlapping elements of a longer document so that each overlapped document gets passed separately to the embedding model. Sort of like overlapping chunks but bigger
Navigating multiple databases can feel like searching through a sea of information.
(But guess what, you don’t have to anymore!)
We’re introducing the Query Agent - an AI assistant that seamlessly searches across your Weaviate collections!
Using the power of LLMs, Query Agent automatically:
• Decides which collections to search
• Combines information from multiple sources
• Provides comprehensive answers to complex questions
✨ Available now for all Weaviate Cloud & free sandbox users!
Try it today: https://t.co/3vw6HbkccU
Watch the full video by @tuanacelik and @femke_plantinga here: https://t.co/pWByjqRXcC
The future of data management isn't 𝘫𝘶𝘴𝘵 AI Agents.
It's AI agents WITH vector databases.
While everyone was busy writing RAG obituaries every time a new 200K context window dropped, the real innovation was happening elsewhere: specialized AI agents that make working with vector databases ridiculously easy.
We’ve introduced a set of pre-built AI agents that make working with vector databases significantly easier. Unlike general agent frameworks, these specialized data assistants come pre-configured to work with Weaviate’s APIs to handle specific data tasks precisely.
Here's what's launched:
🔍 𝗤𝘂𝗲𝗿𝘆 𝗔𝗴𝗲𝗻𝘁
Forget complex query syntax. This agent translates natural language questions into optimized database queries, handles multi-step reasoning, and returns exactly what you need from multiple collections, not just what you asked for.
🔄 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻 𝗔𝗴𝗲𝗻𝘁
Data wrangling made simple. This agent handles the messy work of transforming, cleaning, and preparing your data before it goes into your vector database.
👤 𝗣𝗲𝗿𝘀𝗼𝗻𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝗔𝗴𝗲𝗻𝘁
This agent creates user "personas" with preferences and tracks interactions (likes/dislikes) with weighted values. It then uses both classic vector similarity AND LLM-powered ranking to deliver truly personalized results.
The Personalization Agent is particularly clever - it maintains a separate "sister collection" of all user interaction data, allowing it to continuously improve its recommendations as users interact with your system.
So no, RAG isn't dead. It just grew up and got smarter friends.
See live demos and practical implementation tips you can apply immediately in this LIVE Agents Webinar.
Sign up here: https://t.co/szXYSOddDz
Struggling with low retrieval accuracy?
Late interaction preserves context other models compress away.
In our newest blog post, @helloiamleonie , Danny Williams, and @victorialslocum break down late interaction, including:
• The three main approaches to retrieval: No interaction models, full interaction models, and late interaction models
• How late interaction actually works
• The three most well-known late interaction models: ColBERT, for text-based retrieval, and ColPali, and ColQwen for multimodal or PDF retrieval
Read the blog: https://t.co/KlZjkQjOIo
Text-to-SQL is dead 💀
The next generation of querying is agentic - and it’s already here.
This paper (https://t.co/v2mSTZ6GnB) introduces a type of agentic querying called 𝗙𝘂𝗻𝗰𝘁𝗶𝗼𝗻 𝗖𝗮𝗹𝗹𝗶𝗻𝗴 that uses an LLM to structure queries using predefined function calls in JSON format, with optional arguments for search, filters, aggregation, and grouping.
Along with that, it also tests out a bunch of different models with a new dataset, DBGorilla, designed to evaluate agentic querying techniques on real-world use cases.
@weaviate_io also just released a 𝗤𝘂𝗲𝗿𝘆 𝗔𝗴𝗲𝗻𝘁, designed based on some of the work in this paper, to handle advanced agentic querying out of the box, find out more here: https://t.co/8bu5aYkFKP
Agentic RAG is the next step in search systems.
That's why we're releasing Elysia Alpha today.
Elysia explores your data automatically using Weaviate agents:
- Intelligent search
- Query construction
- Self-healing capabilities
Try it free, no signup: https://t.co/8m6qeRsr34