Would be interesting to turn all the recipes in #HowToCook into highly detailed visual guides. 🥘📷 🤗U1 for infographic:https://t.co/IZfAgzFdRj
📖Cook101 for coder: https://t.co/tqIbBKuItg
📢📢 𝗜𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝗶𝗻𝗴 𝗮𝗻 𝗲𝗻𝗵𝗮𝗻𝗰𝗲𝗱 𝗺𝗼𝗱𝗲𝗹 𝗳𝗼𝗿 𝗶𝗻𝗳𝗼𝗴𝗿𝗮𝗽𝗵𝗶𝗰 𝗴𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻!
📊 Posters, charts, recipe cards, postcards — even arXiv-style pages — all from 𝗦𝗲𝗻𝘀𝗲𝗡𝗼𝘃𝗮-𝗨𝟭-𝟴𝗕-𝗠𝗼𝗧-𝗜𝗻𝗳𝗼𝗴𝗿𝗮𝗽𝗵𝗶𝗰.
🚀 +6.8 / +18.2 on BizGenEval (hard) / IGenBench (Q-ACC) over base U1, plus 100+ diverse showcases.
🤗 https://t.co/sYjY1ne3JX
🖼️Showcases: https://t.co/7K0zET8gOt
Try it out — we'd love to see what you build!
@huggingface
🚀We just released SenseNova-U1-8B-MoT-Infographic!
It brings aesthetic posters, charts, comics, even arXiv paper to life with dense text!📈SOTA on infographic benchmarks!📊
🤗Weights: https://t.co/PqagRLIcW5
🎨100+ Examples: https://t.co/4pWOod37bv
Hope you have fun with it !!✨
We’re also releasing SenseNova-SI-8M,currently the largest spatial intelligence QA dataset available, to support future research.
If you’re also attending CVPR this June, happy to chat in person (Poster Session 2-ID 66)!
SenseNova-SI-8M: https://t.co/29eggyDGsP
Proud to announce the release of the SenseNova U1 Tech Report — together with the a new set of model weights based on MoE.
We hope this open release promotes transparency, reproducibility, and further innovation across the AI community.
Huge thanks to the team for making this possible. 🚀
Excited to have contributed to the spatial intelligence capabilities of SenseNova-U1, surpassing strong baselines such as Qwen3.5 on key benchmarks including VSI-Bench.
We’re also thrilled to open-source SenseNova-SI-8M, which is currently the largest spatial QA dataset to date.
See you at CVPR this June, happy to chat in person!
SenseNova-SI-8M: https://t.co/AHHjw5omzU
🔥 New week, New SenseNova-U1-A3B-MoT Drop — and this one goes Deep!🔥
Technical Report is OUT — the detailed disclosure of how to build Native Multimodal Unified Models.
Inside:
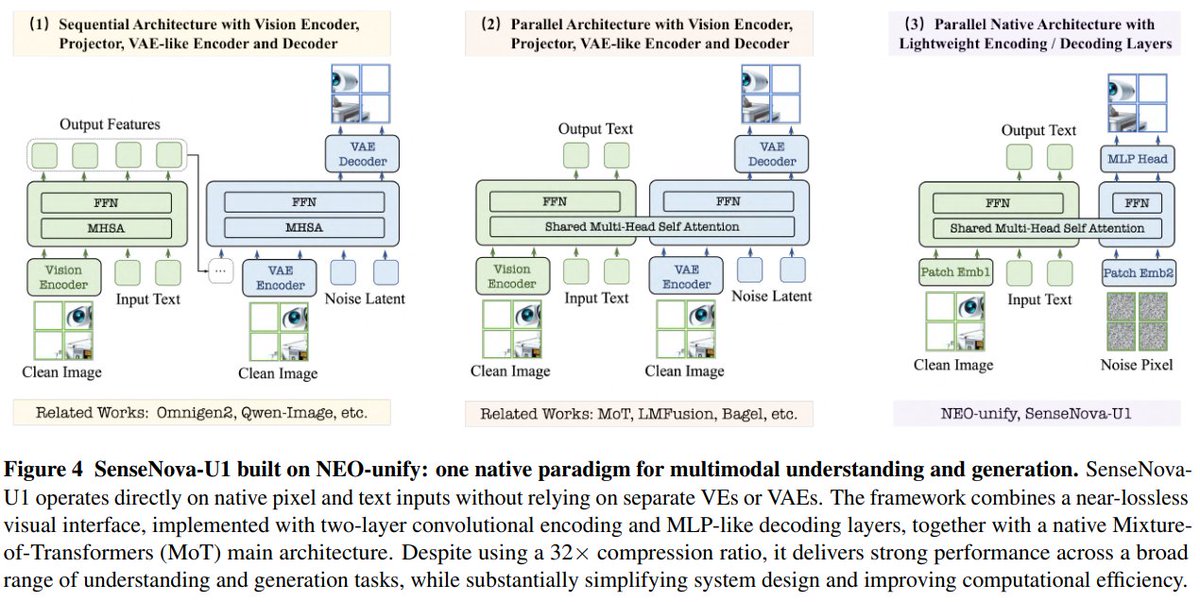
✨ Near-Lossless Visual Interface (no VEs, no VAEs, no Deep Decoders)
✨ Joint AR + Pixel-space Flow Matching
✨ Native Mixture-of-Transformers Backbone
✨ Training recipe + RL post-training + Distillation
📣 Paper: https://t.co/erw1PKbabE
🦁 Github: https://t.co/ANlWRuTkx0
🌟 Models: https://t.co/tOvuNPAMlD
🎮 Demo: https://t.co/R6cOj4FL6d
🥳The Technical Report of #SenseNovaU1 Released🥳
📜We openly share our journey and observations of building this SOTA *native unified multimodal model* for both understanding and generation.
- Enjoy reading all the arch, data, training details👇
📄https://t.co/8IRFAmXJs5
🤩Excited to see that our native unified multimodal model #SenseNovaU1 is listed as *trending models* @huggingface
- Code: https://t.co/U2uOLI2gIj
- Model: https://t.co/pOfp37ZYe9
RIP Sora 2, Hello Seedance 2.0!
Seedance 2.0 achieves competitive score on VBVR-Bench.
Take an early peek at Seedance 2.0’s performance on video reasoning tasks.
👉 https://t.co/YruVq6iOWb
Thanks @_akhaliq for sharing! We’ve been exploring how to enable more human-like, interleaved thinking across text and images. U1 is our first step—still far from perfect, but we’re excited to open it up and collaborate with the community to improve it together.🤗
🔥Native Unified Multimodal Model Open Sourced🔥
🚀SenseNova U1🚀 is the first native multimodal model that unifies multimodal understanding, reasoning, and generation within a monolithic architecture.
- Code: https://t.co/56vtl0e6up
- Model @huggingface: https://t.co/6XJ8s2VYqt
🤩Try Now: https://t.co/RzAAFct7Qg
SenseNova U1 has been released and open-sourced. This is a milestone worth commemorating—not because we have built a perfect model, but because we have taken a critical step into a new era.
We believe that logical reasoning and visual intuition will become deeply integrated, and that the barriers between digital intelligence and physical intelligence will ultimately be broken down. Perhaps when we look back two years from now, this step we take today will prove to have been truly significant.
🤯Amazed by Image-2/NB 2, we kept asking: what’s the path behind them? We see native unified multimodal models as promising.
🚀Today, we open-source SenseNova U1, with solid und. & gen.(esp. Infographic & Interleaved). Hope to improve with the community toward Agentic Learning.🤝
SenseNova U1 with NEO-Unify just dropped 👀
• 🚫 No VE / VAE
• 🔗 End-to-end pixel–word modeling
• 🧠 Native multimodal reasoning (efficient & unified)
Moving from “multimodal integration” → “true unification”
Strong signal toward the next paradigm.
https://t.co/iTEyHh0N5m
Presenting our poster on ViMoGen at #ICLR2026@iclr_conf this afternoon! 🇧🇷
Stop by to chat about generalizable human motion generation, video generation, and the evaluation & data.
📍 Pavilion 4, P4-#3704
🕒 Today, 3:15 PM – 5:45 PM BRT
🔗 https://t.co/vwihLSW06N
🚀 Excited to share our #CVPR2026 paper: EmbodMocap: In-the-Wild 4D Human-Scene Reconstruction for Embodied Agents.
EmbodMocap, a portable yet affordable solution requiring only two moving iPhones—no calibrated multi-view camera studio, motion capture suits, or LiDAR sensors needed.
With our fully automated optimization pipeline, you can effortlessly obtain high-precision scene meshes, human interaction motions, RGBD images, and camera parameters.
The captured data is ready for training human-scene reconstruction models (like TRAM, pi3, etc.) and humanoid control policies (like deepmimic, AMP, etc.).
What you need to do:
1. Borrow or buy two iPhone 12 Pros from eBay (600 USD in total).
2. Find 2 friends, then capture the sequences.
3. Deploy our repo, run our code, and get the results!
The code and data will be released within 1 week. (Just come back to work from the Chinese Spring Festival, Happy Chinese New Year!)
📷 Project page: https://t.co/1soqR44lCJ
📷ArXiv: https://t.co/F2qp2deQ2m
📷Code: https://t.co/ZvdeiA3y8Z