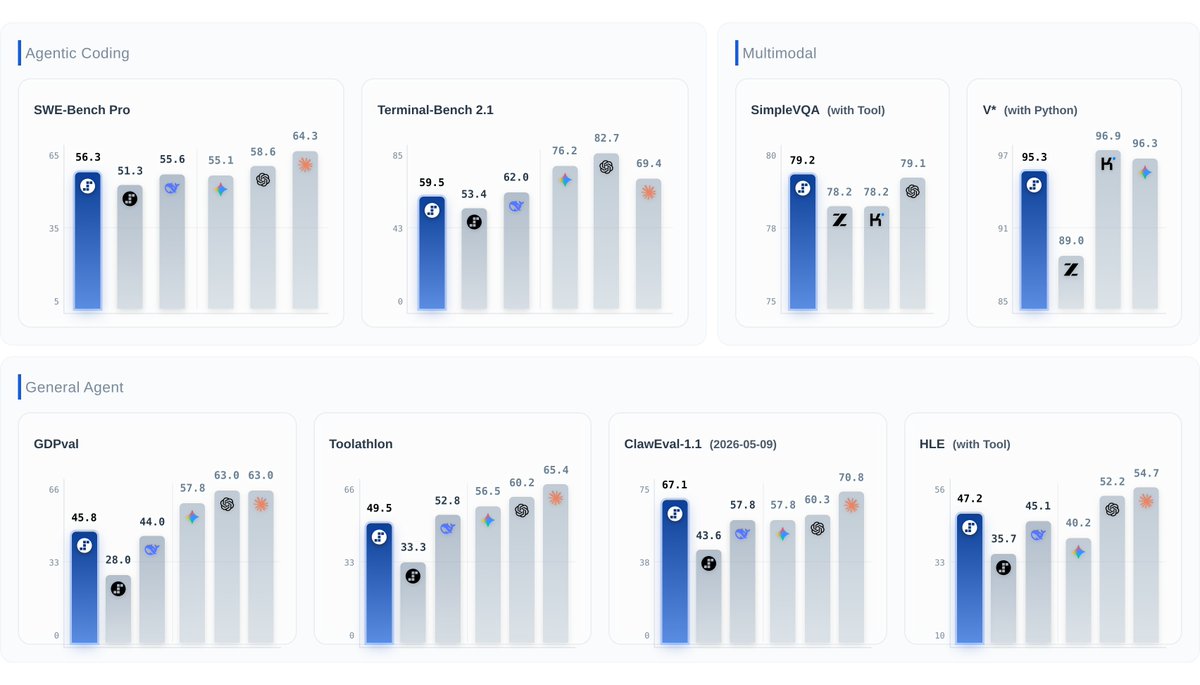
⚡️ Step 3.7 Flash is here: The new frontier is agent efficiency.
#1 ClawEval-1.1 (67.1), #1 SimpleVQA Search (79.2), #2 SWE-PRO (56.3), 95.3 on V* Python. Open weights under Apache 2.0.
Built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution.
- 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels.
- Understands UIs, charts, docs, images — then writes code or calls tools to act on what it sees.
- Web + visual search reaches further: more sources, deeper follow-up.
- Reliable tool use — less drift, fewer broken toolcalls. 98%+ on τ²-bench across all difficulty levels.
- Works with Claude Code, KiloCode, Hermes Agent, OpenClaw, and protocols like MCP.
- Runs locally on Mac Studio M4 Max, DGX Spark, AMD AI Max+ 395.
GitHub: https://t.co/kqlZkVIRHv
HuggingFace: https://t.co/qqceCrgPiw
GGUF: https://t.co/rR6XrnymWG
ModelScope: https://t.co/wney6Tzvqy
API: https://t.co/RvHWzRG7Fu
Blog: https://t.co/BxDiajiQ5G
Introducing 「XSafeClaw」: The Open-Source Agent Safety Platform Developed by Trustworthy AI research team at Fudan University.
Project: https://t.co/ahzsRQ2tYX
GitHub: https://t.co/Z9guHm1N5q
Thanks @HuggingPapers & @_akhaliq for sharing PixelSmile (based on Qwen-Image-Edit2511)
Unlike traditional image editing models that only achieve coarse expression changes, PixelSmile enables:
• Smooth, continuous control over expression intensity (reducing semantic blending)
• Strong identity preservation during editing
• Support for both real human faces and anime-style images
🔗 Homepage: https://t.co/Tk7GtjnWyw
💻 GitHub: https://t.co/8tfdYJzGpg
📄 Paper: https://t.co/TkH7JEw9YU
📚 arXiv: https://t.co/Mz2bigDo7Z
🎮 Demo: https://t.co/4j9095jHEV
PixelSmile
A diffusion framework for fine-grained facial expression editing with continuous intensity control and robust identity preservation across human and anime portraits.
Supports zero-shot expression blending and introduces FFE-Bench for comprehensive evaluation.
Step Plan is now live on StepFun Open Platform!!
Affordable OpenClaw and coding, all month.
What you get:
⚡ Step 3.5 Flash, fast inference on every tier.
🔧 Works with Cursor, Windsurf, Cline, and your own stack. Zero lock-in.
💰 Four tiers from $6.99/mo to $99/mo.
🔜 Multimodal flagship coming to the plan soon.
Check it out at: https://t.co/lmZtnHwSTb
Excited to share our latest work OmniLottie — the first end-to-end multimodal LLM that generates Lottie animations directly!
🚀Project: https://t.co/f16pfIau2Q
🚀 Live demo:
https://t.co/f55WSjYyok
🚨 BREAKING: Fudan University just solved the animation problem nobody thought AI could touch.
It's called OmniLottie
The first AI that generates real vector animations from text, images, or video.
Not rasterized video. Not GIFs. Actual Lottie files, the same format used by Airbnb, Google, Uber, and every major app on the planet.
Here's why this is a big deal:
Every animation you see in modern apps, loading spinners, onboarding flows, micro-interactions, icons that move, those are Lottie files. Designers spend hours crafting them in After Effects. Companies pay $5K–$20K per animation project.
OmniLottie generates them from a text prompt.
Here's how it works:
→ You describe what you want: "a rocket launching with flame trail and stars twinkling"
→ OmniLottie converts your instruction into structured animation commands
→ A custom Lottie tokenizer compresses the JSON into compact shape + motion tokens
→ A fine-tuned VLM autoregressively generates the full animation sequence
→ Output: a production-ready .json Lottie file you can drop into any app
Three modes:
Text-to-Lottie: describe it, get it.
Image+Text-to-Lottie: give it a reference image + motion description.
Video-to-Lottie: feed it a video, get a vector animation version.
Here's the wildest part:
They tested it against GPT-5, DeepSeek, Gemini, Qwen2.5-VL, and commercial tools.
GPT-5 success rate: 12.7–68%
DeepSeek: 29.3%
Qwen2.5-VL: 0.0%
Gemini: 0.0% on Video-to-Lottie
OmniLottie: 97.3% on Text-to-Lottie. 92% on Image-to-Lottie. 90.7% on Video-to-Lottie.
It's 530× faster than optimization-based methods per successful generation.
The secret weapon: a custom Lottie Tokenizer that strips all the redundant JSON metadata and converts animations into compact command sequences. Raw Lottie JSONs waste most tokens on formatting. The tokenizer focuses the model on what actually matters — shapes, motion, and timing.
They also built MMLottie-2M a dataset of 2 million professionally designed vector animations with text, image, and video annotations. The largest vector animation dataset ever created. Publicly released.
From Fudan University, StepFun, HKU MMLab, and University of Queensland.
Thank @_akhaliq for sharing!
We have launched a live Demo at: https://t.co/riYwuzGQmM Give it a try!
HF Daily: https://t.co/bRsxDKQd24
Paper: https://t.co/Cqpr8I3uJX
Project Page: https://t.co/OekdIrDEZV
Code: https://t.co/jZsHgB8P1q
🎉 CVPR 2026 | OmniLottie has been accepted!
We make lightweight, infinitely scalable, and fully editable vector animations ready for everybody!🚀
---
🔥 Why should you care?
Lottie = JSON-based vector animations used by Airbnb, Google, Uber, TikTok... basically everyone who wants smooth, tiny-file-size motion graphics for your apps & websites.
😨 Worrying about the complex animation logic? With OmniLottie, just write a prompt! ✨
---
🛠️ What we built:
✅ Lottie Tokenizer — 10x compression! We taught LLMs to easily understand complex JSON animation structures.
✅ Multimodal generation — Just one model for: Text → Lottie, Image → Lottie, Video → Lottie. 🎯
✅ MMLottie-2M Dataset — 2 MILLION high-quality multimodal vector animation pairs. Largest ever. We're releasing it ALL 📊
✅ Fully open-source — Model weights, inference code, dataset, benchmark, AND a live demo. No waitlists, no API keys, just vibes 😎
---
🎮 PLEASE GO PLAY WITH IT:
👉 Live Demo: https://t.co/gJWYrzLqct…
---
📎 All the links:
🤗 HF Daily: https://t.co/4kv0KbeVsA…
📄 Paper: https://t.co/5XCixuL0TG
🏠 Project Page: https://t.co/d6NaFLRwY4
💻 Code: https://t.co/jRNiyWWZLf…
---
⭐ If this is useful, drop us a star on GitHub!
We're hyped to push AI-generated vector animation forward with the community. Questions, feedback, wild use cases — we want to hear it all!
Let's make the web move beautifully 🌊
#CVPR2026 #Lottie #GenerativeAI #OpenSource #VectorAnimation
🚀 **OmniSVG Training Code is OUT!** 🎉
📅 Date: December 31, 2025
🎁 New Year's Gift for the Community!
---
We're thrilled to release the **official training code** of OmniSVG — you can:
✅ Train your own SVG generation models
✅ Fine-tune on custom datasets
✅ Reproduce our results from scratch
✅ Build upon our work freely
---
**Resource Link:**
🔗 **GitHub:** [https://t.co/W5ArNVTN0B](https://t.co/GZgXQoCCe9)
---
💬 Community feedback drove this release — thank you for your patience and support!
⭐ Don't forget to star the repo if you find it helpful!
🙏 Issues & PRs are welcome — let's push SVG generation forward together!
Thanks for sharing🤗 @_akhaliq@HuggingPapers
We are releasing WithAnyone, enabling single- or multi-person photo generation and editing with FLUX and Kontext on. Checkout our model, dataset, benchmark, and demo on huggingface:
📄 Paper: https://t.co/mJ5NlFrheZ
🤖 Models: https://t.co/uTqAkK7FX7
🧠 Dataset: https://t.co/KqqmixWrxw
📊 Benchmark: https://t.co/cB5POz48hj
🎮 Demo: https://t.co/wQCEje9uTp
https://t.co/lX7H41JQZf
We just released WithAnyone 🧑🤝🧑✨ — a new work tackling the copy-paste issue in face generation and enabling multi-person group photo synthesis.
Trained on FLUX & FLUX Kontext, supporting both face generation & editing.
All models, datasets, benchmark & demo are live on Hugging Face 🚀
📄 Paper: https://t.co/mJ5NlFrheZ
🤖 Models: https://t.co/uTqAkK7FX7
🧠 Dataset: https://t.co/KqqmixWrxw
📊 Benchmark: https://t.co/cB5POz48hj
🎮 Demo: https://t.co/wQCEje9uTp