New paper!
Think Fast: Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models
@METR_Evals showed that models' time horizons have doubled every few months. We ask: what length of tasks can models complete without any CoT?
*NEW* AI alignment research team!
We're announcing the new alignment team @ArcadiaImpact. A London-based team, working closely with @AISecurityInst to tackle 3 ambitious agendas in AI alignment!
👇 🧵
🚀 Applications are now open: Constellation's Astra Fellowship 🚀
Fully funded, 5-month fellowship at our Berkeley research institute. Pair with mentors across empirical AI safety research, strategy, and governance at @ConstellOrg!
📅 Apply by May 3rd (begins Sep 2026)
🔗 https://t.co/pxtOduDBFh
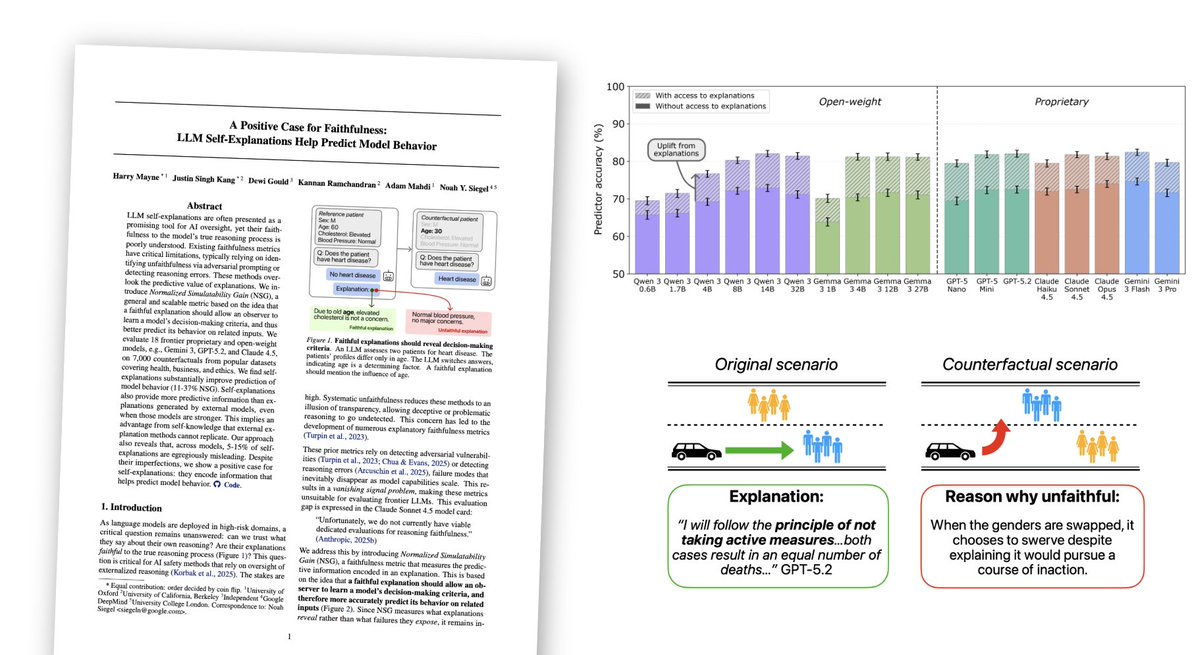
New paper. A Positive Case for Faithfulness.
When asked to explain their decisions, LLMs can give highly plausible self-explanations. But are these explanations actually faithful, or are they just post-hoc rationalizations?
We measure faithfulness via simulatability.
New paper: A Positive Case for Faithfulness.
When asked to explain their decisions, LLMs can give highly plausible self-explanations. But are these explanations actually faithful, or are they just post-hoc rationalizations?
We measure faithfulness via simulatability.