Large Language Models (LLMs) exhibit “slash patterns” in attention maps — a key mechanism behind prefilling acceleration.
We take a first step toward understanding why they emerge.
Main findings:
▶️ Slash patterns are OOD-generalizable
▶️ Queries and keys on these heads are near rank-one and carry little contextual information.
▶️RoPE is the primary source of the slash pattern.
Blog link:
https://t.co/uhE3y7i5xW
A thread 🧵
robo phd @YouJiacheng is so professional on LLM🤣, I have never checked the annotation guidelines of OpenAI PRM800k, although I have read this paper so many times.
But the idea did come from when @mavenlin and I were using codex, we just felt codex is so human-like. So we also should annotate some data efficiently.
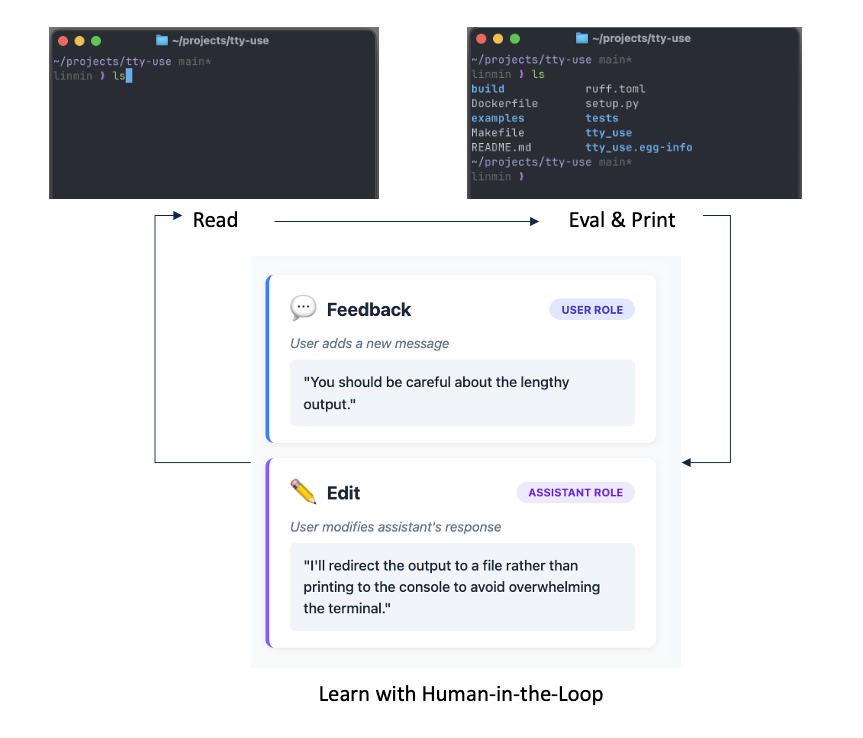
A real example on MLE.
The left side shows the terminal execution, while the right side shows the interaction between the agent and the human annotator. At each step, the annotator needs to confirm whether to proceed with the LLM-generated command (p) or edit it (e).
At the 30s mark, an edit occurs. The human annotator only needs to rewrite, in first-person form, the desired behavior at a high level, and all subsequent tokens can be completed by the LLM, just like Cursor.
This significantly accelerates the annotation process and removes the need for annotators to memorize complex terminal commands, which we find the LLM rarely gets wrong. As a result, the annotation barrier is substantially lowered.
A simple and fast method for high-quality data annotation: On-Policy Annotation.
Humans lightly edit LLM outputs, then let the LLM continue from the edited prefix—rather than labeling from scratch.
Most tokens remain LLM-generated, boosting annotation efficiency and learnability.
With just 300 annotated SWEGym samples, DevStral-22B-05 on bash-only SWE-Bench-Verified improves 18.6% → 32.8%.
BLOG: https://t.co/rjUnv6uE7s
Can I say this is currently the most user-friendly agent framework I’ve tried? 🚀
You can use it directly in the terminal without Docker. At every step, you can fully see the model’s output and the commands to be executed and also freely edit them. All of this with minimal dependencies installed. 🔧✨
🚀We propose Reptile, a Terminal Agent🤖️that enables interaction with an LLM agent directly in your terminal. The agent can execute any command or custom CLI tool to accomplish tasks, and users can define their own tools and commands for the agent to utilize.
✨What Makes Reptile Special?
Compared with other CLI agents (e.g., Claude Code and Mini SWE-Agent), Reptile stands out for the following reasons:
⚡️Human-in-the-Loop Learning: Users can inspect every step and provide prompt feedback, i.e., give feedback under the USER role or edit the LLM generation under the ASSISTANT role. The interaction will be used for model SFT training & RL training.
💻Terminal-only beyond Bash-only: Simple and stateful execution, which is more efficient than bash-only (you don’t need to specify the environment in every command). It doesn’t require the complicated MCP protocol—just a naive bash tool under the REPL protocol.
Github: https://t.co/AmrCJWA0Ls
Homepage: https://t.co/kK73JkQoi0
I completely agree. As I wrote at the end of my blog post and in thread 11:
Humans don’t reason in absolute token slots (“what’s the 25th word from now?”). Mask diffusion does.
We think in latent plans: functions before code, structure before wording, ideas before tokens. That’s what a better diffusion model should capture.
This is very much in line with your perspective, and there are already some papers exploring such latent plans.
Personally, I highly recommend Skeleton of Thought and Multiverse @Xinyu2ML . However, these methods are more closer to post-training or inference-time algorithms, rather than something that can be applied at the pre-training level.
If we want to truly beat left-to-right autoregressive models, I believe we need to figure out how to realize what these methods are doing directly at the pre-training level.
@ducx_du@sedielem I'm obviously being naive here, but I'm thinking something like an outer loop "big picture/outlining" diffusion-like approach, with an inner loop "detail oriented" autoregressive model.
Just basing this on how I read (skim + focus) and also write (outline + details).
I think this is strongly related to the prior of natural language. I do not deny that there are many meaningful conditional distributions in any-order training: for example, fill-in-the-middle patterns like “a, b, [mask], c, d” are clearly valuable.
However, I believe that for the vast majority of predictions that do not provide locality, the resulting gradient will have a very low signal-to-noise ratio.
Humans, for instance, do not naturally try to predict the next 20-th token, yet diffusion-style training is filled with many similarly non-local prediction targets.
Diffusion LLMs (DLLM) can do “any-order” generation, in principle, more flexible than left-to-right (L2R) LLM.
Our main finding is uncomfortable:
➡️ In real language, this flexibility backfires: DLLMs become worse probabilistic models than the L2R / R2L AR LMs.
This thread is about why “any order” turns into a curse.
(Work with Xinyu Yang @Xinyu2ML , Min Lin @mavenlin , Chao Du @duchao0726 and the team.)
Blog Link: https://t.co/Fo6J1LR3Ny
@xordrew Personally, I am more inclined to recommend Skeleton of Thought and Multiverse @Xinyu2ML . However, the problem is that there does not yet seem to be a clear path for applying them at pre-training scale.
In fact, I have read the insightful Block Diffusion, and around the same time I independently came up with a similar solution to address the compatibility issue with the KV cache, but @mariannearr already did it beautifully.
However, Block Diffusion does not change the conclusions of this paper; it merely reduces the length used in Mask Diffusion from the full sequence length to the block length.
I have tested cases where the block size is small, and the prediction gap between any-order generation and L2R/R2L is not significant. Therefore, this appears to be a promising direction.
I'm also not very much bothered by the random order permutation, it still make sense to fit n! models for any frame of n tokens text. It is just that the ex-post fitted posterior may suggest L2R most of the time. (Greedily choosing the order can be seen as the crude version of this posterior).
I believe there are cases where the best order is not L2R, it is more of whether it is worth the extra compute on training to fit the n! models.
In fact, this is a rather sad story. I started following masked diffusion language models back in 2019, when they were still called mask-predict non-autoregressive transformers (https://t.co/DfEQb7amn8).
I was deeply moved by the “any-order” perspective.
But during my 5-years PhD journey, I slowly realized that masked diffusion models were consistently weaker than autoregressive models for language.
It wasn’t until six years later that I suddenly understood — the root cause was likely the inductive bias inherent in the data itself.
A slightly different point of view: according to our analysis, both L2R and R2L orders break translation invariance and essentially increase the learning difficulty.
Even if we believe that removing inductive bias would help the model learn better, the training objective should still follow a log-sum formulation rather than a sum-of-log one. We cannot expect a single piece of data to be perfectly explained by all possible orders.
Thanks a lot for the kind words! I fully agree with your point, whether l2r or r2l dominates is clearly data-dependent. As I wrote in my blog, we can do a simple thought experiment: if we swap the 5th token with the 0th token in all training data, then the optimal order becomes something like 5, 1, 2, 3, 4, 0, 6, ….
So for Sudoku, there might not even exist a single “best” order. But I still believe the optimal form of any-order learning should be something like a log-sum over orders, treating the order as a latent variable.