🧵 Deli AutoResearch SKILL is now officially open source! 🎉
https://t.co/V3lwwdyQm8
Alongside it, we’re dropping our 4th survey paper — this time on Self-play.
https://t.co/SEb2qoKCI6
Inspired by AlphaZero, we got a powerful insight: prior knowledge doesn’t always lift the ceiling.
Models can discover more globally optimal solutions just by playing against themselves.
The biggest change in this paper?
For the first time, the AutoResearch Agent autonomously planned GPU experiments — and submitted actual RL runs on the DeepSeek 285B model.
The entire RL pipeline — experiment design, code writing, running, debugging, and conclusion summarization — was 100% automated, with zero human intervention from me.
This was incredibly difficult, but an incredibly important step.
https://t.co/kuZZNux5RH
GRPO is the tool being called by the AutoResearch Agent here.
We see this as the beginning of our Continual Learning research journey. 🚀
As always, this is my personal research project, unaffiliated with any organization. All views are my own.
#AI #ReinforcementLearning #SelfPlay #OpenSource #AutoML #ContinualLearning #DeepSeek
I’m excited to share that I’ll be joining OpenAI and look forward to working with the exceptional team there.
It was a difficult decision to move on. I’m incredibly proud of the amazing team at Google and everything we’ve built together. It has been an honor and a pleasure to work with all of you.
最近在带入组的本科实习生,发现怎么读论文其实是科研训练里最容易被忽略的一步。
推荐一篇每个科研新人都该读的经典短文:S. Keshav 的 How to Read a Paper。
文章提出了非常实用的“三遍读论文法”:
第一遍,5 到 10 分钟快速扫读:标题、摘要、引言、章节标题、结论和参考文献。
目标是回答 5C:
Category, Context, Correctness, Contributions, Clarity。
也就是判断这篇论文是什么、和谁相关、假设是否合理、贡献是什么、写得清不清楚。
第二遍,认真读论文主线,但先跳过证明细节。重点看图表、实验设置、结果是否清楚、引用了哪些关键工作。
第三遍才进入深度理解:尝试像复现一样重建作者的思路,检查假设、方法、创新点和潜在漏洞。
放在今天看,这个方法和 AI 辅助读论文其实很契合。
第一遍可以让 AI 帮忙快速总结论文的研究问题、核心贡献和主要结论,但自己一定要判断这篇文章是否真的值得继续读。
第二遍可以让 AI 帮忙解释方法、实验设置、图表和不熟悉的概念,但不能只看 AI 总结。关键图表、实验设计和结果数字一定要回到原文核对。
第三遍可以让 AI 扮演 reviewer,帮你追问:这篇文章的假设是否成立?实验是否支持结论?有没有 missing baseline?有没有潜在的数据泄漏、评价偏差或过度 claim?
读论文不是“读完”就行。真正重要的是知道什么时候快速跳过,什么时候认真理解。
尤其在 AI 工具越来越强的情况下,科研新人更需要训练自己的判断力。
AI 可以帮你压缩信息,但不能替你决定一篇论文是否重要、是否可信、是否值得借鉴。
https://t.co/8gUc4HbLwR
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: https://t.co/bwn0sximKZ
I want to say a final thing about my Fable first reaction: I dedicated my life to programming and I'll use every innovation in the field, also to extract value and bring it to the local inference world, to Redis, and so forth. But:
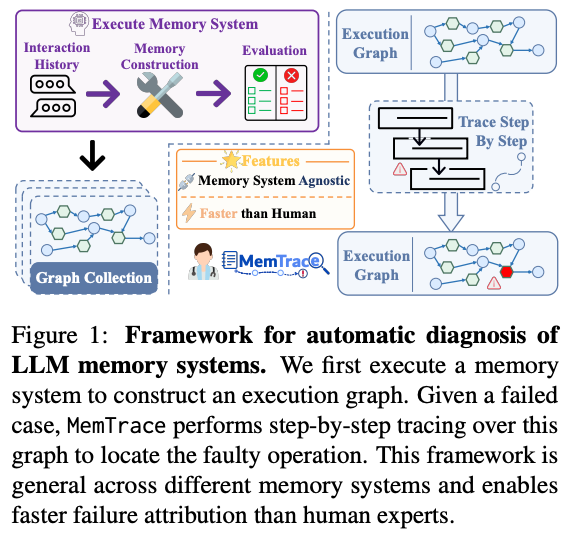
Introducing MemTrace: Making LLM Memory Systems Finally Debuggable 🔍🧠
Memory is becoming a core component of AI agents. But today’s memory systems are still a "black box".
When a memory-augmented agent fails, the real error may have happened:
- dozens of turns earlier,
- inside a retrieval step,
- during memory consolidation,
- or from a corrupted update that silently propagates over time.
Existing logs cannot recover these long-range causal chains.
MemTrace changes this.
We introduce the automated tracing framework for LLM memory systems — turning opaque memory pipelines into transparent execution graphs that can be inspected, explored, and diagnosed step by step.
⚡ What MemTrace enables:
🧩 Plug-and-Play Instrumentation
Seamlessly integrates with diverse memory systems (RAG, Mem0, EverMemOS, etc.) without modifying the original architecture.
🧠 Transparent Memory Execution
Transforms opaque memory pipelines into structured execution graphs, making information flow, retrieval, updates, and propagation fully traceable.
🔍 Error Attribution
Pinpoint the exact operation responsible for failure across long-horizon memory execution.
🚨 Benchmark Auditing
While building MemTraceBench, we found that failure attribution in memory systems remains highly challenging — MemTrace still has substantial room for improvement.
We also discovered annotation errors in existing memory benchmarks, revealing broader reliability issues in current memory-agent evaluation.
🔄 Towards Self-Evolving Agents
MemTrace is not only a debugging tool.
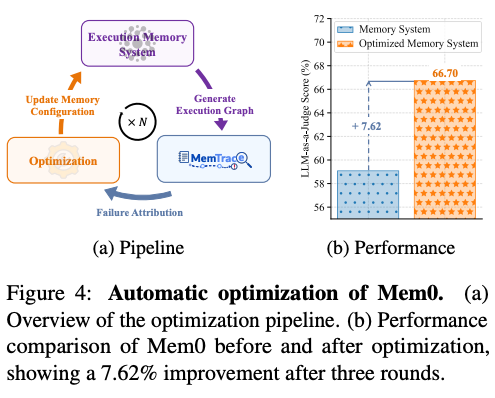
Its fine-grained attribution signals can directly drive closed-loop optimization, enabling agents to automatically repair faulty behaviors and continuously evolve from failures.
📈 Using MemTrace-guided optimization, we improve downstream task performance by up to 7.62%.
📖 Paper: https://t.co/48arX35l1m
⌨️ Code (coming soon):
• MemTrace: https://t.co/pm0JLSpLLr
• smartcomment: https://t.co/ieLcwGFHtY
• MemBase: https://t.co/GX1w7ImczE
We believe memory systems need the same thing software engineering once needed:
not bigger models — but observability, tracing, and debugging infrastructure. #MemTrace #LLM #NLP #Agent #Tracing #Debugging
I've been on a wild travel journey in China for several weeks, with only a backpack, making new friends and meeting & getting to know people from all walks of life. I've been truly humbled and inspired by everyone's kindness.
Next, I'm hopping over to Taiwan (first time for me) to hang out with Jensen, attend Computex, eat a bunch of street food, and just have fun talking to all kinds of folks around the city & beyond. After that, no plans, anything goes.
As always, please give travel suggestions or fill out coffee form if you want to hang out in Taiwain or anywhere else in the world. Love you all! ❤️
franchement l'annonce de Huawei hier à Shanghai vient de mettre noir sur blanc ce que j'essaie de vous faire comprendre ici depuis des années
pour vulgariser Huawei vient d’annoncer au sympoisum ieee iscas une nouvelle loi physique qui remplace la loi de moore, ils l’appellent la tau scaling law et elle change littéralement le paradigme du semiconducteur mondial, en gros au lieu de continuer à rétrécir les transistors ce qui se heurte à des limites physiques quantiques infranchissables, ils optimisent dorénavant la constante de temps tau à 4 niveaux simultanément et obtiennent des gains de performance équivalents à ce que les américains atteignent avec leur lithographie euv à 200 millions de dollars la machine, sauf qu’eux n’ont pas accès à cette lithographie depuis les sanctions de 2019
la Chine dépasse donc la silicon valley sur son propre terrain et la rend périmée et ce qui se joue réellement est l'exact contraire de ce que Washington imaginait en décidant des sanctions de 2019
en ce sens je crois que très peu de gens ont pris la peine de regarder vraiment les slides de la présentation parce que le coeur de la rupture se cache ailleurs que dans le concept marketing de tau scaling law, il se trouve dans un détail technique que seuls quelques ingénieurs spécialisés ont remarqué (et que je suis parti fouiller haha), il existe visiblement un procédé de collage entre couches de silicium avec un espacement + petit que 2 micromètres, ce qui transforme les fils verticaux reliant les différentes couches d'une même puce en chemins de calcul à part entière, ils maîtrisent là l'intégration en 3 dimensions au sens fort pendant que le reste du monde raisonne encore sur un seul plan horizontal
pour moi la meilleure image c'est celle d'un architecte qui construit une tour pendant que ses concurrents continuent d'étaler des maisons individuelles à l'horizontale, intel et tsmc se battent pour graver des transistors toujours plus minuscules parce que leurs lithographies euv les enferment dans cette logique, huawei coupé de ces lithographies depuis 2019 a choisi un autre combat, raccourcir au maximum le temps qu'un signal électrique met pour traverser l'ensemble du système, cette durée qu'ils nomment tau et qu'ils minimisent simultanément au niveau du composant du circuit de la puce et de la machine complète, c'est de la physique réelle présentée dans la conférence ieee la plus sérieuse au monde sur le sujet
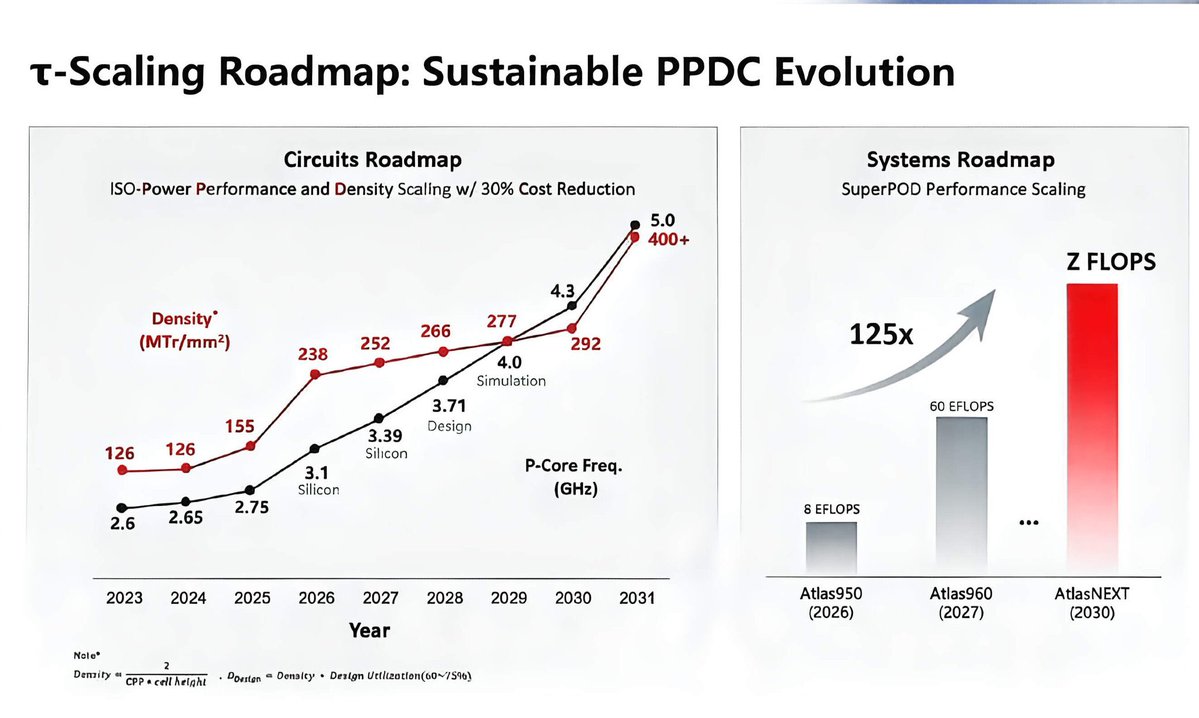
d’ailleurs les chiffres font réfléchir, allez jeter un coupé d’œil et vous allez voir que la densité de transistors monte de 126 à plus de 400 millions par millimètre carré entre 2024 et 2031, la fréquence des coeurs grimpe de 2,6 à 5 gigahertz, même la performance des systèmes complets fait x125 en 4 ans entre 2026 et 2030 & surtout 381 puces ont déjà été fabriquées en série selon ces principes depuis 2020, autant dire qu'ils ont commencé à changer de paradigme dès la première vague de sanctions américaines, 6 années de travail discret pendant que les analystes occidentaux les croyaient en mode survie mdr ce que tout le monde prenait pour de la résistance était en réalité un virage stratégique médité et mené avec la patience d'un peuple qui voit à 50 ans (la vision à très long terme de la Chine dont je vous parle souvent )
je vous le répète depuis des années ici, les sanctions occidentales accélèrent la politique industrielle et tech de Chine au lieu de la freiner, elles l'obligent à inventer le monde d'après pendant que l’occident reste coincé dans celui d'avant, d’ailleurs pour info même BYD a créé la batterie LFP face au blocage du nickel et il domine désormais le marché mondial de la voiture électrique, deepseek a conçu son architecture multi-head latent attention face au blocage des puces h100 et il a divisé par 10 le coût des grands modèles de langage, Huawei vient de poser logicfolding et tau scaling face au blocage de l'euv et il redessine déjà la trajectoire mondiale du semiconducteur jusqu'en 2031