The internet tells you to validate before you build.
Sometimes the fastest way to validate is to build the damn thing.
You learn more from 1 week of shipping than 3 months of planning.
which can be loaded into cache somehow but even if we managed to do that we could only do that for one token after activation vector is multiplied with weights its useless and should be disregarded because its in cache and you need it again when you do the same ops another token
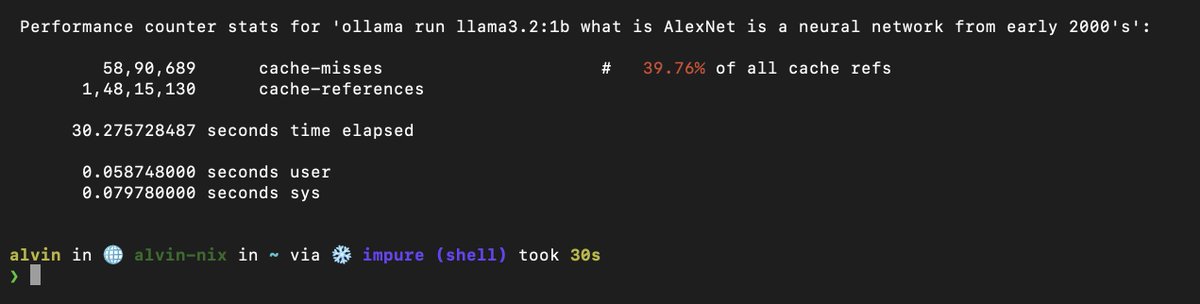
Ran a 1B parameter LLM on my CPU and profiled it.
30 seconds total. 0.058 seconds of actual compute.
39.76% cache miss rate. The CPU spent 99.8% of the time waiting for data.
Inference isn't slow because your CPU is weak. It's slow because weights can't move fast enough from RAM.
Modern Computer architecture works on assumption that if you access X, then you'll prob access X again sooner and it works like magic fuck that was genius but when itcomes to llm for the the weights size is in megabytes
wrote forward propagation by hand on paper today just to actually understand it. not gonna lie derivatives and the idea of slope finally clicked. building toward making inference cheaper on my RX 7600. Maybe JUST maybe its a pipedream but whatever...