1/7 If Andrew Ng is right that the LR is the most important ML hyperparam, it's got some competition! We show that the softmax temperature is a game-changer in crafting NN representations. Often overlooked, it quietly governs generalization, collapse, and compression. A thread 👇
Introducing RND1, the most powerful base diffusion language model (DLM) to date.
RND1 (Radical Numerics Diffusion) is an experimental DLM with 30B params (3B active) with a sparse MoE architecture.
We are making it open source, releasing weights, training details, and code to catalyze further research on DLM inference and post-training.
We are researchers and engineers (DeepMind, Meta, Liquid, Stanford) building the engine for recursive self-improvement (RSI) — and using it to accelerate our own work. Our goal is to let AI design AI.
We are hiring.
Can we catch an AI hiding information from us?
To find out, we trained LLMs to keep secrets: things they know but refuse to say. Then we tested black-box & white-box interp methods for uncovering them and many worked!
We release our models so you can test your own techniques too!
Sparsemax is interesting as it preserves 1) the uniformity of softmax for low norms, but, as you mentioned, 2) it can achieve sharp output for finite norms in contrast to softmax.
For the rank deficit bias, the 2nd property is not that important. What matters is the 1st property and the behavior "between the limits". I ran a quick test, and Sparsemax seems to have even greater ability to scale up rank compared to softmax (first Figure), which suggests that it also should exhibit rank-deficit bias. A quick example with DLNN on a toy dataset seems to confirm this (second Figure).
Thanks again for this question!
1/7 If Andrew Ng is right that the LR is the most important ML hyperparam, it's got some competition! We show that the softmax temperature is a game-changer in crafting NN representations. Often overlooked, it quietly governs generalization, collapse, and compression. A thread 👇
@LukaszBorchmann Good question! We haven't tested sparse variants in this project, so I can only guess. I'd expect that applying (random) sparsity should increase pre/post-softmax rank, but besides this, I would expect similar behavior. What "issues" do you expect to fix with sparse-softmax?
1/7 If Andrew Ng is right that the LR is the most important ML hyperparam, it's got some competition! We show that the softmax temperature is a game-changer in crafting NN representations. Often overlooked, it quietly governs generalization, collapse, and compression. A thread 👇
Want the deep dive? Check the paper on arxiv: 2506.01562
Moral of the story? Stop tuning LR first—experiment with temperature today. And if you’ve seen temp save (or ruin) your model, share below! 👇
🔥 New Paper!
How can sparse autoencoders (SAEs) applied to diffusion models help us solve real-world challenges?
🚀 Introducing 𝗦𝗔𝗲𝗨𝗿𝗼𝗻: We use SAEs for unlearning in diffusion models and outperform existing baselines!
Here's how it works:
🧵 1/
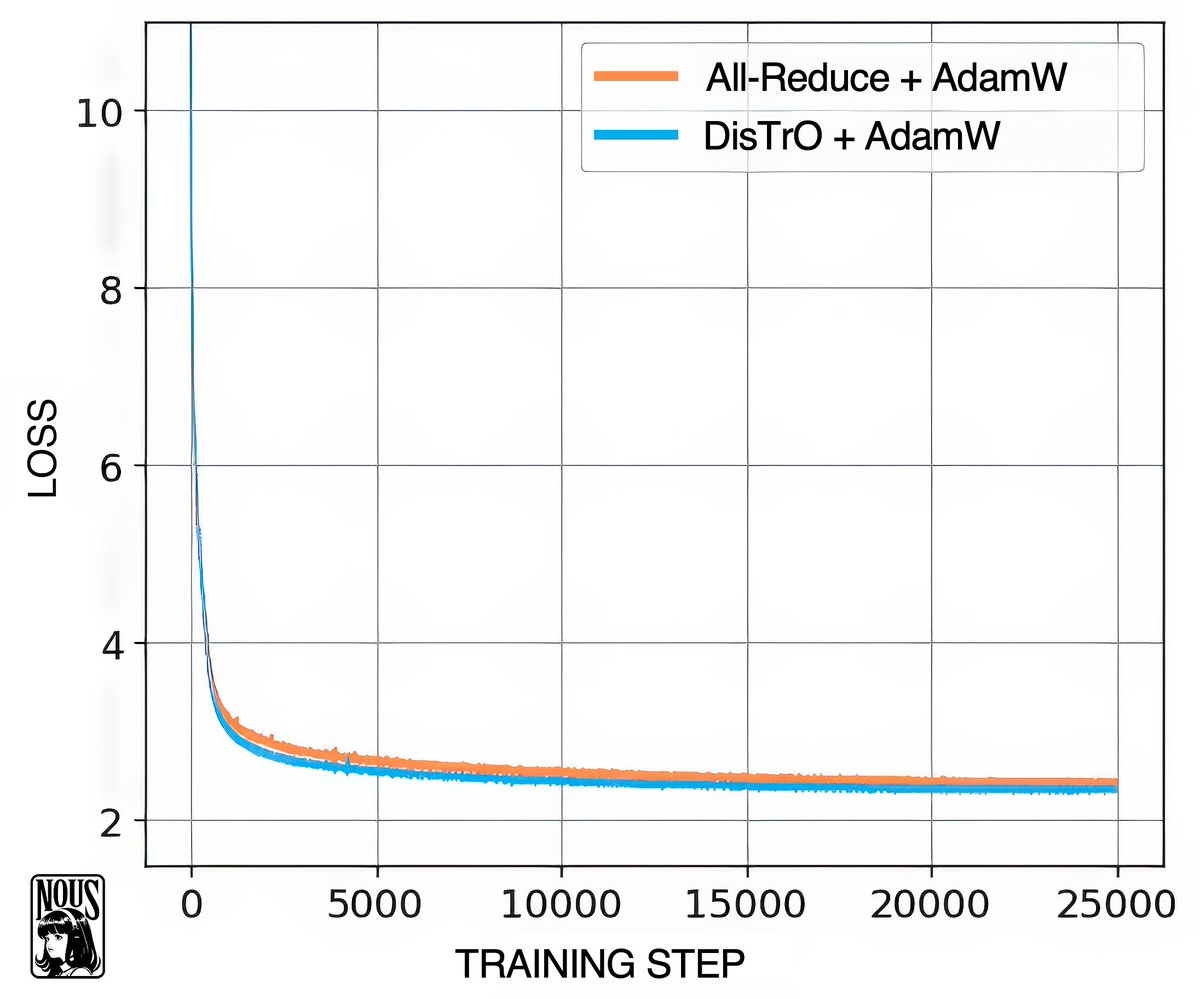
What if you could use all the computing power in the world to train a shared, open source AI model?
Preliminary report: https://t.co/4Rhd0ddp9z
Nous Research is proud to release a preliminary report on DisTrO (Distributed Training Over-the-Internet) a family of architecture-agnostic and network-agnostic distributed optimizers that reduces the inter-GPU communication requirements by 1000x to 10,000x without relying on amortized analysis, and matches AdamW+All-Reduce in convergence rates. This enables low-latency training of large neural networks on slow internet bandwidths with heterogeneous networking hardware.
DisTrO can increase the resilience and robustness of training LLMs by minimizing dependency on a single entity for computation. DisTrO is one step towards a more secure and equitable environment for all participants involved in building LLMs.
Without relying on a single company to manage and control the training process, researchers and institutions can have more freedom to collaborate and experiment with new techniques, algorithms, and models. This increased competition fosters innovation, drives progress, and ultimately benefits society as a whole.
This research is thanks to the hard work of @bloc97_@theemozilla@apyh__@UmerHAdil.
We invite researchers interested in exploring this area to join us in our quest.
My group has multiple openings both for PhD and Post-doc positions to work in the area of optimization for ML, and deep learning theory. We are looking for people with a strong theoretical background (degree in math, theoretical physics or CS with strong theory emphasis).
Excited that my new paper on understanding LLMs is out, pushing how far we can describe LLM predictions via simple statistic rules. Bonus: I also discover a novel way of detecting overfitting *without* using a holdout set. So are LLMs just stochastic parrots? You be the judge. 1/
Many people start attacking a problem by deploying the most sophisticated method possible with the belief that it will lead to the best results. I believe it might be better to chisel away at the complexity and find the simplest possible combination that expresses the key ideas.
Every day I witness the AI revolution in action, and every day I see 1 or 2 questions that would deserve an entire PhD thesis to explore fully ... Honestly, how lucky we are to do research in that era!!
*Even if* there is no more magical leap like from gpt2 to 3, or 3 to 4, there will still be work for a couple more generations of AI researchers just to digest and maximally leverage current technology.