Research Scientist at @AIatMeta @meta | ex Ph.D. at @uncnlp @unccs | ex M.S. at @uchicagocs @uchicago | Past Intern at @AIatMeta @microsoft | #NLProc & #AI
Claim: Autoresearch that moves the frontier will be about better data: we call that *Autodata*.
🧵1/6 -- Paper is out! https://t.co/b8gOALndzy
Key idea: agentic data creation provides a way to *convert increased inference compute into higher quality model training*.
We show our method gives gains on computer science, legal and math problems over classical synthetic dataset creation methods.
We also show how to train (meta-optimize) such a data scientist agent, so that it can create even stronger data.
Overall, we believe this direction has the potential to change how we build AI data!
Continual learning in production FTW (with humans-in-the-loop) – a detailed report on methods to iteratively improve LLM social dialogue served to millions of users based on their interests.
Personally, I've been working on pushing this direction for the last 10 years(!) (see papers below)! so it's exciting to see this stuff working in real systems. It will only get better -- lots more exciting methods now to try and more powerful models to make methods work than when I started.
Some of my historical(!) research in this direction:
2025:
The Era of Real-World Human Interaction: RL from User Conversations
https://t.co/wmC2fVB0zu
2022:
When life gives you lemons, make cherryade: Converting feedback from bad responses into good labels
https://t.co/kJCanILmww
Learning new skills after deployment: Improving open-domain internet-driven dialogue with human feedback
https://t.co/2uJ88MzNRw
2020:
Deploying lifelong open-domain dialogue learning
https://t.co/0HiqfIAhpF
Open problems in continuous learning:
https://t.co/zAKl9WudAe
2016-2019:
Learning from dialogue after deployment: Feed yourself, chatbot
https://t.co/wrgByMfKFM
Unlikelihood training
https://t.co/KHACH5aqRd
Dialogue learning with human-in-the-loop
https://t.co/7PkrroT8TI
5/5 Beyond the numbers, we hope this work contributes toward the scientific rigor of optimizing subjective engagement in production LLMs.
Unlike math or code, conversational AI lacks objective benchmarks and verifiable reward signals. Yet millions interact with these systems daily — and rigorous documentation of how to measure and improve them remains scarce in the literature.
1/5 🤔 LLMs can solve olympiad math and write production code. But can they hold a conversation that's actually fun — one that people want to keep coming back to? 💬✨
We present CharacterFlywheel— an iterative process optimizing LLMs for real human engagement and character steerability, while maintaining rigorous safety protocols 🔒. Tested across Instagram, WhatsApp & Messenger 📱with millions of users — where they can create, share, and chat with their own AI characters 🤖.
📄 paper: https://t.co/WJ9xKz89Dt
https://t.co/9lA3DdkWuM
4/5 Post-launch (V8–V15), 7 of 8 deployed models showed positive engagement lift in controlled A/B tests, with top performers achieving +8.8% breadth and +19.4% depth 🔥.
One release (V12) was a useful miss 🚨: RM win rate jumped to 70.7% while engagement declined—classic reward overfitting ⚠️. Takeaway: keep RM win rates below ~65% ✅. Subsequent versions recovered.
Overall, engagement has trended upward across 9 months of deployment 🚀
Our latest work sheds light on what to "scale" when building generalizable agents:
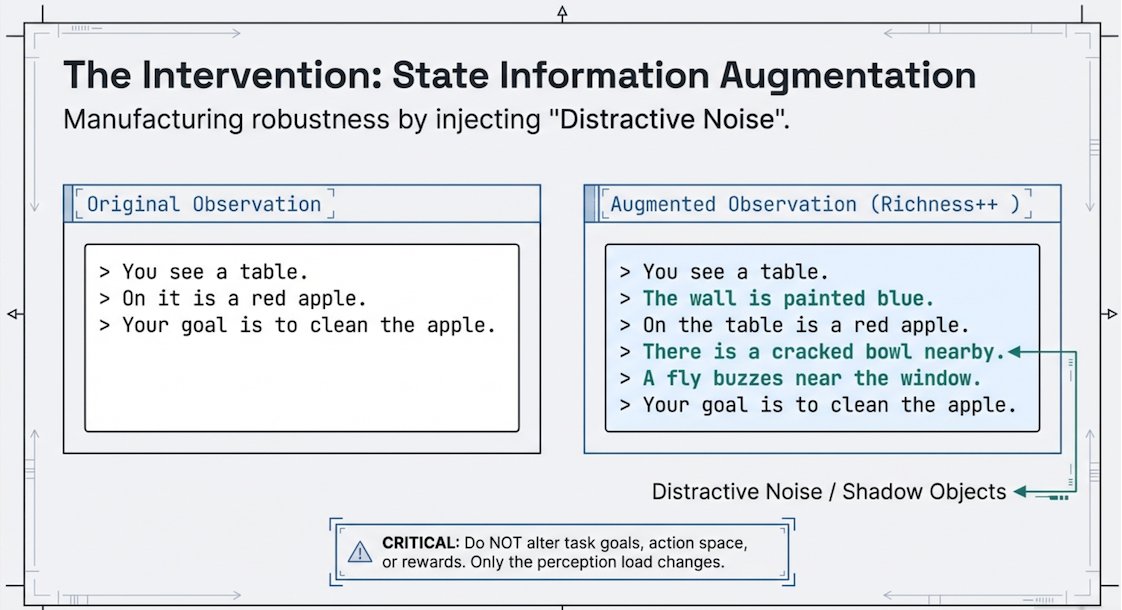
👉 Prefer training envs with 📚 high state information richness (high perception load & info volume) + 🧠high planning complexity (long task horizon & branching factors)
👉 The *complexity structure* matters more than realism: Hard problems in "toy" domains like Sokoban / BlocksWorld can be more useful than easy problems in more realistic domains like ALFWorld.
‼️📉 Be careful about your mid-training datamix and strength: warmup and mid-training help prevent catastrophic forgetting during RL but undermines generalization to domains that are not covered
💡Applying lightweight state randomization/augmentation helps!
📄 Paper: https://t.co/qmaIjMFYwJ
People are putting lots of efforts into building diverse RL environments. But what kinds of environments are more useful for building **generalist** agents that are able to solve tasks beyond their training tasks?
🚀 Instead of optimizing one single benchmark, we look for drivers of transfer in our latest paper: https://t.co/cpgXXbiday
Joint work with MSL @MetaAI (@ZhihanLiu21628@GuanSuns@EasonNie@KaiZhang_CS@nazzhang) where @ZhihanLiu21628 interned. (1/n)
Excited to share our new work!
DOVE 🕊️: a dynamic vision encoder that adapts token count to image complexity. Fewer tokens, same fidelity—outperforming fixed-length AEs tokenizer on classification & VLM tasks!
Arxiv: https://t.co/8qTZARXsCl
Web: https://t.co/HPCTctwyVx
#AI#CV
🚨Announcing RAM 2 workshop @ COLM25 - call for papers🚨
- 10 years on, we present the sequel to the classic RAM🐏 (Reasoning, Attention, Memory) workshop that took place in 2015 at the cusp of major change in the area. Now in 2025 we reflect on what's happened and discuss the future of these topics.
🌐: https://t.co/tXHeQD8Xek
=======
Ten years ago… in Montreal 2015, the RAM workshop took place to bring together the burgeoning field covering the “interplay of reasoning, attention and memory”, just before Transformers were invented – but when many of the components to get there had just been published and were in place. The workshop included many speakers who are still prominent in pushing these directions today: Yoshua Bengio, Kyunghyun Cho, Jürgen Schmidhuber, Sainbayar Sukhbaatar, Ilya Sutskever, and more.
Ten years later… we are hosting RAM 2 in the same location in Montreal, with a two-fold purpose. Firstly, as a retrospective and analysis of what has happened in the last 10 years. We are inviting presenters from the first workshop to this end, as well as to add their current perspectives. Hence secondly, and more importantly, we will bring together the field to discuss new trends and future directions for the next 10 years – which is further enabled by inviting new speakers, panelists and poster presenters discussing these fresh ideas.
Why does this make sense? The RAM topic is as important as ever, and has gone on to dominate the field.
These new directions include:
R: New reasoning methods including both token-based and that use continuous vectors, and how they combine with memory.
A: New attention methods that enable better reasoning and use of short and long-term memory.
M: Architectural changes to LLMs to improve memory and reasoning capabilities.
Overall, we highlight that the workshop is most concerned with methods that aim to explore the interplay between these three aspects.
==Workshop Event==
Location: Palais des Congrès, Montreal, Canada
Date: October 10, 2025
==Call for Papers==
We will host paper submissions on open review (link to appear here soon). We invite researchers and practitioners to submit their work to the COLM 2025 Workshop on Reasoning, Attention & Memory 2 (RAM2@COLM25).
Submission Deadline: June 23, 2025
Author Notification Deadline: July 24, 2025
Submission Details: Submissions should follow the general guide for COLM conference. Papers can be up to 9 pages (not including references) and have to be anonymized. All submissions must be in PDF format, please use the LaTeX style files provided by organizers.
==Invited speakers==
Yoshua Bengio @Yoshua_Bengio
Kyunghyun Cho @kchonyc
Yejin Choi @YejinChoinka
Azalia Mirhoseini @Azaliamirh
Juergen Schmidhuber @SchmidhuberAI
Sainbayar Sukhbaatar @tesatory
Jason Wei @_jasonwei
==Organizing Committee==
Ilia Kulikov @IliaKulikov
Jason Weston @jaseweston
Jing XU @jingxu_ml
Olga Golovneva @OlgaNLP
Swarnadeep Saha @swarnaNLP
Marjan Ghazvininejad @gh_marjan
Ping Yu @ping_iris_yu
We just open-sourced the first 3D model dataset for Objaverse with quality annotations!
If you are a researcher or a company looking to train your text-to-3D or image-to-3D models, this dataset may help. You’ll use our dataset to filter out only the high quality objects suitable for AI training - it’s better and faster.
#cvpr #machinelearning #ai3d #ArtificialIntelligence #computervision
We are thrilled to announce TULIP!
🌷 https://t.co/gNVVbDzze1
A state of the vision language encoders coupled with generative model for stronger representation learning.
🚀Hitting a plateau in code generation due to the lack of high-quality data? What if we let LLMs generate and verify coding data themselves?
😅Fun fact: LLMs are like devs - great at coding, but reluctant testers! Their test generation lags far behind their coding ability.
💡Our solution: 𝑺𝒐𝒍-𝑽𝒆𝒓 - A self-play framework where LLMs learn to solve and verify themselves for code/test generation tasks! No human-annotated data or teacher models are needed for training!
* LLMs act as both code solver & verifier
* Self-play between coding & testing -- both improved over iterations!
📖For more details, check out our paper here: https://t.co/ngygACJgwE
Joint work with @shengs1123@shangjingbo@jaseweston@EasonNie
I’m really sad that my dear friend @FelixHill84 is no longer with us. He had many friends and colleagues all over the world - to try to ensure we reach them, his family have asked to share this webpage for the celebration of his life: https://t.co/1QoyHmAD3p
I loved working on this project investigating how we can use NLI datasets to investigate LLMs. Particularly excited to see how they still are providing a relevant signal, and how match alignment of model distributions with humans has much improved but is far from solved
Today we are releasing code, models & data from the Self-Taught Evaluator paper, a method to train LLM judges with synthetic preference data.
Better model trained with DPO: https://t.co/oGW56tGXNR
Synthetic preference data: https://t.co/ixz4kSlVgg
Code for training and inference: https://t.co/3NQtG6RY9y
Since we released the paper detailing the method to generate synthetic data, the community has also used this approach to build improved RMs (https://t.co/4sLVBwuKxk).
Our DPO model is a strong LLM judge on RewardBench, despite not using any human annotation in training data creation. We are releasing the training data, training and evaluation code to reproduce our results.
The model is also available as an evaluator on the AlpacaEval leaderboard, as one of the top-ranked evaluators in terms of human agreement rate: https://t.co/KJCrL5Ssid
You can also read the original paper here: https://t.co/aFpnt56TEk
What wonderful news! Our paper VariErr (Variation vs Error) NLI got an #ACL2024NLP area chair award 😍
So thankful to the best paper award committee, the RQ is so close to my 🧡
Congrats to the amazing VariErr team @weberple@Logan_SiyaoPeng Marie-Catherine de Marneffe 👏
fyi: Meta's funding a few new grants for faculty to create evaluation benchmarks (deadline Sept 7). Could be of interest! #NLProc
https://t.co/7JPz95o41C