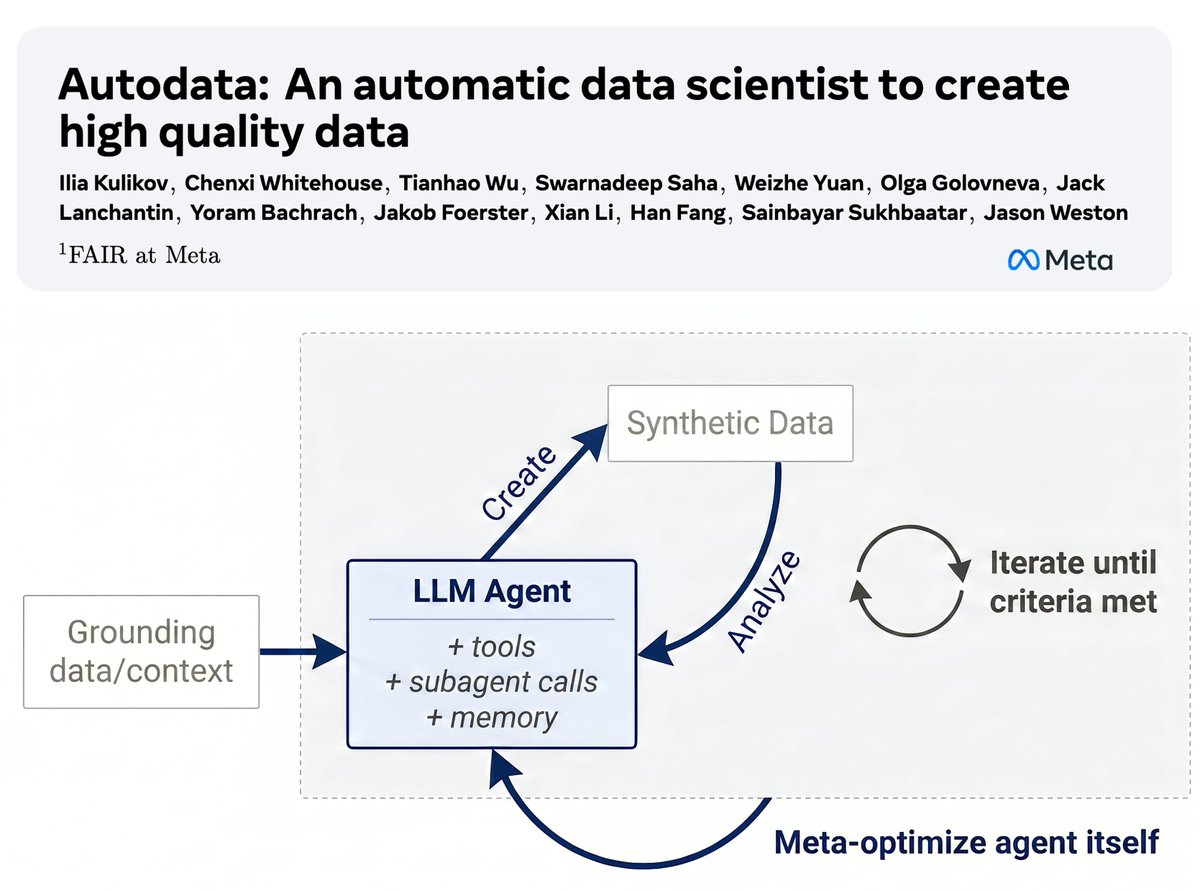
💎Autodata: an agentic data scientist to create high quality data✨
We introduce a method for building agents that create high-quality training & evaluation data.
Key idea: agentic data creation provides a way to *convert increased inference compute into higher quality model training*.
We show how to train (meta-optimize) such a data scientist agent, so that it can create even stronger data.
Our initial study with a specific practical implementation, Agentic Self-Instruct, shows strong gains on scientific reasoning problems compared to classical synthetic dataset creation methods.
Overall, we believe this direction has the potential to change how we build AI data!
Read more in the blog post: https://t.co/vjPvnTYfJx
DeepSeek-V4 uses our Hash routing approach developed back in 2021 -- see screenshot of their tech report! (Looks like a great model, congrats!)
Bonus note: our same blogpost (& paper) back in 2021 also introduced 'looped transformers', but we called that staircase & ladder (see screenshot): https://t.co/widkeEXz56
https://t.co/PQLdPKg9PS
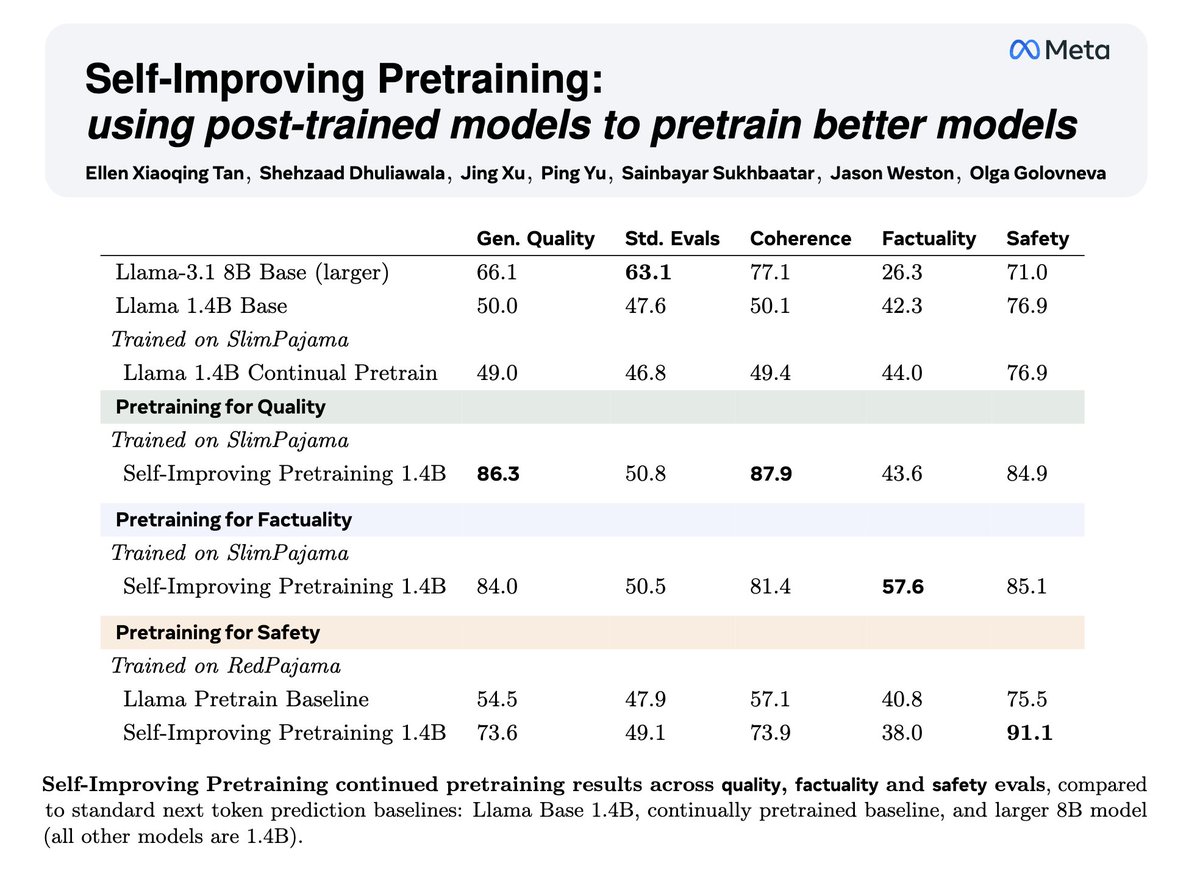
Self-Improving Pretraining
We've updated our results given feedback:
- larger 8B baseline to match reward model size
- cross-task evals given different RM objectives
Overall, we see clear wins
Our team in FAIR at Meta is hiring a postdoc researcher!
We work on the topics of Reasoning, Alignment and Memory/architectures (RAM).
Apply here: https://t.co/dWtpz7rttT
Location: NY, Seattle or Menlo Park.
Some of our recent work to give flavor:
Co-Improvement (position): https://t.co/XPwbsuCUI6
SPICE (Self-Play in Corpus Environments): https://t.co/47BarIr0uM
Self-Challenging Agents: https://t.co/qgDLmchn8X
RL from Human Interaction: https://t.co/wmC2fVByp2
AggLM (parallel aggregation): https://t.co/Fg0E31aOIy
StepWiser (CoT-PRM RL): https://t.co/QbfBVYx522
DARLING (diversity-trained RL): https://t.co/J9ZSs8GVyX
J1 (RL-trained LLM-as-Judge): https://t.co/yG6xAPaNJ3
CoT-Self-Instruct: https://t.co/dHMYRxtv5h
Multi-Token Attention: https://t.co/4kfUe8KozT
Our team in FAIR at Meta is hiring a (full-time) researcher!
We work on the topics of Reasoning, Alignment and Memory/architectures (RAM) for self-improvement & co-improvement.
Apply here:
https://t.co/Vukp3u8rfu
Location: NY, Seattle or Menlo Park.
Some of our recent work to give flavor:
Co-Improvement (position): https://t.co/XPwbsuCmSy
SPICE (Self-Play in Corpus Environments): https://t.co/47BarIqsFe
Self-Challenging Agents: https://t.co/qgDLmcgPjp
RL from Human Interaction: https://t.co/wmC2fVB0zu
AggLM (parallel aggregation): https://t.co/Fg0E31agT0
StepWiser (CoT-PRM RL): https://t.co/QbfBVYwxcu
DARLING (diversity-trained RL): https://t.co/J9ZSs8GnJp
J1 (RL-trained LLM-as-Judge): https://t.co/yG6xAPafTv
CoT-Self-Instruct: https://t.co/dHMYRxsXfJ
Multi-Token Attention: https://t.co/4kfUe8JQKl
Our team in FAIR at Meta is hiring a postdoc researcher!
We work on the topics of Reasoning, Alignment and Memory/architectures (RAM).
Apply here: https://t.co/dWtpz7rttT
Location: NY, Seattle or Menlo Park.
Some of our recent work to give flavor:
Co-Improvement (position): https://t.co/XPwbsuCUI6
SPICE (Self-Play in Corpus Environments): https://t.co/47BarIr0uM
Self-Challenging Agents: https://t.co/qgDLmchn8X
RL from Human Interaction: https://t.co/wmC2fVByp2
AggLM (parallel aggregation): https://t.co/Fg0E31aOIy
StepWiser (CoT-PRM RL): https://t.co/QbfBVYx522
DARLING (diversity-trained RL): https://t.co/J9ZSs8GVyX
J1 (RL-trained LLM-as-Judge): https://t.co/yG6xAPaNJ3
CoT-Self-Instruct: https://t.co/dHMYRxtv5h
Multi-Token Attention: https://t.co/4kfUe8KozT
If you are a PhD student in Berkeley or one of these universities, you can apply to our mentorship program and do research with us! The deadline is this Friday though https://t.co/ISfdqvGwlS
Our co-improvement position paper is now on arXiv!
(We've updated it, covering more existing work.)
📝: https://t.co/xnxWYoMNP7
After >27 years of research, my first position paper!
Short 🧵 (1/5) follows 👇
Synopsis: it's about building AI that collaborates on AI research *with us* to solve AI faster, and to help fix the alignment problem together.
How? Build the AI with those collab skills (i.e., we create benchmarks! training data! methods! etc. for that).
I've been personally inspired by @Yoshua_Bengio's recent talks on safety & AI research, and also from seeing Nicholas Carlini's COLM keynote where he said we researchers can all do our bit to help (paraphrased). So – hope this helps! 🙏
Holy shit… Meta might’ve just solved self-improving AI 🤯
Their new paper SPICE (Self-Play in Corpus Environments) basically turns a language model into its own teacher no humans, no labels, no datasets just the internet as its training ground.
Here’s the twist: one copy of the model becomes a Challenger that digs through real documents to create hard, fact-grounded reasoning problems. Another copy becomes the Reasoner, trying to solve them without access to the source.
They compete, learn, and evolve together an automatic curriculum with real-world grounding so it never collapses into hallucinations.
The results are nuts:
+9.1% on reasoning benchmarks with Qwen3-4B
+11.9% with OctoThinker-8B
and it beats every prior self-play method like R-Zero and Absolute Zero.
This flips the script on AI self-improvement.
Instead of looping on synthetic junk, SPICE grows by mining real knowledge a closed-loop system with open-world intelligence.
If this scales, we might be staring at the blueprint for autonomous, self-evolving reasoning models.
🤝 New Position Paper !!👤🔄🤖
@j_foerst and I wrote a position piece on what we think is the path to safer superintelligence: co-improvement.
Everyone is focused on self-improving AI, but (1) we don't know how to do it yet, and (2) it might be misaligned with humans.
Co-improvement: instead, build AI that collaborates *with us* to solve AI faster, and to help fix the alignment problem together. More details in the paper!
Read it here:
📝:https://t.co/peiPnLHHXG
Yes I remember this from 10 years ago. My answers were not that great because I didn't get any sleep from the excitement. But it's interesting there was a question about scaling attention in a sub-linear way, which still is an important question and not fully answered.
🌶️SPICE: Self-Play in Corpus Environments🌶️
📝: https://t.co/QxEd13QEmu
- Challenger creates tasks based on *corpora*
- Reasoner solves them
- Both trained together ⚔️ -> automatic curriculum!
🔥 Outperforms standard (ungrounded) self-play
Grounding fixes hallucination & lack of diversity
🧵1/6
Heading to COLM! Presenting two papers: Multi-Token Attention for augmenting softmax attention for more precision, and COCONUT 🥥 for continuous CoT reasoning. Oh also speaking at RAM2 🐏 workshop about memory 🧠
@QuackerEnte Each attention weight is conditioned on only one key and one query vector. Our method makes it possible to condition on multiple vectors, so it can be more fine-grained and information rich
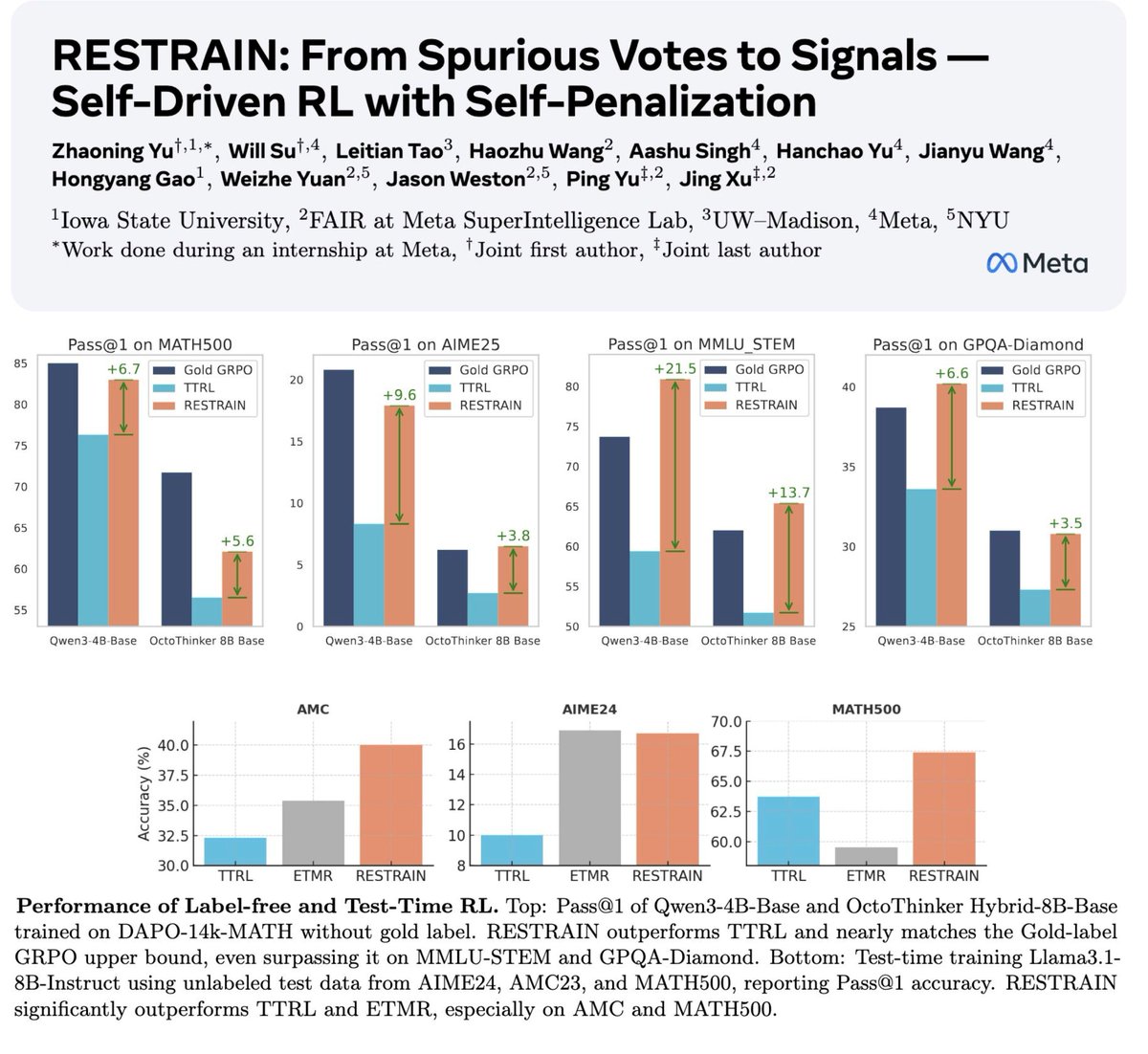
🌀New Self-Driven RL Method: RESTRAIN 🌀
📝: https://t.co/VceEJ248fW
- RESTRAIN turns spurious votes → self-Improving signals. No labels needed
- Does this through self-penalizing unreliable reasoning paths:
✔️ Uses all rollouts, not just the majority,
✔️ Offsets low-consistency rollout advantage,
✔️ Down-weights low-consensus prompts
📈 Results:
🔥 Beats existing techniques on both training-time (label-free) and test-time scaling — all without labels.
🔥 Nearly matches (and sometimes surpasses) gold-label RL
🧵(1/5)