🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
We ran Qwen3.6-35-A3B GGUF performance benchmarks to help you choose the best quant.
Unsloth ranks first in 21 of 22 model sizes on mean KL divergence, making them SOTA.
GGUFs: https://t.co/VlyW8UwDjw
We're delighted to announce that MiniMax M2.7 is now officially open source.
With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%).
You can find it on Hugging Face now. Enjoy!🤗
huggingface:https://t.co/ApWrahIl3o
Blog: https://t.co/gAxeFsNdW4
MiniMax API: https://t.co/1dgbMx0Q7K
‼️Do not npm install or deploy anything right now
Supply chain attack on axios 1.14.1 - even if you don’t use axios it may be a nested dep.
Pin versions or wait until this is resolved
The Next.js Adapter API is now stable - the result of over a year of collaboration with Netlify, OpenNext, and other platform partners.
We are deeply committed to developers running Next.js on Cloudflare. Looking forward to building our official adapter on this new foundation.
🔥 Introducing LongCat-Next: A Discrete Native Autoregressive Multimodal Model
LongCat-Next integrates language, vision, and audio into a unified discrete autoregressive model, extending Next-Token Prediction to native multimodality and delivering industrial-strength performance across diverse multimodal domains.
🔑 Key Features:
⚙️ 68.5B total params, 3B active, LongCat-Flash-Lite MoE backbone, excels at seeing, painting, and speaking in a unified discrete autoregressive framework.
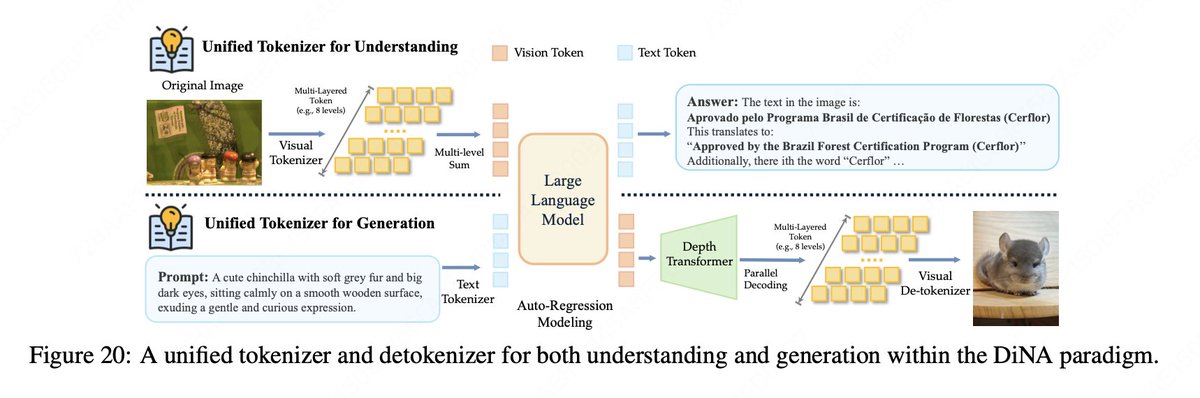
🧩 Discrete Native Autoregression Paradigm (DiNA): We introduce DiNA, a unified paradigm that extends next-token prediction from language to native multimodality, internalizing diverse modalities into a shared discrete token space.
🌐 Discrete Native Any‑Resolution Vision Transformer (dNaViT): A unified visual tokenizer and de-tokenizer that encodes images into discrete IDs with semantic completeness, enabling both understanding and generation at any resolution. This approach overcomes the performance ceiling of discrete vision modeling in understanding tasks and enables to reconcile the conflict between understanding and generation.
👀 Visual Understanding: Fine-grained visual perception for complex tasks such as OCR, Charts, GUI interpretation, and document analysis, and advanced STEM reasoning capabilities.
🎨 Visual Generation: Generation under 28x compression ratio at arbitary resolution with competitive performance, especially in text rendering.
🎧 Speech: Strong audio comprehension capabilities, low-latency and intelligent audio-to-audio interaction, as well as speech synthesis featuring customizable voice cloning.
📄 Paper: https://t.co/qiV6YnU9pf
🔗 GitHub: https://t.co/50SHgGrltZ
😊 HuggingFace: https://t.co/Lf0JIQBNAW
💻 demo: https://t.co/b0KncgeAju
📖 blog: https://t.co/LlII0InEW7
Building agent skills from scratch is a grind.
We've been there. So we built the fix — and open-sourced all of it under MIT.
PDF, Excel, PPTX, DOCX, and more.
Use it, fork it, PR it.
Intelligence with everyone.
Github Repo → https://t.co/BCw4PmX38p
Try online → https://t.co/lkE9bKA2m1