Today is the last day of class, so we asked our students to shout out their favorite professors on the Hilltop. Hear what our Mustangs have to say about the professors who made this semester special! 💙
I wrote Deep Learning with Python to be the definitive guide to how deep learning works and how to best make use of it. Tens of thousands of people got their career start via this book. 120,000 copies sold, and downloaded by millions more.
And now it's free to read online: https://t.co/3CbcQ7hmjp
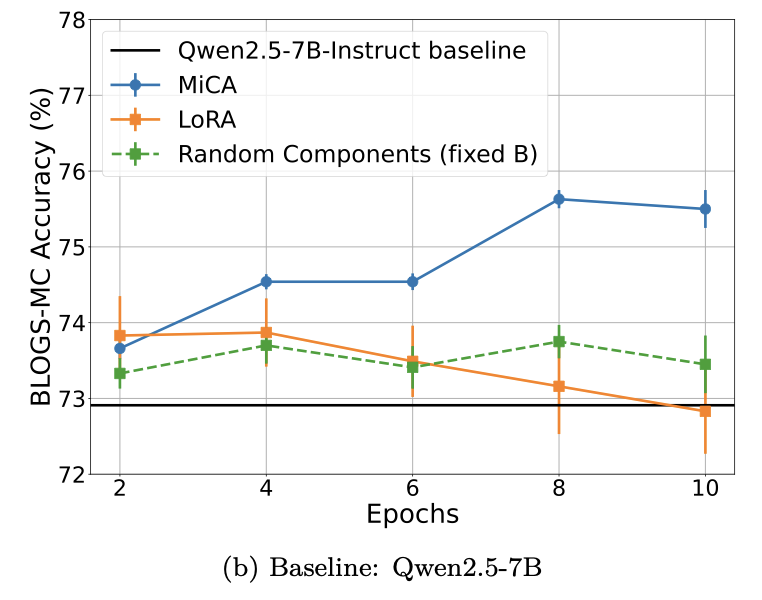
I’ve uploaded a new paper on arXiv (co-authored by @rasbt):
MiCA Learns More Knowledge Than LoRA and Full Fine-Tuning
In Parameter-Efficient Fine-Tuning, a key question may not just be how low-rank the update is, but *which* subspace we adapt.
People struggle to differentiate fluid intelligence from knowledge because, given enough preparation, memorized templates become a solid substitute for on-the-fly adaptation
I'm closely following new research showing a troubling gap in AI education tools. A 2026 MIT study gave students identical feedback—some told it was from their TA, others told it was AI. Both groups said the feedback was equally good, but students who thought a real person wrote it worked significantly harder afterward. The takeaway: even high-quality AI feedback fails to motivate students the way human attention does. Students need to feel seen by a real person to stay engaged and persist through challenges.
https://t.co/Kkvb0JVsfL
Nice paper, confirming what we are also seeing as educators (on a smaller scale in the paper, but good evidence that this is becoming a broader problem). https://t.co/Bq8JDdjcKP
Hopefully this gets the attention it deserves. Current popular methods are great at mimicking world descriptions. When it comes to applying knowledge in the world, these methods need lots of refinement to even be mediocre. Descriptive methods have their place, but not a panacea.
Professor Judea Pearl — the pioneer who invented causal reasoning in AI — says scaling won't save us.
"Mathematical limitations that are not crossable by scaling up."
The brutal truth: LLMs aren’t learning how the world works. They are learning how we describe the world.
This resonates with most biologists: Drug discovery is hitting the same wall. We have mountains of genomic data, but most AI models just find patterns in published papers — not in the raw biology itself. They're learning what scientists think causes disease, not what actually does.
Pearl's causal revolution? That's how we move from "this gene correlates with cancer" to "this gene causes cancer" — and finally design drugs that work.
Until then, we're building very expensive parrots.
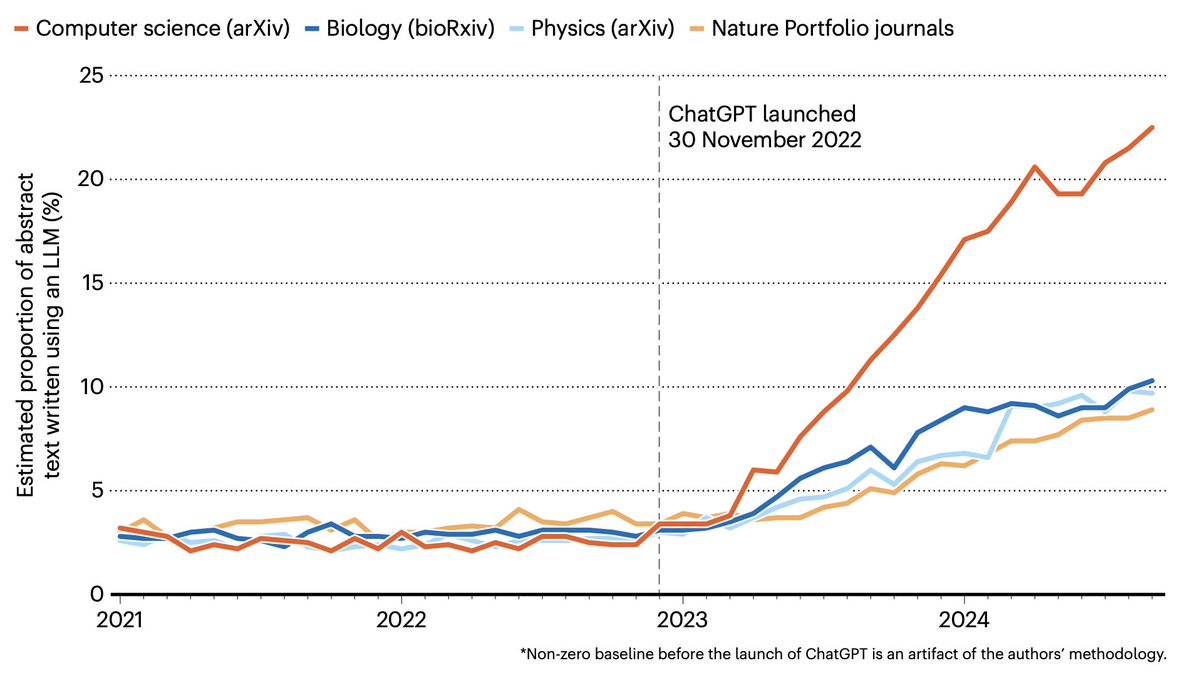
A really dangerous situation. Too many submissions. Too many generated papers. Little responsibility.
1. In 2026, more than 24,000 submissions were made to the International Conference on Machine Learning (ICML). It’s TWO times more than in 2025. To fight it, the organizers now require researchers to pay $100 for every subsequent paper.
2. LLM adoption has increased researcher productivity by 90% (there’s a recent paper in Science).
3. The number of papers is becoming far too high. Submissions to arXiv have risen by 50% since 2022.
4. There are simply not enough reviewers. Plus, many scientists no longer want to invest precious time in it for free.
5. We can’t easily identify AI-made papers from the genuine ones.
__
Important words from Paul Ginsparg, a co-founder of arXiv:
“AI slop frequently can’t be discriminated just by looking at abstract, or even by just skimming full text. This makes it an “existential threat” to the system.”
Basically, we’re getting closer to the tipping point.
📍 Many professors blame the AI.
But the problem is likely elsewhere:
1. Without a sufficient number of papers, many PIs can’t get funded. They have to prove their credibility to reviewers. Their proposals have to rely on prior publications. In many countries, there are some informal (or even formal) expectations for how many papers a group with a certain size has to publish to survive (funding-wise).
2. Our students / postdocs need papers if they want to be hired in faculty roles. Yes, some departments hire people with few publications. But the majority still want to ensure their faculty can get funded. If funding is partly a function of papers, this is used in decision-making.
3. The number of papers is important if you want to get high-level awards. Many of them are not given because you published one paper (even if it’s great). They are given because you made a meaningful CONTRIBUTION to the field. How do you make it? Publish more papers.
4. Tenure promotions in many places take the number of your papers into account (often indirectly). Your tenure may get delayed if you don’t publish enough. Not everywhere, but for many mid- to low-ranked universities this story is more or less the same.
+ There are many more to mention.
📍My opinion:
Much of this is rooted in how funding is distributed.
There is a strong correlation between the requirements at a university and the funding acquisition criteria.
If funding were based ONLY on the quality of published papers, universities would hire people for the quality of their science. If funding agencies strongly discouraged publishing too many papers, universities wouldn’t expect numbers from faculty during promotions. And some supervisors wouldn’t pressure students and postdocs to publish unfinished studies and low-quality data.
Yes, we need good detectors of fake papers.
But we also need the right policies and better funding allocation criteria.
Stanford and Caltech researchers just published the first comprehensive taxonomy of how llms fail at reasoning
not a list of cherry-picked gotchas. a 2-axis framework that finally lets you compare failure modes across tasks instead of treating each one as a random anecdote
the findings are uncomfortable
NotebookLM just ended manual AI paper reading.
They’ve released a new version for arXiv papers and it’s insane.
It doesn’t just summarize papers.
- It studies thousands of related sources
- Connects the research for you
- Explains everything back in audio like a real mentor
And yes… it’s completely free.
Welcome to our exceptional cohort of new and returning Moody Graduate and Dissertation Fellows! Through their supportive community of dedicated staff, the Moody School of Graduate & Advanced Studies inspires graduate students to pursue their passions and become leaders in their fields.
📢 We're hiring open-rank TT CS faculty at Notre Dame!! All areas are welcomed, with computer vision, software systems for robotics, and quantum computing being of particular interest.
♥️ Come and be my colleague! It's a fantastic dept. to be a part of.
https://t.co/79B3R9xGQw
📘🌟 We are proud to share that Dr. Jiun-Yu Wu, Professor at SMU Simmons, has been appointed as an Editor for Computers & Education - one of the most prestigious international journals at the intersection of teaching and learning, technology, AI, and the learning sciences (🔗https://t.co/bocXN65Gza).
Dr. Wu’s research bridges Learning Science, AI in Education, and Data Science, using AI-driven analytics to study learner engagement, track progress, and foster cognitive and socio-emotional growth 📈
📖 Read more on Simmons blog: 🔗https://t.co/TJCSHK0t2S and join us in congratulating Dr. Wu on this well-deserved recognition! 👏
#SMUSimmons #SMUSimmonsResearch #ComputersAndEducation #EducationResearch
Overall, this could be a worrying trend. And CS/ECE are by far the biggest culprits. My advice: write your paper, then ask an LLM to find holes in your argument. Far superior outcome than relying on text generation (even for your own concept).