I’ve uploaded a new paper on arXiv (co-authored by @rasbt):
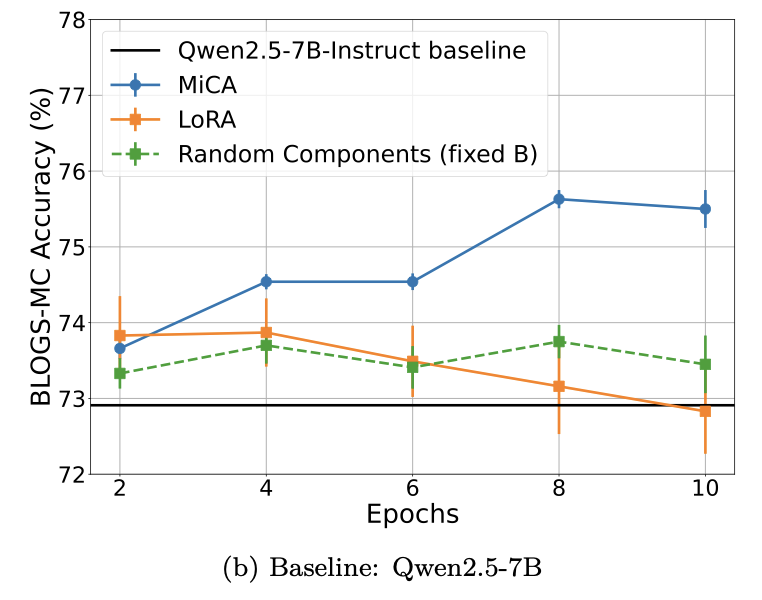
MiCA Learns More Knowledge Than LoRA and Full Fine-Tuning
In Parameter-Efficient Fine-Tuning, a key question may not just be how low-rank the update is, but *which* subspace we adapt.
What are the real problems to be solved in continual learning? In my latest post, I tackle this question — reviewing where I think the field went astray in the past, how language models changed things, and where the real challenges remain. 1/2
@GaryMarcus They built a massive knowledge graph, bolted on a distributed theorem-proving stack with 15 layers of Lean, and 10^6 proof branches, added retrieval, kernel verification … and then put a thin LLM wrapper on top just to prove you wrong, Gary.
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
Isn't it ironic that OpenAI and Anthropic are building consultancies now?
They talk about Forward Deployed Engineering teams and bespoke deployment work. These are engineers who spend weeks on-site at one enterprise to "operationalize" the model.
It sounds like the Palantir playbook. And it raises the question: why, if your model is the most capable system ever built, does deploying it look like a 15-year-old consulting business?
In my opinion, the answer is that LLMs are good enough for coding, where corrections are very clean (compile, test, diff) and there are infinite GitHub trajectories to learn from. They're, however, not good enough yet for enterprise work like CRM, finance, compliance, or engineering. Here corrections vanish into chats, edits stay in Outlook, and the model never sees them again.
So the labs want to do what Palantir does. They put humans in the loop. FDEs sit at the customer, learn the company, build the wrapper, and it takes months.
This is where the bitter lesson of machine learning cuts in: methods that scale with compute beat methods that hand-encode human knowledge about a task. The FDE model (compile the enterprise's ontology by hand, then run applications on top) is the opposite of this.
I think the OpenAI/Anthropic bet is that much of the adaptation work is done by their models, and they only need FDEs for the scaffolding. This is how the semantic definitions and the trust layer get installed.
There is, however, a third position besides the Palantir and the lab frameworks that almost nobody is articulating: don't compile the enterprise's logic and ontology at all. Have the model learn it from the corrections users generate during work. Treat the first weeks of deployment like an intern's first weeks. The model is bad? Coworkers correct it. The corrections accumulate, and after a quarter or so, the model is proficient. No FDE army required.
The hard part is the correction loop. You need dense enough signals so corrections happen during normal work, not in workshops. And the model has to actually learn from them without forgetting previous skills and knowledge. The current foundation-model post-training paradigm doesn't do this. Per-customer fine-tuning is too expensive and breaks at scale.
This is why continual learning is the next frontier, not larger models or better RL on math. The labs are building consultancies because their models can't onboard themselves. Whoever solves that solves enterprise AI without an army of FDEs.
Anthropic and OpenAI know this, and the consultancy is a bridge for them. I guess part of the deal will be that they harvest deployment signals and train with them, so the learnings show up in the next model. But in my opinion the architecture is wrong: The model the customer is using doesn't update from that customer's corrections. The signal flows back to the lab and not back to the model.
What would the right answer look like? One general policy trained by RL to process information and read/write an external memory. Customer-specific tools, processes, and exceptions live in the memory and not in the weights. The model is trained once while the same weights serve every enterprise The LLM agent gets better after correction and not just at the current task.
The bitter lesson says bet on learning and generalization. The AI lab consultancies bet on scaffolding. The third bet (learned ontology and written into memory, accumulated from use) is the most bitter-lesson-aligned of the three.
That is the bet I want to build.
Je veux présenter mes excuses, au nom des Français, pour avoir enfanté la French Theory (qui a enfanté la pire des merdes idéologiques : le wokisme).
Nous avons donné au monde Descartes, Pascal, Tocqueville. Et puis, dans les ruines intellectuelles de l'après-68, nous avons donné Foucault, Derrida, Deleuze. Trois hommes brillants qui ont fabriqué, dans l'élégance de notre langue, l'arme idéologique qui paralyse aujourd'hui l'Occident.
Il faut comprendre ce qu'ils ont fait. Foucault a enseigné que la vérité n'existe pas, qu'il n'y a que des rapports de pouvoir déguisés en savoir. Que la science, la raison, la justice, l'institution médicale, l'école, la prison, la sexualité, tout n'est qu'une mise en scène de la domination. Derrida a enseigné que les textes n'ont pas de sens stable, que tout signifiant glisse, que toute lecture est une trahison, que l'auteur est mort et que le lecteur règne. Deleuze a enseigné qu'il fallait préférer le rhizome à l'arbre, le nomade au sédentaire, le désir à la loi, le devenir à l'être, la différence à l'identité.
Pris isolément, ce sont des thèses discutables. Combinées, exportées, vulgarisées, elles forment un système. Et ce système est un poison.
Car voici ce qui s'est passé. Ces textes, illisibles en France, ont traversé l'Atlantique. Les départements de Yale, de Berkeley, de Columbia les ont absorbés dans les années 80. Ils y ont trouvé un terreau qui n'existait pas chez nous : le puritanisme américain, sa culpabilité raciale, son obsession identitaire. La French Theory s'est mariée à ce substrat, et l'enfant de ce mariage s'appelle le wokisme.
Judith Butler lit Foucault et invente le genre performatif. Edward Said lit Foucault et invente le post-colonialisme académique. Kimberlé Crenshaw hérite du cadre et invente l'intersectionnalité. À chaque étape, la matrice est française : il n'y a pas de vérité, il n'y a que du pouvoir, donc toute hiérarchie est suspecte, toute institution est oppressive, toute norme est violence, toute identité est construite donc négociable, toute majorité est coupable.
Voilà comment trois philosophes parisiens, qui n'ont probablement jamais imaginé leurs conséquences pratiques, ont fourni le logiciel d'exploitation à une génération entière d'activistes, de bureaucrates universitaires, de DRH, de journalistes, de législateurs. Voilà comment on a obtenu une civilisation qui ne sait plus dire si une femme est une femme, si sa propre histoire mérite d'être défendue, si le mérite existe, si la vérité se distingue de l'opinion.
C'est de la merde pour une raison simple, et il faut la dire calmement. Une civilisation se tient debout sur trois piliers : la croyance qu'il existe une vérité accessible à la raison, la croyance qu'il existe un bien distinct du mal, la croyance qu'il existe un héritage à transmettre. La French Theory a entrepris de dynamiter les trois. Pas par méchanceté. Par jeu intellectuel, par fascination du soupçon, par haine de la bourgeoisie qui les avait nourris. Mais le résultat est là. Une génération entière a appris à déconstruire et n'a jamais appris à construire. Une génération entière sait soupçonner et ne sait plus admirer. Une génération entière voit le pouvoir partout et la beauté nulle part.
Je m'excuse parce que nous, Français, avons une responsabilité particulière. C'est notre langue, nos universités, nos éditeurs, notre prestige qui ont donné à ce nihilisme son emballage chic. Sans la légitimité de la Sorbonne et de Vincennes, ces idées n'auraient jamais traversé l'océan. Nous avons exporté le doute comme d'autres exportent des armes.
Ce qui se construit maintenant, en silicon valley, dans les labos d'IA, dans les startups, dans les ateliers, dans tous les lieux où des gens fabriquent encore des choses au lieu de les déconstruire, c'est la réponse. Une civilisation se reconstruit par les bâtisseurs, pas par les commentateurs. Par ceux qui croient que la vérité existe et qu'elle vaut qu'on s'y consacre. Par ceux qui assument une hiérarchie du beau, du vrai, du bon, et qui n'ont pas honte de la transmettre.
Alors pardon. Et au travail.
This research goes a long way towards the goal of continual learning and a fast-slow training for continual LLM adaptation feels right. It lets context/prompt absorb the fast task learning, and lets weights adapt more slowly.
Open questions for me:
Does interleaving GEPA+RL really add quality vs two separate steps of GEPA first and RL second?
Also I find it unintuitive what updates should go in weights vs context.
Training LLMs is synonymous with updating their weights. However, LLMs can also learn in-context using *frozen* weights. There is no good reason for restricting learning to being in-context or in-weights.
So a natural idea is "Learning, Fast and Slow" (FST). In FST, slow learning is LLM weights trained with RL while fast learning is context / prompt (fast weights) optimized with GEPA.
Compared to RL, FST performs better while being more data efficient, adaptable (plasticity), and forgetting less (stays closer to base models).
I think this idea of learning both fast-slow weights would be a good foundation for continual learning.
PS: Geoff Hinton (the OG) described the idea of fast weights and slow weights several years ago, and back then I remember thinking it's a very cool idea.
See more details here:
https://t.co/FACsHx7IpK
@nicbstme Interestingly, the continual learning bench shows that agentic continual learning does not work as good as simply throwing everything into the context. My thesis is that a loop of training the model for better out-of-weights continual learning is missing.
https://t.co/QvwkF89reS
@jason_haugh The issue is not that integration work cannot be done by Accenture etc. Instead, it is that outside of coding, agents still do not work reliably out of the box. Frontier labs now need direct contact with enterprise data, tools, workflows, and edge cases to close the loop.
Some thoughts one what I am working on: LLMs can't learn from experience. Every conversation starts from zero. I think this is one of the biggest reasons agents often fail in enterprise settings beyond coding. They cannot adapt to your codebase, your workflows and your customers over time.
This is the continual learning problem. It has been studied for years in smaller models, but the LLM era has mostly gone over it with RAG and longer context windows. Those help but they do not solve it.
@pgasawa and coauthors just published a continual learning benchmark for LLMs:
https://t.co/9lUftIH3eB
It tests what happens when a model has to learn online, sequentially but without revisiting past data. This is much closer to how real deployment actually looks.
The natural first instinct is to fine-tune on the training data and call it a day. But that misses the point. You are testing memorization and online abstraction, not learning ability. The benchmark is designed to resist this.
What I think is missing: meta-training for continual learning. I.e. we should not train the model to solve the tasks but train it to be a better online learner. Better memory use, better integration of new information, and better resistance to forgetting.
The model still learns online at test time. Meta-training just gives it better priors about how to learn. If this works, it is not just a benchmark result but also a path toward agents that actually improve in deployment. Agents that get better at your problem the longer they work on it, which may be the unlock for enterprise beyond coding.
I am building this in the open: https://t.co/vgNymHNGlq
Looking for collaborators who think continual learning is the missing piece.
Really cool work, congrats. Task-specific RL training like this clearly works when you can define the environment and generate the data.
The open question for me is what happens when you have a thousand needs across e.g. an enterprise. Training a specialist for each one does not really scale, and you cannot anticipate all the tasks upfront. At some point you want one model that adapts in deployment without weight updates for every new use case.
We have started to create an OS training environment for the https://t.co/fLHZrRl172 to test whether RL can improve memory use in CL agents.
Built on @PrimeIntellect infra.
Looking for contributors interested in:
memory, tool use, RL, evals, and continual learning.
https://t.co/vgNymHNGlq
@pgasawa@GOrlanski@ramyaramakri
@_asimbiwal @vincentsunnchen@fredsala@matei_zaharia@ProfJoeyG
Some thoughts one what I am working on: LLMs can't learn from experience. Every conversation starts from zero. I think this is one of the biggest reasons agents often fail in enterprise settings beyond coding. They cannot adapt to your codebase, your workflows and your customers over time.
This is the continual learning problem. It has been studied for years in smaller models, but the LLM era has mostly gone over it with RAG and longer context windows. Those help but they do not solve it.
@pgasawa and coauthors just published a continual learning benchmark for LLMs:
https://t.co/9lUftIH3eB
It tests what happens when a model has to learn online, sequentially but without revisiting past data. This is much closer to how real deployment actually looks.
The natural first instinct is to fine-tune on the training data and call it a day. But that misses the point. You are testing memorization and online abstraction, not learning ability. The benchmark is designed to resist this.
What I think is missing: meta-training for continual learning. I.e. we should not train the model to solve the tasks but train it to be a better online learner. Better memory use, better integration of new information, and better resistance to forgetting.
The model still learns online at test time. Meta-training just gives it better priors about how to learn. If this works, it is not just a benchmark result but also a path toward agents that actually improve in deployment. Agents that get better at your problem the longer they work on it, which may be the unlock for enterprise beyond coding.
I am building this in the open: https://t.co/vgNymHNGlq
Looking for collaborators who think continual learning is the missing piece.
We have started to create an OS training environment for the https://t.co/fLHZrRl172 to test whether RL can improve memory use in CL agents.
Built on @PrimeIntellect infra.
Looking for contributors interested in:
memory, tool use, RL, evals, and continual learning.
https://t.co/vgNymHNGlq
@pgasawa@GOrlanski@ramyaramakri
@_asimbiwal @vincentsunnchen@fredsala@matei_zaharia@ProfJoeyG
Wow. This is exactly what I was just searching for!
The next logical step is to train LLMs directly on these tasks. I.e. not just isolated tool calls, but full sequences of tasks where the model learns when to remember, when to retrieve, and when to act.
Today, we’re releasing Continual Learning Bench 1.0: the first, realistic benchmark for measuring how AI systems can improve in online settings.
Benchmarks today assume models are stateless. Each example is independent, and once a system finishes a task, it moves on as if nothing happened.
But deployed AI systems should learn from experience. We tested 10+ frontier systems against novel, expert-validated tasks and find there’s still plenty of headroom for learning. (1/n)
RL trains LLMs to improve before deployment.
But can we also train LLMs to improve while they are being used?
Not just learn how to pick the right tool. But learn how to store useful corrections, retrieve them later, and change behavior across future tasks.
That is what I want to discuss in this article and the next one.