Hanging out with @lmthang and @YiTayML for multiple days in Vietnam and Google Singapore.
And great event with @newturing on AI and humanity.
Thank you for hosting!!
Gemini 3.5 Flash is amazing!
- Performs better than 3.1 Pro on coding & agentic tasks
- 4x faster than other frontier models
- 12x faster in @antigravity - 800 tokens/sec!
- Often at less than half the cost
And Pro to come…
Try it in @antigravity, @GeminiApp & more - enjoy!
Dr. @edchi will join GStar Summit 2026 for a keynote on foundation models and a panel discussion on frontier AI.
Website for program details and ticket registration: https://t.co/9JtMDBX24q
Be part of the conversation!
Related: https://t.co/enDIFfsok1
"Claude Code skill & Codex plugin that makes agent talk like caveman — cutting ~75% output tokens while keeping full technical accuracy. Now with 文言文 mode, terse commits, one-line code reviews, and compression tool that cuts ~46% tokens."
A Hypothesis: Agents of the future could communicate to each other using thought tokens.
Corollary: Humans will have to decode those thought tokens in order to find out what the agents are doing with each other.
Note: GenZers are already doing this with their slang. No Cap.
A Hypothesis: Agents of the future could communicate to each other using thought tokens.
Corollary: Humans will have to decode those thought tokens in order to find out what the agents are doing with each other.
Note: GenZers are already doing this with their slang. No Cap.
@spacegrep@denny_zhou@quocleix Imho, the attention paid over the length of CoT helps sharpen the model toward the correct decoding path. This CoT reasoning path helps the model perform 'next idea prediction' instead of just doing 'next token prediction'. That has been my intuition.
The original CoT paper ("lets think step by step") from Jan 2022 is equally important as the Transformer ("attention is all you need"). https://t.co/YRKESO6OQE
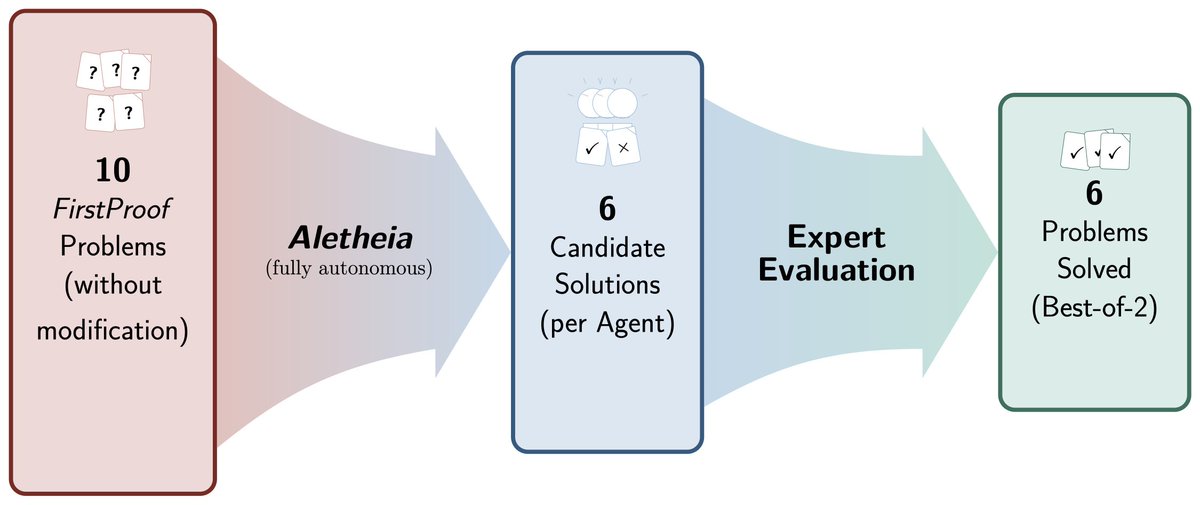
Thrilled to share: #Aletheia, our math research agent, just solved 6/10 notoriously hard FirstProof problems autonomously, the best result in the inaugural challenge! To me, this is even bigger than our historic IMO-gold achievement last year; these problems challenge even top mathematicians. We share our results transparently, see paper and full thoughts in the thread. 👇
@spacegrep@denny_zhou@quocleix yes, major bugs IMHO:
- the current models are generally fixed minds, and only learns and compresses new knowledge during gradient descent.
- the other learning / memory mechanism is in-context learning with CoT, but the model forgets it right after.
Clearly insufficient.
In the social media era, kids actually feel more loneliness---ironically.
As a former social computing researcher, this is deeply depressing to me.
https://t.co/UBMYybK6X8
h/t Kristina Lerman #WSDM 2026 keynote
@denny_zhou@quocleix in my not-so-humble opinion:
- 1995-2015 most important 3 ideas are: reverse indexing with mapreduce, vector space models, deep learning.
- 2015-2025 most important 3 ideas: seq2seq learning/transduction with transformers, CoT fine-tuning, and refinement using RL.