Grupo de Investigaciones de Macroeconomía Aplicada de la Universidad de Antioquia encontró inconsistencias en las cifras de desempleo del DANE: Edwin Torres, doctor en Economía.
Una reflexión que escuché sobre qué es amor: 1) Es la voluntad de comprender, 2) Es la actitud de cuidar, y 3) Es la posibilidad de inspirar. No es igual que la atracción, es por el contrario, la decisión de salir de sí para otro.
🚰La Calera es un municipio vecino de Bogotá que sirve para entender un fenómeno del que poco se habla en los medios de comunicación: el del acaparamiento de agua. 🧵👇
If you are working with an event-driven system, don’t let this interview question surprise you:
“How do you retry failed transactions using message queues?”
This is a common pattern to handle transient errors. Let’s understand with the help of payment processing as an example.
The general approach to implement a retry mechanism using message queues has 3 main parts:
✅ Main Queue: This is where new payment transactions are queued.
✅ Dead Letter Queue: A separate queue for messages that failed processing multiple times.
✅ Retry Queue: This is where retries are scheduled with delays. This queue is optional as you can also use the main queue for it.
Here’s how the process works:
[1] The consumer or payment processor picks up a message from the main queue. It attempts to process the payment transaction.
[2] If processing fails, it checks the retry count that’s often stored in the message metadata.
[3] If retry count > max retries, increment count and re-queue the message.
[4] If retry count ≥ max retries, move the message to the DLQ.
[5] For retries, you can either re-queue directly to the main queue with a delay or use a separate retry queue with a time-based trigger.
[6] Lastly, monitor the DLQ for messages that have exhausted retry attempts. Implement a process for dealing with them.
Some best practices to consider while following this pattern:
👉 Exponential Backoff
Increase the delay between retries exponentially to avoid overwhelming the system.
👉 Idempotency
Ensure that the payment processor can safely retry payment without crashing the economy
👉 Message TTL
Set an overall TTL for messages to stop very old transactions from being processed.
👉 Retry Limits
Set a value for max number of retries
👉 Error Types
Distinguish between transient errors (can be retried) and permanent errors (direct to DLQ)
So - what will you add to this approach to make it better?
An Interview question every developer should know.
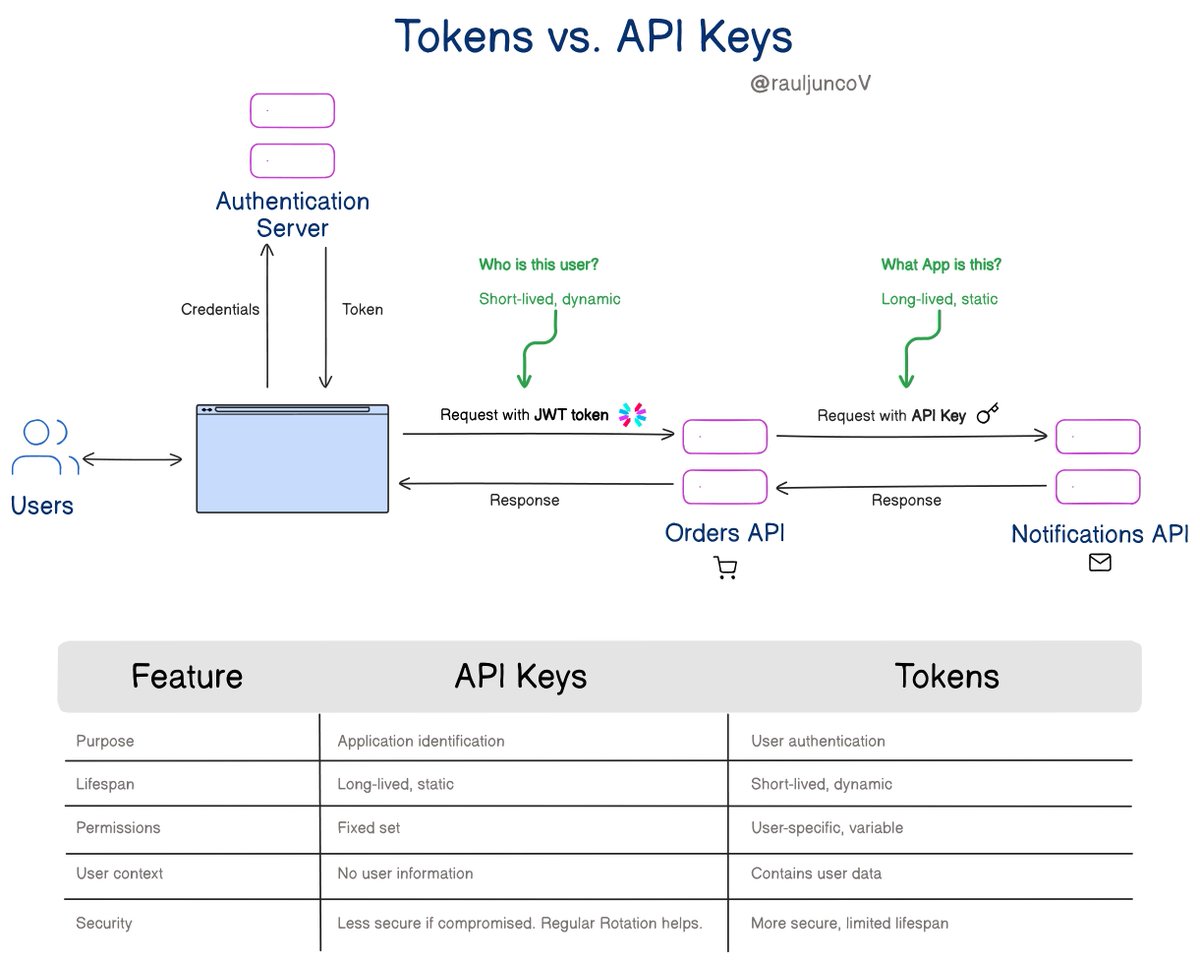
What's the difference between Tokens and API keys?
We use API keys and tokens for authentication and authorization.
But they serve different purposes and have distinct characteristics.
Tokens (like JWT - JSON Web Tokens):
Carries user context and permissions for authentication and authorization.
Encoded with a user ID, permissions, and expiration time, often in JWT format.
Critical for user-specific access, like accessing a user's profile data in an e-commerce platform.
It is issued by an authentication server after user login and contains user-specific information.
API Key:
Primarily for identifying the application or the consumer making the API call.
They are long strings we pass in the header or as a query parameter in the API request.
You use API keys when access does not involve user context. For example, accessing a public API or service-to-service communication.
They are long-lived and created through the API provider's platform or admin console.
In simple terms:
- Tokens are for managing user sessions, permissions, and context.
- API keys are for identifying applications.
Which one have you used the most?
@Jorge_BastidasR De hecho la cifra proporcionada para 2024, es similar a una proyección matemática acorde a las variaciones previas. Si utilizas alguna IA con la tabla hasta el 2018 y le dices que genere los datos para 2024, los datos arrojados son los datos de votos que dice haber para el 2024.
@Jorge_BastidasR Saludos, acorde a los datos presentados por usted, se ve que para 2013 ya había un decrecimiento del 7.37%, que para 2018 ya alcanza el 17.68%. Es decir que la tendencia viene negativa.
«Todo el mundo moderno se ha dividido en conservadores y progresistas. El negocio de los progresistas es seguir cometiendo errores. El negocio de los conservadores es evitar que se corrijan los errores».
G.K. Chesterton
Aquí con su esposa Frances Blogg 👇🏻
𝗗𝗲𝗳𝗶𝗻𝗶𝗻𝗴, 𝗠𝗲𝗮𝘀𝘂𝗿𝗶𝗻𝗴, 𝗮𝗻𝗱 𝗠𝗮𝗻𝗮𝗴𝗶𝗻𝗴 𝗧𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹 𝗗𝗲𝗯𝘁 𝗯𝘆 𝗚𝗼𝗼𝗴𝗹𝗲
In the latest paper by Google Engineers, they researched how to define, measure, and manage Technical Debt. They use quarterly engineering satisfaction surveys to analyze the results.
𝟭. 𝗗𝗲𝗳𝗶𝗻𝗶𝘁𝗶𝗼𝗻 𝗼𝗳 𝗧𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹 𝗗𝗲𝗯𝘁
Google took an empirical approach to defining technical debt. They asked engineers about the types of technical debt they encountered and what mitigations would be appropriate to fix this debt. This resulted in a collectively exhaustive and mutually exclusive list of 10 categories of technical debt, including:
🔹 Migration is needed or in progress: This may be motivated by the need for code or systems to be updated, migrated, or maintained.
🔹 Code degradation: The codebase has degraded or not kept up with changing standards over time. The code may be in maintenance mode, needing updates or migrations.
🔹 Documentation on project and application programming interfaces (APIs): Information on your project's work is hard to find, missing, or incomplete.
🔹 Testing: Poor test quality or coverage, such as missing tests or poor test data, results in fragility and flaky tests.
🔹 Code quality: Product architecture or project code must be better designed. It may have been rushed or a prototype/demo.
🔹 Dead and abandoned code: Code/features/projects were replaced or superseded but still need removal.
🔹 Team needs more expertise: This may be due to staffing gaps, turnover, or inherited orphaned code/projects.
🔹 Dependencies: Dependencies are unstable, rapidly changing, or trigger rollbacks.
🔹 Migration could have been better executed or abandoned: This may have resulted in maintaining two versions.
🔹 Release process: The rollout and monitoring of production need to be updated, migrated, or maintained.
𝟮. 𝗠𝗲𝗮𝘀𝘂𝗿𝗶𝗻𝗴 𝗧𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹 𝗗𝗲𝗯𝘁
Google measures technical debt through a quarterly engineering survey. They ask engineers about which of these categories of technical debt have hindered their work. The responses to these surveys help Google identify teams that struggle with managing different types of technical debt. They found that engineers working on machine learning systems face different types of technical debt compared to engineers who build and maintain back-end services.
They focused on code degradation, teams needing more expertise, and migrations being required or in progress. Then, they explored 117 metrics proposed as indicators of one of these forms of technical debt—the results were that no single metric predicted reports of technical debt from engineers.
𝟯. 𝗠𝗮𝗻𝗮𝗴𝗶𝗻𝗴 𝗧𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹 𝗗𝗲𝗯𝘁
Over the last four years, Google has made a concerted effort to better define, measure, and manage technical debt. Some of the steps taken include:
🔸 Creating a technical debt management framework to help teams establish good practices
🔸 Creating a technical debt management maturity model and accompanying technical debt maturity assessment that
evaluates and characterizes an organization's technical debt management process
🔸 Organizing classroom instruction and self-guided courses to evangelize best practices and community forums to drive continual engagement and sharing of resources.
🔸 Tooling that supports the identification and management of technical debt (for example, indicators of poor test coverage, stale documentation, and deprecated dependencies)
It's important to note that zero technical debt is not the goal at Google. The presence of deliberate, prudent technical debt reflects the practicality of developing systems in the real world. The key is to manage it thoughtfully and responsibly.
#technology #softwareengineering #programming #techworldwithmilan #development
Creating a REST API may be easy.
But creating a high-quality REST API is hard.
Here are 6 best practices that can help you build REST APIs that your consumers love:
[1] Use PLURAL nouns for collections
Mostly an arbitrary convention but well-established.
✅ GOOD
GET /books
GET /books/{book_id}
❌ BAD
GET /book/{book_id}
It’s good to follow this practice as your clients and consumers tend to expect this and would thank you for not breaking it.
[2] Don’t model your database relations in REST API path segments
Sometimes, developers try to build the entire relational model into the URL structure.
✅ GOOD
GET /books/{book_id}
❌ BAD
GET /authors/{author_id}/books/{book_id}
The Book ID is globally unique and there’s no reason for Author ID to be part of the URL for accessing the book.
Compound URLs might make sense when book_id is unique only per author in your data model
[3] Don’t return arrays as top-level responses
The top-level response from an endpoint should be an object and not an array.
✅ GOOD
GET /books returns:
{ “data”: [{…book1…}], [{…book2…}] }
❌ BAD
GET /books returns:
[{…book1…}], [{…book2…}]
Why is it bad to return arrays?
Imagine trying to make changes to the output that are backward compatible.
For example, adding pagination fields like totalCount. It will be a breaking change for the client.
[4] Use strings for identifiers
Always use strings for object identifiers even if your database stores a numeric value.
✅ GOOD
{ “id”: “456”}
❌ BAD
{ “id”: 456 }
String IDs are flexible to changes in implementation and help future developers adapt the system in various ways.
[5] Don’t use 404 to indicate “NOT FOUND”
I know the HTTP spec says you should 404 to indicate that a resource was not found.
Developers implement this literally by having GET/PUT/DELETE return 404 to an ID that doesn’t exist.
This is confusing behavior.
When calling GET /books/{book_id} for a book that doesn’t exist, the response should convey two things to the client:
The server understood the request
The book ID wasn’t found
Unfortunately, 404 doesn’t guarantee the first point.
404 could be because of various reasons such as:
- Misconfigured client hitting the wrong URL
- Bad proxy settings
- Load balancer issues
[6] Use a structured error format
Imagine building a REST API in a large system with many consumers and you don’t have a proper error format.
Trust me, your entire working hours will evaporate answering queries.
I typically keep a detailed error format with fields like:
- error message
- type of error
- cause (if applicable)
👉Of course, this is not an exhaustive list.
I’m sure you’ll have more best practices in your mind and might also disagree with the ones I’ve mentioned.
Do share them.
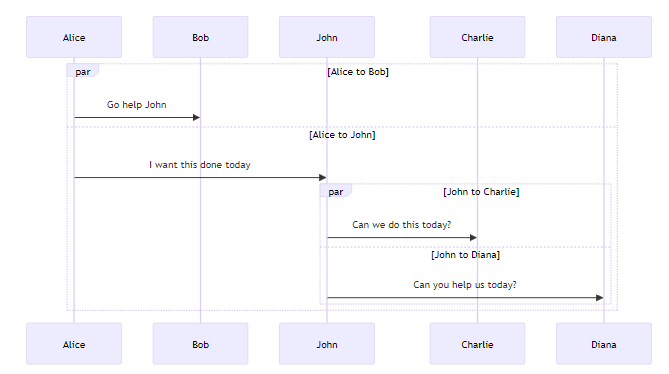
𝗛𝗼𝘄 𝗱𝗼 𝘆𝗼𝘂 𝗰𝗿𝗲𝗮𝘁𝗲 𝗱𝗶𝗮𝗴𝗿𝗮𝗺𝘀 𝗳𝗿𝗼𝗺 𝗰𝗼𝗱𝗲?
The latest ThoughtWorks Technology Radar, Volume 29, notes the 𝗠𝗲𝗿𝗺𝗮𝗶𝗱 as the tool that should be used.
It is free and open source, enabling many integrations with source code repositories, IDEs, and knowledge management tools.
Unlike many other GUI-based programs, the entire graph drawing program in Mermaid is text-based. This makes the diagrams very easily maintainable.
Also, it is supported in different source code repositories, such as GitHub or GitLab, so you can embed those diagrams in the Markdown documentation.
Here is an example:
𝚜𝚎𝚚𝚞𝚎𝚗𝚌𝚎𝙳𝚒𝚊𝚐𝚛𝚊𝚖
𝚙𝚊𝚛 𝙰𝚕𝚒𝚌𝚎 𝚝𝚘 𝙱𝚘𝚋
𝙰𝚕𝚒𝚌𝚎->>𝙱𝚘𝚋: 𝙶𝚘 𝚑𝚎𝚕𝚙 𝙹𝚘𝚑𝚗
𝚊𝚗𝚍 𝙰𝚕𝚒𝚌𝚎 𝚝𝚘 𝙹𝚘𝚑𝚗
𝙰𝚕𝚒𝚌𝚎->>𝙹𝚘𝚑𝚗: 𝙸 𝚠𝚊𝚗𝚝 𝚝𝚑𝚒𝚜 𝚍𝚘𝚗𝚎 𝚝𝚘𝚍𝚊𝚢
𝚙𝚊𝚛 𝙹𝚘𝚑𝚗 𝚝𝚘 𝙲𝚑𝚊𝚛𝚕𝚒𝚎
𝙹𝚘𝚑𝚗->>𝙲𝚑𝚊𝚛𝚕𝚒𝚎: 𝙲𝚊𝚗 𝚠𝚎 𝚍𝚘 𝚝𝚑𝚒𝚜 𝚝𝚘𝚍𝚊𝚢?
𝚊𝚗𝚍 𝙹𝚘𝚑𝚗 𝚝𝚘 𝙳𝚒𝚊𝚗𝚊
𝙹𝚘𝚑𝚗->>𝙳𝚒𝚊𝚗𝚊: 𝙲𝚊𝚗 𝚢𝚘𝚞 𝚑𝚎𝚕𝚙 𝚞𝚜 𝚝𝚘𝚍𝚊𝚢?
𝚎𝚗𝚍
𝚎𝚗𝚍
What is your favorite diagram-as-code tool?
#softwaredesign #tools
10 System Design Case Studies you can read over the weekend:
[1] Scaling Cron Scripts at Slack
https://t.co/21HVMvCCoQ
[2] A look at Notion's Flexible Data Model https://t.co/jxLzWczasf
[3] How Discord stores trillions of messages?https://t.co/MiTKoOHpGj
[4] Buffered Writes at Uber for High Availability
https://t.co/6I4scK046b
[5] How Notion Sharded their PostgresDB? https://t.co/aa7ENPVWMd
[6] The Architecture of Airbnb's Internationalization Platform https://t.co/Qxnudk0g3B
[7] Scaling Cron Scripts at Slack https://t.co/21HVMvCCoQ
[8] PayPal's JunoDB Breakdown https://t.co/gK2QqCOY66
[9] MySQL High Availability at Flipkart https://t.co/dzZiXewOp4
[10] How Notion Handles Concurrent Updates
https://t.co/G9MEvyZexC
HTTPS is used everywhere.
But most engineers can’t explain how it simply works.
Let’s change that.
HTTP is a protocol to exchange data, most popularly used between a web browser and a website. 💡
HTTPS is the secure version of that protocol. 🛡
Why is it secure?
Encryption. 😶🌫️
The data is encrypted so that only the web browser and the website can read it locally.
Without this, man-in-the-middle (MITM) attacks could intercept your traffic and read sensitive data like passwords, credit card details, etc. 😱
The protocol used to encrypt the data is TLS (Transport Layer Security).
HTTPS = HTTP + TLS. Simple as that.
HTTPS uses asymmetric cryptography to encrypt the data. You have:
🔑 a private key - the website’s SSL certificate’s secret key that isn’t shared with anyone.
🔑 a public key - the certificate’s public key, shared with everyone who wants to interact with the website.
💡 Asymmetric cryptography simply means information that’s encrypted by the public key can only be decrypted by the private key. And vice versa.
In contrast, symmetric cryptography is when only one key is used, and data can be encrypted/decrypted with that same key.
HTTPS actually uses both types! 😎
Asymmetric cryptography is used to verify the server and securely generate a session key that’ll be used for symmetric cryptography.
The session key, as it implies, only lives within the session and is used by both the client & server to encrypt/decrypt data.
Most interestingly, this key is deterministically generated by both the client and server independently - it never crosses the wire. 🪄
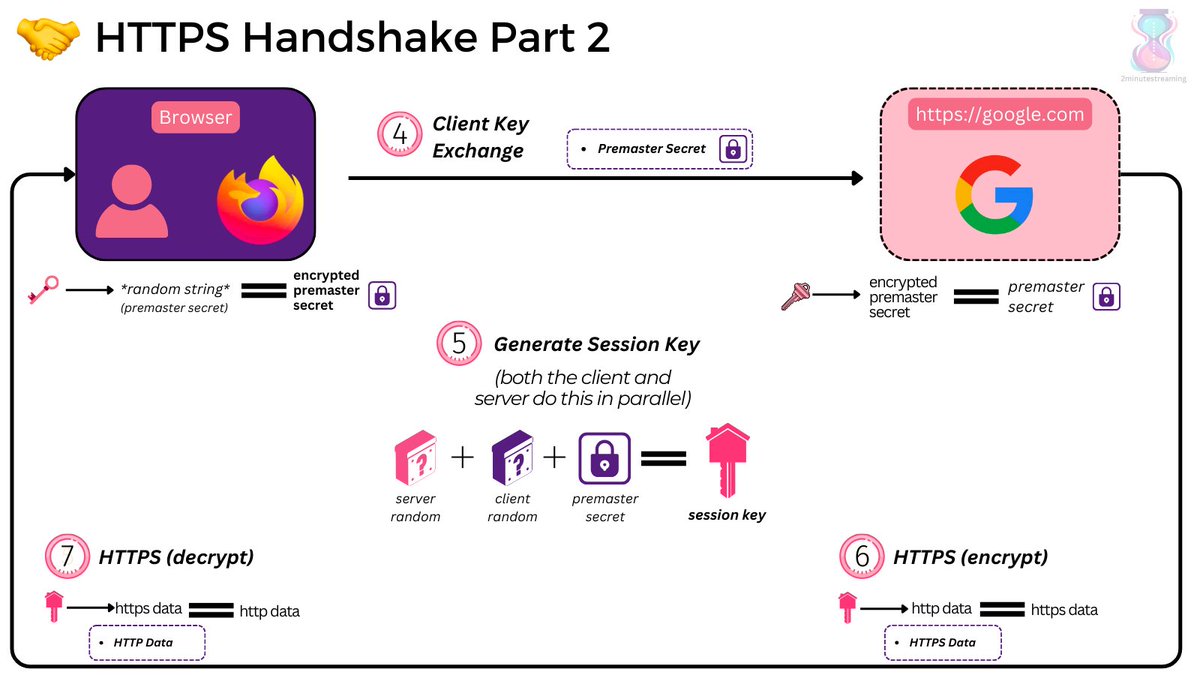
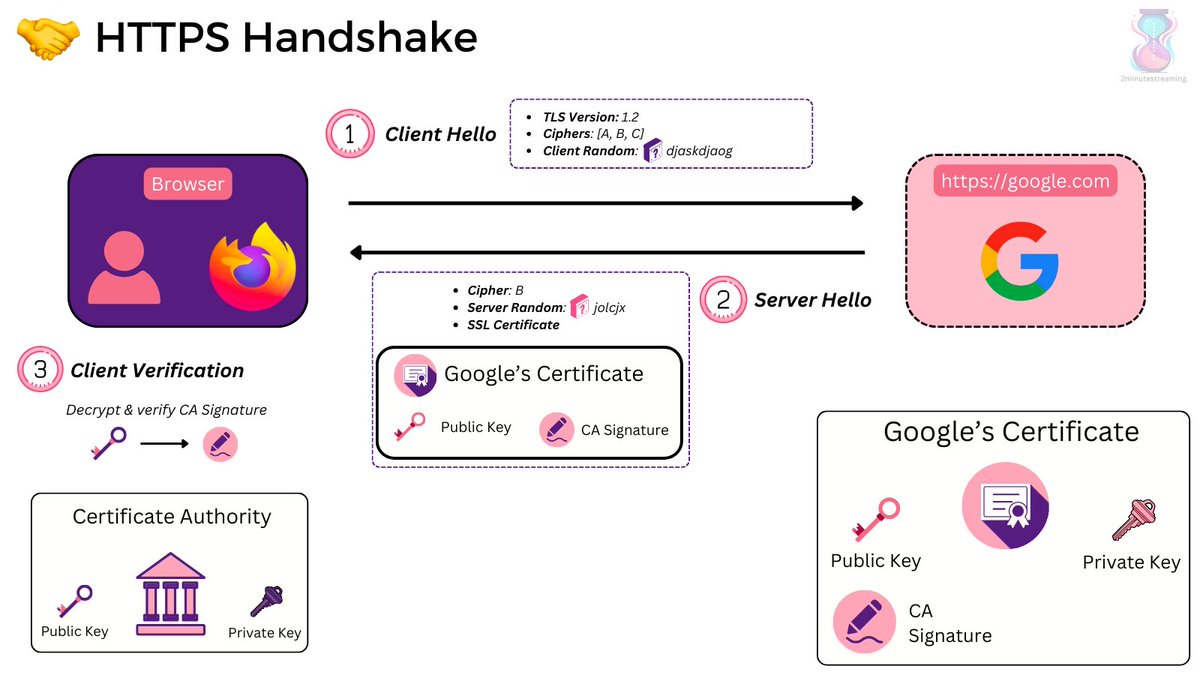
So. What are the steps?
1. Client (browser) connects to a server (web page)
2. Server sends its SSL certificate (includes the public key).
3. Client & Server do a TLS handshake & generate a session key to encrypt/decrypt future HTTP data.
4. Business as usual.
The details are in the TLS handshake, and that’s frankly the most interesting part of how HTTPS works.
The TLS handshake serves three purposes:
🧐 1. authenticate the identity of the server
✨ 2. generate session keys for encryption during this single session
🤝 3. decide which version of TLS and what cipher suites you’ll use
Step by step (RSA Algorithm):
1. Client Hello Request: The client initiates the handshake with a message including what TLS version and ciphers it supports, including a string of random bytes (client random)
2. Server Hello Response: The server chooses a cipher suite and generates its own random string bytes (server random). It responds with the suite, its SSL certificate, and the server random.
3. Client Verification: The client verifies the certificate via the trusted certificate authority that issued it. The SSL certificate has a digital signature that’s signed by the CA’s private key so the client uses the CA’s public key to decrypt it.
After this step, the Client has verified that the certificate is the legitimate one verified via the CA - not one fabricated on the fly.
Note it still doesn’t know for sure whether the server actually owns that certificate (i.e has the private key)
Side note: who says what Certificate Authority can be trusted?
Your browser’s provider!
Apple, Microsoft, Google, Mozilla and etc. all maintain their own lists of CAs.
Your browser and operating system ship with this list of trusted CAs.
It’s all based on “trust”, so you better trust them!
Anyway, continuing...
4. Client Key Exchange: The client creates a random string of bytes called the “premaster secret”. It encrypts it with the public key of the server it got from the SSL certificate and sends it over.
5. Session Key Generation: The server decrypts the premaster secret using the SSL certificate’s private key. Both the client and server, independently, generate session keys using the client random, server random, and the premaster secret.
Since they’re using the same data and deterministic algorithm, they should arrive at the same results. If they don’t - the subsequent encryption/decryption won’t result in the HTTP protocol.
💡 This step indirectly verifies to the client that the server has possession of the SSL certificate it presented (it didn’t just pretend to have it)
6. Done! The session key is now used to symmetrically encrypt/decrypt HTTP data.
@timecaptales There is a good novel from a spanish writer about Louisiana, it maybe a interesting reading. About french, spanish, british and finally american colonos ownership of Louisiana.
Lejos de Luisiana
Luz Gabás





























![ProgressiveCod2's tweet photo. If you are working with an event-driven system, don’t let this interview question surprise you:
“How do you retry failed transactions using message queues?”
This is a common pattern to handle transient errors. Let’s understand with the help of payment processing as an example.
The general approach to implement a retry mechanism using message queues has 3 main parts:
✅ Main Queue: This is where new payment transactions are queued.
✅ Dead Letter Queue: A separate queue for messages that failed processing multiple times.
✅ Retry Queue: This is where retries are scheduled with delays. This queue is optional as you can also use the main queue for it.
Here’s how the process works:
[1] The consumer or payment processor picks up a message from the main queue. It attempts to process the payment transaction.
[2] If processing fails, it checks the retry count that’s often stored in the message metadata.
[3] If retry count > max retries, increment count and re-queue the message.
[4] If retry count ≥ max retries, move the message to the DLQ.
[5] For retries, you can either re-queue directly to the main queue with a delay or use a separate retry queue with a time-based trigger.
[6] Lastly, monitor the DLQ for messages that have exhausted retry attempts. Implement a process for dealing with them.
Some best practices to consider while following this pattern:
👉 Exponential Backoff
Increase the delay between retries exponentially to avoid overwhelming the system.
👉 Idempotency
Ensure that the payment processor can safely retry payment without crashing the economy
👉 Message TTL
Set an overall TTL for messages to stop very old transactions from being processed.
👉 Retry Limits
Set a value for max number of retries
👉 Error Types
Distinguish between transient errors (can be retried) and permanent errors (direct to DLQ)
So - what will you add to this approach to make it better?](https://pbs.twimg.com/media/GWc3zThX0AAAOwK.jpg)


![ProgressiveCod2's tweet photo. Creating a REST API may be easy.
But creating a high-quality REST API is hard.
Here are 6 best practices that can help you build REST APIs that your consumers love:
[1] Use PLURAL nouns for collections
Mostly an arbitrary convention but well-established.
✅ GOOD
GET /books
GET /books/{book_id}
❌ BAD
GET /book/{book_id}
It’s good to follow this practice as your clients and consumers tend to expect this and would thank you for not breaking it.
[2] Don’t model your database relations in REST API path segments
Sometimes, developers try to build the entire relational model into the URL structure.
✅ GOOD
GET /books/{book_id}
❌ BAD
GET /authors/{author_id}/books/{book_id}
The Book ID is globally unique and there’s no reason for Author ID to be part of the URL for accessing the book.
Compound URLs might make sense when book_id is unique only per author in your data model
[3] Don’t return arrays as top-level responses
The top-level response from an endpoint should be an object and not an array.
✅ GOOD
GET /books returns:
{ “data”: [{…book1…}], [{…book2…}] }
❌ BAD
GET /books returns:
[{…book1…}], [{…book2…}]
Why is it bad to return arrays?
Imagine trying to make changes to the output that are backward compatible.
For example, adding pagination fields like totalCount. It will be a breaking change for the client.
[4] Use strings for identifiers
Always use strings for object identifiers even if your database stores a numeric value.
✅ GOOD
{ “id”: “456”}
❌ BAD
{ “id”: 456 }
String IDs are flexible to changes in implementation and help future developers adapt the system in various ways.
[5] Don’t use 404 to indicate “NOT FOUND”
I know the HTTP spec says you should 404 to indicate that a resource was not found.
Developers implement this literally by having GET/PUT/DELETE return 404 to an ID that doesn’t exist.
This is confusing behavior.
When calling GET /books/{book_id} for a book that doesn’t exist, the response should convey two things to the client:
The server understood the request
The book ID wasn’t found
Unfortunately, 404 doesn’t guarantee the first point.
404 could be because of various reasons such as:
- Misconfigured client hitting the wrong URL
- Bad proxy settings
- Load balancer issues
[6] Use a structured error format
Imagine building a REST API in a large system with many consumers and you don’t have a proper error format.
Trust me, your entire working hours will evaporate answering queries.
I typically keep a detailed error format with fields like:
- error message
- type of error
- cause (if applicable)
👉Of course, this is not an exhaustive list.
I’m sure you’ll have more best practices in your mind and might also disagree with the ones I’ve mentioned.
Do share them.](https://pbs.twimg.com/media/GDYjCDYaUAAFxRH.jpg)
![ProgressiveCod2's tweet photo. 10 System Design Case Studies you can read over the weekend:
[1] Scaling Cron Scripts at Slack
https://t.co/21HVMvCCoQ
[2] A look at Notion's Flexible Data Model https://t.co/jxLzWczasf
[3] How Discord stores trillions of messages?https://t.co/MiTKoOHpGj
[4] Buffered Writes at Uber for High Availability
https://t.co/6I4scK046b
[5] How Notion Sharded their PostgresDB? https://t.co/aa7ENPVWMd
[6] The Architecture of Airbnb's Internationalization Platform https://t.co/Qxnudk0g3B
[7] Scaling Cron Scripts at Slack https://t.co/21HVMvCCoQ
[8] PayPal's JunoDB Breakdown https://t.co/gK2QqCOY66
[9] MySQL High Availability at Flipkart https://t.co/dzZiXewOp4
[10] How Notion Handles Concurrent Updates
https://t.co/G9MEvyZexC](https://pbs.twimg.com/media/GDEz2yIaMAAb2br.jpg)
![hasantoxr's tweet photo. YouTube has more than 150 million channels.
Here are 12 channels that will give you free University level schooling:
[🔖 Bookmark for later] https://t.co/qwRXB2djxD](https://pbs.twimg.com/media/GBjXZ9sbkAAn6ns.jpg)