📢REALM returns for year 2 to dig into the questions that actually matter now that agents are everywhere: reliability, safety, long-horizon planning, multi-agent systems & more.
We'd love to see your work! Submit by 📅 Jul 17.
Join us Oct 29 at #EMNLP2026 in Budapest!
#AIagents
AI agents like @openclaw 🦞 are everywhere, answering emails, managing calendars, doing our chores for us
📣 REALM is back for year 2! Workshop for Research on Agent Language Models at #EMNLP2026, Budapest 🇭🇺
Stellar lineup ⬇️
📅 Submit by July 17, 23:59 AoE
#LLMAgents#NLProc
So excited to co-organize the Research on Agent Language Models (REALM) workshop at #EMNLP2026! 🚀 We are looking forward to some fantastic discussions and an amazing program.
📅 Deadline: July 17
🌐 Details: https://t.co/eNLPATrDRq
Can LLMs adapt continually without losing base skills?
Fast-Slow Training (FST) pairs "slow" weights with "fast" context.
FST vs. RL:
• 3x more sample-efficient
• Higher performance ceiling
• Less KL drift (better plasticity)
• Continual learning: succeeds where RL stalls
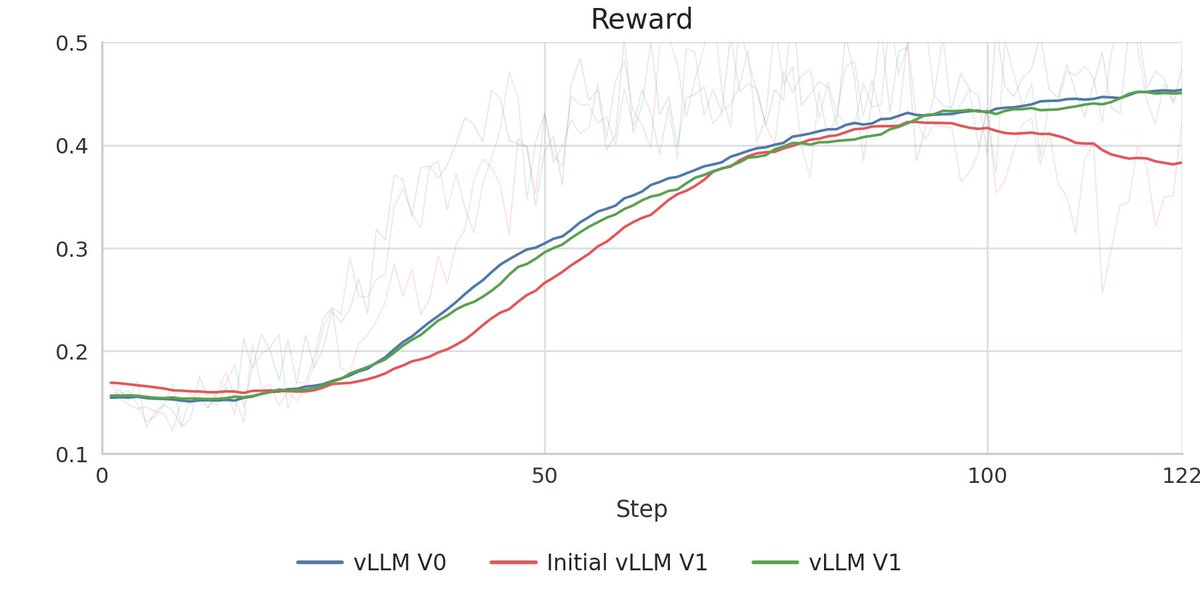
Our first vLLM V0→V1 run on PipelineRL looked broken.
@ehsk0 and I almost reached for an objective-side correction. That would have been the wrong fix.
The real problem: four mismatches in the rollout backend.
🧵
Research institutions weren't built for a world where AI can generate papers for $15, conferences get 20k+ submissions, and a handful of closed labs are pulling ahead fast.
I wrote about what the research community could do about it, and proposed a concrete system to help.
The Research Commons: multi-blind coordination, anonymous channels, roles for requesters/executors/reproducers/reviewers, and attribution that actually reflects who did what.
https://t.co/FNAgQLYmn1
(1/8)
🚀 Introducing Super Apriel: One Checkpoint, Many Speeds
Train once → serve at any speed-quality tradeoff
We release:
✓ 15B supernets with 4 mixers/layer
✓ Training code (Fast-LLM)
✓ vLLM serving extension
🧵 How it works ↓
Cross-domain RL training works and PipelineRL now supports it natively. We also incorporate adaptive domain sampling to keep the sampling proportions on target throughout training. Evidence from our recent paper: https://t.co/TjytyYQrP2
code: https://t.co/Zs8x9D7l94
Better reasoning does not have to mean longer reasoning.
Apriel OpenReasoner: fully reproducible multi-domain RL post-training using public datasets. 30-50% shorter traces, no quality trade-off.
@ServiceNowRSRCH@ehsk0@dvazquezcv@alexandredrouin
What if we didn't need MCP servers after all?
What if we didn't need browser-use agents either?
What if... Claude Code was enough?
In our latest paper, we test exactly this: Can simple terminal agents outperform web agents and tool-based agents on real enterprise tasks?
Really cool to see PipelineRL's in-flight weight updates being picked up! We're spreading it across our research teams to train models to reason and to make reasoning more efficient.
🚀 Announcing CUA-Suite, a computer-use agent (CUA) training and evaluation ecosystem based on the largest open expert video corpus for desktop CUAs – VideoCUA. 55 hours of human demonstrations across 87 professional apps — 2.5× bigger than the previous largest dataset.
🌐 https://t.co/KBXTC8dYfP
Congratulations Dr. Thakur for successfully defending his Ph.D. earlier today! Well deserved given his foundational contributions to benchmarks, data, and evaluation... and as his handle @beirmug suggests, there will be celebratory beers tonight! 🍻
We're sitting on a gold mine of data for evaluation and post-training.
Hundreds of agentic benchmarks, rich structured environments, verifiable signal.
Most of it is sitting idle. Not because nobody wants it, but because the engineering to use it is brutal. 🧵
🎙️ Today at NVIDIA GTC 2026 — @alex_lacoste_ presents From Benchmark Silos to an Interoperable AI Evaluation Ecosystem!
Catch it here 👇 https://t.co/EcrTdZpn84
10am, Marriott - Ballroom Salon III (L2)
#NVIDIAgtc#AIResearch#ServiceNow
🎙️ Exciting news: @alex_lacoste_ is presenting at NVIDIA GTC 2026!!
Topic: the fragmented world of agent benchmarks is creating a growing integration tax, and CUBE is the proposed fix.
CUBE = a universal benchmarking protocol built on MCP + Gym. Already validated with NVIDIA's NeMo tools.
📅 March 19 · 10:00 a.m. 🔗 https://t.co/EcrTdZpn84
#NVIDIAgtc #AgenticAI #AIResearch #ServiceNow
Remember all the self-distillation papers that came out last week. Well, we also propose it 😅, but…
But alongside something better 😎 π-Distill
We show that with this method, you can distill closed-source frontier models even tho their traces are hidden 🔒.
Both our methods can reach and even surpass the performance of the industry-standard SFT + RL with access to reasoning traces 🤯.
🔬And we spent ~100,000 hours GPU hours on a comprehensive analysis, not because the method is finicky, but because we wanted to understand why it works so well.
🧵
1/10
PipelineRL got accepted to TMLR 🎉
~2x faster on-policy RL training through in-flight weight updates. Making LLM agents training fly at @ServiceNowRSRCH@alexpiche_@DBahdanau@ehsk0
Paper: https://t.co/asqq5RLiIx
Code: https://t.co/3EsVmCabyx