My pleasure to come on Dwarkesh last week, I thought the questions and conversation were really good.
I re-watched the pod just now too. First of all, yes I know, and I'm sorry that I speak so fast :). It's to my detriment because sometimes my speaking thread out-executes my thinking thread, so I think I botched a few explanations due to that, and sometimes I was also nervous that I'm going too much on a tangent or too deep into something relatively spurious. Anyway, a few notes/pointers:
AGI timelines. My comments on AGI timelines looks to be the most trending part of the early response. This is the "decade of agents" is a reference to this earlier tweet https://t.co/NiSn6jftqq Basically my AI timelines are about 5-10X pessimistic w.r.t. what you'll find in your neighborhood SF AI house party or on your twitter timeline, but still quite optimistic w.r.t. a rising tide of AI deniers and skeptics. The apparent conflict is not: imo we simultaneously 1) saw a huge amount of progress in recent years with LLMs while 2) there is still a lot of work remaining (grunt work, integration work, sensors and actuators to the physical world, societal work, safety and security work (jailbreaks, poisoning, etc.)) and also research to get done before we have an entity that you'd prefer to hire over a person for an arbitrary job in the world. I think that overall, 10 years should otherwise be a very bullish timeline for AGI, it's only in contrast to present hype that it doesn't feel that way.
Animals vs Ghosts. My earlier writeup on Sutton's podcast https://t.co/rSp1noyGBr . I am suspicious that there is a single simple algorithm you can let loose on the world and it learns everything from scratch. If someone builds such a thing, I will be wrong and it will be the most incredible breakthrough in AI. In my mind, animals are not an example of this at all - they are prepackaged with a ton of intelligence by evolution and the learning they do is quite minimal overall (example: Zebra at birth). Putting our engineering hats on, we're not going to redo evolution. But with LLMs we have stumbled by an alternative approach to "prepackage" a ton of intelligence in a neural network - not by evolution, but by predicting the next token over the internet. This approach leads to a different kind of entity in the intelligence space. Distinct from animals, more like ghosts or spirits. But we can (and should) make them more animal like over time and in some ways that's what a lot of frontier work is about.
On RL. I've critiqued RL a few times already, e.g. https://t.co/mYrMFVdVDW . First, you're "sucking supervision through a straw", so I think the signal/flop is very bad. RL is also very noisy because a completion might have lots of errors that might get encourages (if you happen to stumble to the right answer), and conversely brilliant insight tokens that might get discouraged (if you happen to screw up later). Process supervision and LLM judges have issues too. I think we'll see alternative learning paradigms. I am long "agentic interaction" but short "reinforcement learning" https://t.co/2L7FiaoKsw. I've seen a number of papers pop up recently that are imo barking up the right tree along the lines of what I called "system prompt learning" https://t.co/df5mJDdN3C , but I think there is also a gap between ideas on arxiv and actual, at scale implementation at an LLM frontier lab that works in a general way. I am overall quite optimistic that we'll see good progress on this dimension of remaining work quite soon, and e.g. I'd even say ChatGPT memory and so on are primordial deployed examples of new learning paradigms.
Cognitive core. My earlier post on "cognitive core": https://t.co/q2s1ihGy0T , the idea of stripping down LLMs, of making it harder for them to memorize, or actively stripping away their memory, to make them better at generalization. Otherwise they lean too hard on what they've memorized. Humans can't memorize so easily, which now looks more like a feature than a bug by contrast. Maybe the inability to memorize is a kind of regularization. Also my post from a while back on how the trend in model size is "backwards" and why "the models have to first get larger before they can get smaller" https://t.co/6k0FZRGXsb
Time travel to Yann LeCun 1989. This is the post that I did a very hasty/bad job of describing on the pod: https://t.co/fQgqaXPyp6 . Basically - how much could you improve Yann LeCun's results with the knowledge of 33 years of algorithmic progress? How constrained were the results by each of algorithms, data, and compute? Case study there of.
nanochat. My end-to-end implementation of the ChatGPT training/inference pipeline (the bare essentials) https://t.co/SIetgyoKWN
On LLM agents. My critique of the industry is more in overshooting the tooling w.r.t. present capability. I live in what I view as an intermediate world where I want to collaborate with LLMs and where our pros/cons are matched up. The industry lives in a future where fully autonomous entities collaborate in parallel to write all the code and humans are useless. For example, I don't want an Agent that goes off for 20 minutes and comes back with 1,000 lines of code. I certainly don't feel ready to supervise a team of 10 of them. I'd like to go in chunks that I can keep in my head, where an LLM explains the code that it is writing. I'd like it to prove to me that what it did is correct, I want it to pull the API docs and show me that it used things correctly. I want it to make fewer assumptions and ask/collaborate with me when not sure about something. I want to learn along the way and become better as a programmer, not just get served mountains of code that I'm told works. I just think the tools should be more realistic w.r.t. their capability and how they fit into the industry today, and I fear that if this isn't done well we might end up with mountains of slop accumulating across software, and an increase in vulnerabilities, security breaches and etc. https://t.co/8556ESSpyY
Job automation. How the radiologists are doing great https://t.co/FVUI872dkD and what jobs are more susceptible to automation and why.
Physics. Children should learn physics in early education not because they go on to do physics, but because it is the subject that best boots up a brain. Physicists are the intellectual embryonic stem cell https://t.co/p72Elk8lPV I have a longer post that has been half-written in my drafts for ~year, which I hope to finish soon.
Thanks again Dwarkesh for having me over!
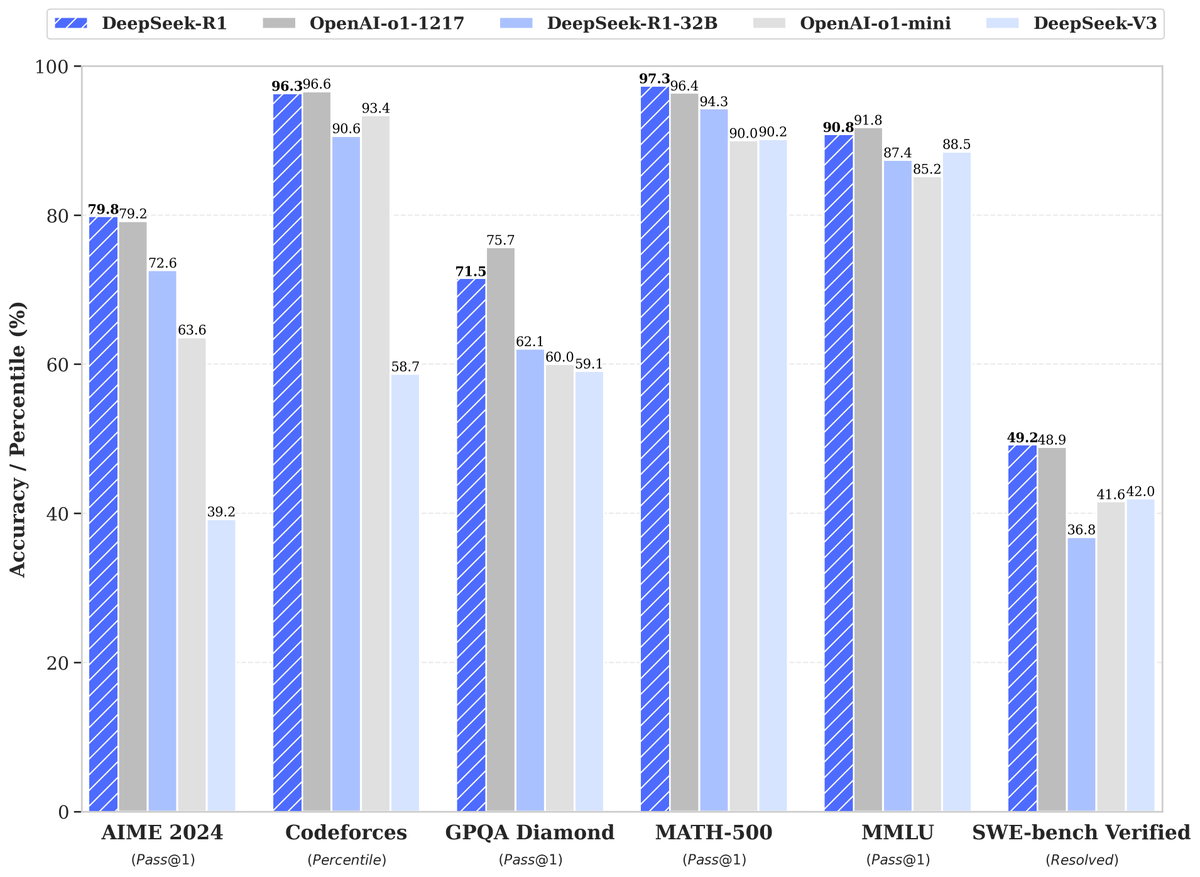
🚀 DeepSeek-R1 is here!
⚡ Performance on par with OpenAI-o1
📖 Fully open-source model & technical report
🏆 MIT licensed: Distill & commercialize freely!
🌐 Website & API are live now! Try DeepThink at https://t.co/v1TFy7LHNy today!
🐋 1/n
🛠️ DeepSeek-R1: Technical Highlights
📈 Large-scale RL in post-training
🏆 Significant performance boost with minimal labeled data
🔢 Math, code, and reasoning tasks on par with OpenAI-o1
📄 More details: https://t.co/jWMxMVhGAQ
🐋 4/n
Introducing Gemini 2.0 Flash Thinking, an experimental model that explicitly shows its thoughts.
Built on 2.0 Flash’s speed and performance, this model is trained to use thoughts to strengthen its reasoning.
And we see promising results when we increase inference time computation!
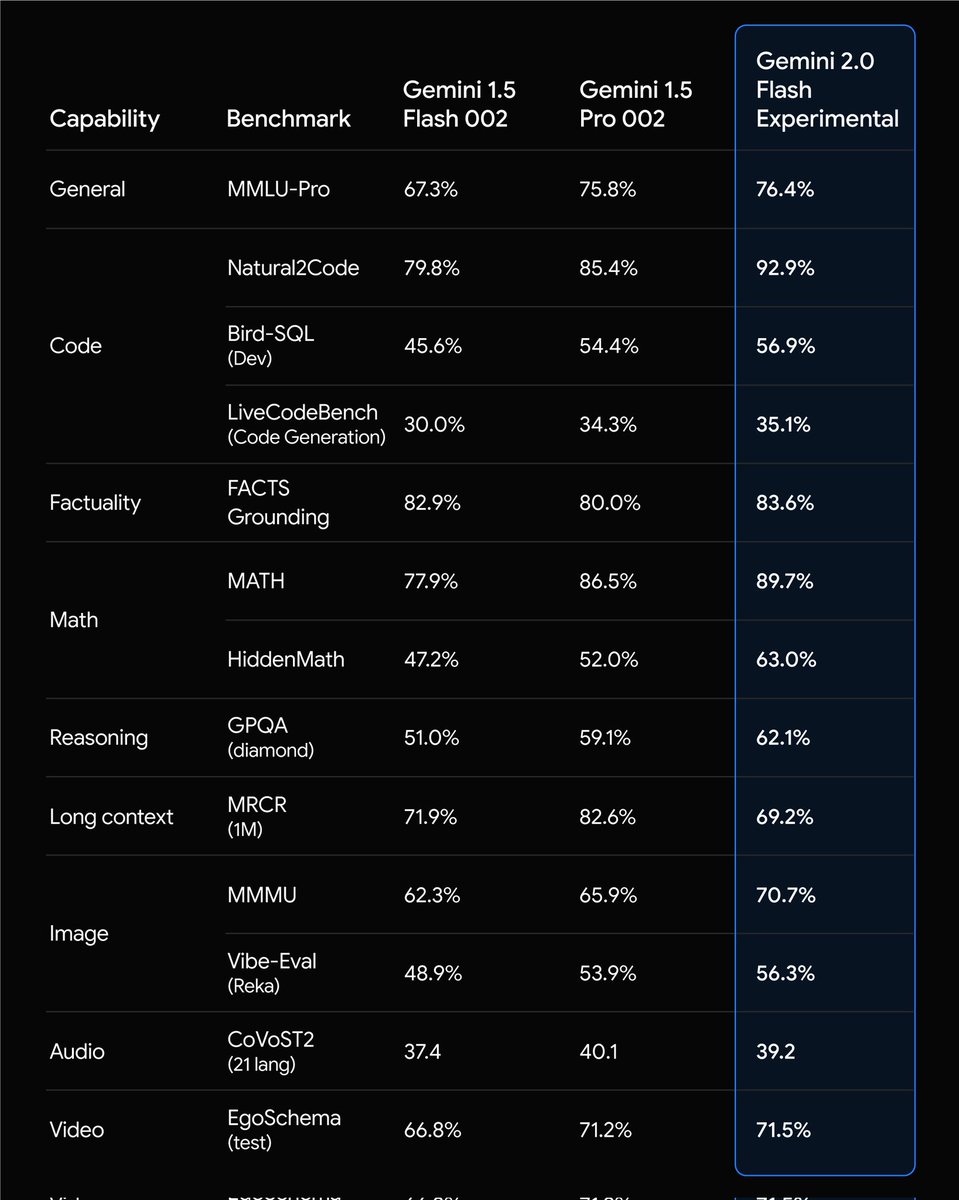
We’re kicking off the start of our Gemini 2.0 era with Gemini 2.0 Flash, which outperforms 1.5 Pro on key benchmarks at 2X speed (see chart below). I’m especially excited to see the fast progress on coding, with more to come.
Developers can try an experimental version in AI Studio and Vertex AI today. It is also available to try in @GeminiApp on the web today, mobile coming soon.
Mau gak, diingetin jalanin kewajiban di mana dan kapan pun?
Kalo pake BYOND by BSI pastinya bisa!
Super App terbaru dari Bank Syariah Indonesia yang bikin #SemuaJadiMudah
Mau diingetin? Yuk, cobain sekarang!
This is the biggest update we've had in a while.
Flowise v2.0 and Flowise Cloud
With v2.0, we've introduced Sequential Agentic Workflow.
The new agentic workflow allows you to:
⛓️Chain agents together
🔁Loopback mechanisms
🙋Human-in-the-Loop
🔶Conditional branches
Different from existing chatflow which relies LLM to act on its own, now you have greater control over the flow. Huge shoutout to @langchain team for the exceptional LangGraph framework, which made all of this possible!
We're also excited to announce the closed beta release of Flowise Cloud! In addition to all existing features, cloud version also includes Evals and Logging. Join the waitlist here: https://t.co/SOcmrBsKCd
Here's 7 examples to help you get started with agentic workflow:
Say hello to GPT-4o, our new flagship model which can reason across audio, vision, and text in real time: https://t.co/MYHZB79UqN
Text and image input rolling out today in API and ChatGPT with voice and video in the coming weeks.
Google just announced huge Gemini updates, a Sora competitor, AI agents, and more.
The 12 most impressive announcements at Google I/O:
1. Project Astra: An AI agent that can see AND hear what you do live in real-time.
🚙💬Meet Lingo-2, a groundbreaking AI model that navigates roads and narrates its journey. Watch this video taken from a LINGO-2 drive through Central London 🇬🇧 The same deep learning model generates real-time driving commentary and drives the car.
Introducing Meta Llama 3: the most capable openly available LLM to date.
Today we’re releasing 8B & 70B models that deliver on new capabilities such as improved reasoning and set a new state-of-the-art for models of their sizes.
Today's release includes the first two Llama 3 models — in the coming months we expect to introduce new capabilities, longer context windows, additional model sizes and enhanced performance + the Llama 3 research paper for the community to learn from our work.
More details ➡️ https://t.co/nFll4exicO
Download Llama 3 ➡️ https://t.co/Ps0OAHt0RR
🥁 Llama3 is out 🥁
8B and 70B models available today.
8k context length.
Trained with 15 trillion tokens on a custom-built 24k GPU cluster.
Great performance on various benchmarks, with Llam3-8B doing better than Llama2-70B in some cases.
More versions are coming over the next few months.
https://t.co/EkU9aIHdZE
Introducing Sora, our text-to-video model.
Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions.
https://t.co/YYpOAcrXQ3
Prompt: “Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes.”