🎉 New blog post! 🎉
" A Practical Guide for Kafka Cost Reduction "
Managing your own Kafka clusters? Here are few tips and KIPs you can implement to cut costs! 💸 >
https://t.co/SjyfVsMBPN
#kafka#cost#costreduction#cloud
@dhh That’s impressive! 👏
Recently, after yet another downtime of a vendor I built the this one for fun.
Keen to hear your thoughts on reliability challenges in the new “AI era”.
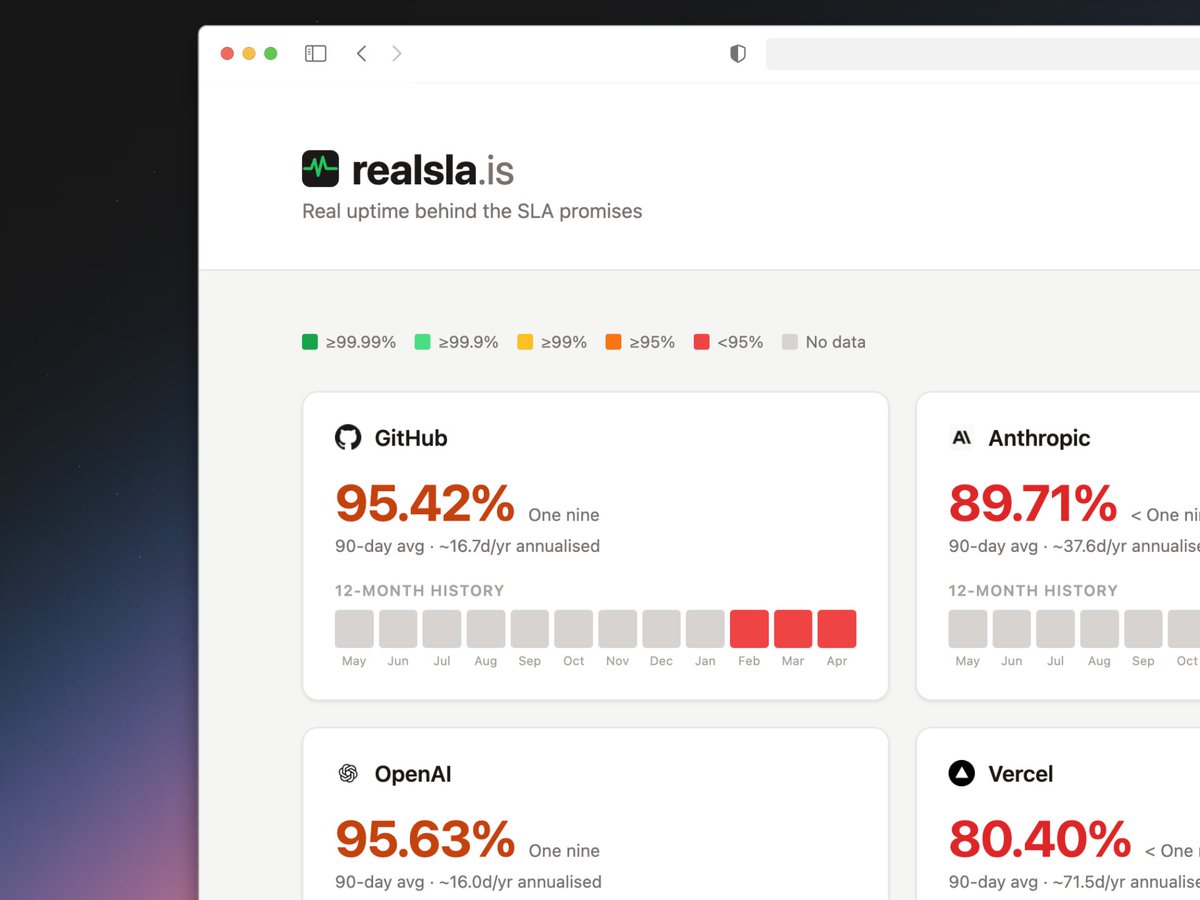
Vendor went down again.
I thought - do they *actually* deliver on their advertised 99.9% uptime..?
So I built https://t.co/llZhXUicPK to find out. Scoring isn't perfect, and a bit naive (https://t.co/haKtXjsZCJ), but the gap between promised and actual uptime was eye-opening!
Vendor went down again.
I thought - do they *actually* deliver on their advertised 99.9% uptime..?
So I built https://t.co/llZhXUicPK to find out. Scoring isn't perfect, and a bit naive (https://t.co/haKtXjsZCJ), but the gap between promised and actual uptime was eye-opening!
I'm delighted to have been selected as a judge for the
🏆 𝟮𝟬𝟮𝟱 𝗗𝗮𝘁𝗮 𝗦𝘁𝗿𝗲𝗮𝗺𝗶𝗻�� 𝗔𝘄𝗮𝗿𝗱𝘀 🏆
I'm looking forward to reviewing how organisations are using data streaming to drive meaningful business outcomes and tackle complex challenges!
https://t.co/IjqyAGXEwy
@gwenshap 2015, right after the “init wars”, had to switch all our fleet to systemd. Pushed a bad Puppet module which took down *all services including SSH* of entire region running on OpenStack. Was a 2 days nightmare to recover.
@ReadwiseReader@readwise Looks awesome! For me, the most used feature of Pocket was offline reading. Doing some tests with @ReadwiseReader, it seems like I need to click every article to sync it offline?
During the power outage in Spain and Portugal, the local AWS datacentres kept humming thanks to careful planning and preparation. Remember: Everything fails, all the time, so plan for failure and nothing fails.
https://t.co/CKvlxERulm
I've spent the past ~2 years thinking about building on top of object storage, especially about trying to build high throughput low latency OLAP-like systems. So I wrote down some of my thoughts and lessons >>>
I'm excited to be speaking at SREday London 2025!
Join me on March 27-28 to hear how we built a foundational, cloud-native, Streaming Platform using the operator pattern (and some magic ✨)
Register here:
https://t.co/GgzeUiYiOT
Use the code 𝗟𝗗𝗡𝟭𝟬 for 10% off!
From benchmarks to real-world execution for platforms like #Kafka, Pulsar, NATS, or RabbitMQ, @EladLeev will dive into stress testing & how to fine-tune performance and scalability at Monster Scale Summit. Save your spot in our free event today! https://t.co/PL6374JLTR
#ScyllaDB
@gwenshap A mixture of Kafka Connect and Flink.
In our case, we wrapped it in our own CRDs to abstract away most of the burden involved. Devs just deploy a “Connector” object with minimal configuration and behind the scenes all the magic happens
From benchmarks to real-world execution for platforms like #Kafka, Pulsar, NATS, or RabbitMQ, @EladLeev will dive into stress testing & how to fine-tune performance and scalability at Monster Scale Summit. Save your spot in our free event today! https://t.co/PL6374JLTR
#ScyllaDB
Slightly different from my usual posts, but I wrote a thing!
This time, on how to transform Slack from a distraction into a productivity powerhouse for engineering teams with proven strategies for channel organization, automation, and data-driven insights
https://t.co/ZmIZCJ5krp
🚀 Exiting news for Python devs!
Ismail Simsek's pydbzengine brings the power of Debezium's embedded engine to Python, unlocking seamless change data capture capabilities. The best of both worlds! 🔥
#Python#Debezium#CDC
Checkout the full article:
https://t.co/4m4HOOEvCD
From benchmarks to real-world execution for platforms like #Kafka, Pulsar, NATS, or RabbitMQ, @EladLeev will dive into stress testing & how to fine-tune performance and scalability at Monster Scale Summit. Save your spot in our free event today! https://t.co/PL6374JLTR
#ScyllaDB
We asked our Catalysts to share their top 3 recommendations for anyone starting out with Apache Kafka® and Apache Flink®.
Elad Leev shares his advice for diving into data streaming. Learn more about our Catalysts of the week -> https://t.co/j2bgzeDthi
Successfully divvying up your time as a staff+ engineer means intentionally separating tasks priority, consultation, and hobby brackets. https://t.co/o4SH1zfXjs via @theleaddev
@gunnarmorling 👋
As part of our Kafka clients, we ingest them as msg headers. For now, just useful for debugging, in the future the plan is to integrate it as part of Data governance, policies and discoverability
ICYMI: Meet the Confluent Community Catalyst Class of 2024-2025! 🌟 These exceptional data streaming enthusiasts are champions in the dev community & we’re excited to see all the amazing things they'll achieve! Learn about our Catalyst Program -> https://t.co/qCUECOEM1p