I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.
@nytimes this article is so retarded that I genuinely almost canceled my subscription. why do you let this person write. “perks inequality??” what the fuck. “shame” from flying in coach?? get a fucking life.
https://t.co/fhfVJsbi7H
I strongly believe there are entire companies right now under heavy AI psychosis and its impossible to have rational conversations about it with them. I can't name any specific people because they include personal friends I deeply respect, but I worry about how this plays out.
I lived through the great MTBF vs MTTR (mean-time-between-failure vs. mean-time-to-recovery) reckoning of infrastructure during the transition to cloud and cloud automation. All those arguments are rearing their ugly heads again but now its... the whole software development industry (maybe the whole world, really).
It's frightening, because the psychosis folks operate under an almost absolute "MTTR is all you need" mentality: "its fine to ship bugs because the agents will fix them so quickly and at a scale humans can't do!" We learned in infrastructure that MTTR is great but you can't yeet resilient systems entirely.
The main issue is I don't even know how to bring this up to people I know personally, because bringing this topic up leads to immediately dismissals like "no no, it has full test coverage" or "bug reports are going down" or something, which just don't paint the whole picture.
We already learned this lesson once in infrastructure: you can automate yourself into a very resilient catastrophe machine. Systems can appear healthy by local metrics while globally becoming incomprehensible. Bug reports can go down while latent risk explodes. Test coverage can rise while semantic understanding falls. Changes happens so fast that nobody notices the underlying architecture decaying.
I worry.
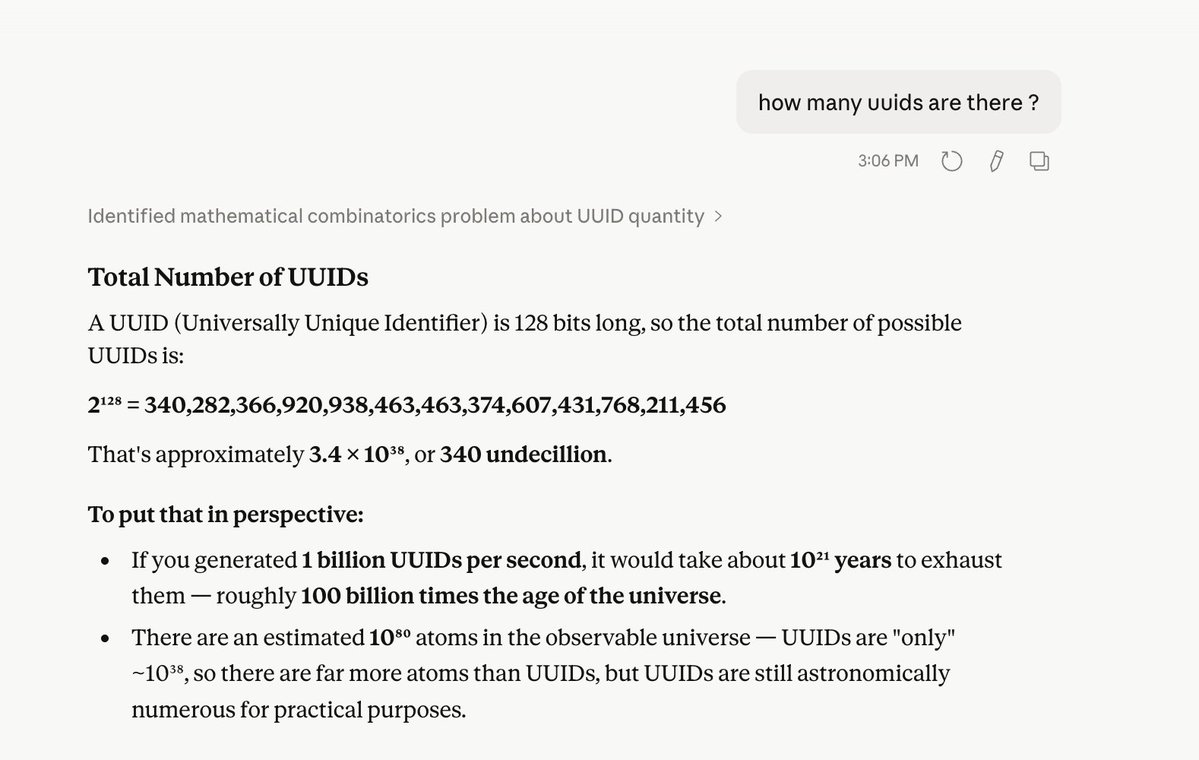
I was planning to use UUIDs to represent the databases we have on the @tursodatabase Cloud. I got a bit worried that we would perhaps run out of UUIDs. I just double-checked and I think we'll be fine for the next year or so.
Will use UUIDs for now, and if needed, rearchitect later.
I’m excited about the AllBirds AI pivot because this is the first completely pure act of retardmaxxing in the public markets and I’m so on board with watching that journey play out.
@DanielLockyer telemetry libraries are terrible for performance and memory usage
they have to monkey-patch APIs and clone lots of data to make it work. they haven’t tried very hard to make it not slow