A civilization that could carve this into a door treated beauty as a public duty.
Stand before the door of Duomo di Milano long enough, and the modern world begins to look painfully soulless.
The creator of Linux just publicly called out the AI hype. Word for word.
Linus Torvalds took the stage at Open Source Summit 2026 and said this:
"When I see people saying 99% of our code is written by AI, I literally get angry. Because those same people — I can pretty much guarantee — 100% of their code is written by compilers. But they never say that."
He is not anti AI. The Linux kernel saw a 20% jump in submissions this release because of AI tools. He uses it. He gets it.
His point is something most people are too afraid to say.
AI is a productivity tool exactly like compilers were. Compilers boosted programming by 1000x. AI adds another 10x on top. Enormous. But nobody says "the compiler wrote my code." So why are we saying AI wrote it?
He also flagged something nobody is talking about.
AI is flooding small open source projects with drive-by bug reports. Someone runs a prompt, files a report and disappears when asked for a patch. Maintainers with one or two people are drowning trying to keep up.
"Sometimes AI reports a bug and when you ask for more information the person has done that drive-by and does not even answer your question. That is the real burnout issue."
And his final warning was the sharpest of all.
"People who do not understand the complexity of systems will prompt systems and write processes that will fail."
The AI hype crowd is very loud right now.
Linus has been building real systems for 35 years. When he talks, engineers listen.
Full interview here:
https://t.co/LmXJtvKc4O
LeetCode but for Linux, Docker, Kubernetes, and Networking problems? 🤔
245 hands-on challenges (over half are free) based on real-world scenarios that come with:
- Preconfigured environments
- Automated verification
- Hints and editorial solutions
https://t.co/ZTwhoT3YZx
A process suddenly consuming 99% of your CPU at 2 AM can turn a stable server into a slow, unresponsive mess. The good news is that Linux offers several ways to prevent this from becoming a problem.
👉 https://t.co/GamXwn59k0
Follow @tecmint for more #Linux tips...
I'm giving away FREE copies of my AWS Compute Architecture Playbook to 20 learners (100% FREE).
Inside you'll get:
✅ 10 production-grade AWS architecture projects
✅ Security, WAF & IAM design patterns
✅ Reliability, performance & cost optimization insights
✅ Real-world architecture diagrams
✅ Serverless, Containers, Kubernetes, Batch & Edge Computing use cases
Share - "How will this guide help your career?"
Examples:
• Upskill in AWS Architecture
• Prepare for Cloud/DevOps interviews
• Land your first cloud job
• Switch into DevOps or Cloud
• Become a Solutions Architect
• Learn production-grade AWS designs
Will select 20 learners who genuinely need it.
Winners announced in 24 hours.
Good luck 🚀
also got this scammer in my dms (but from a different account)
they reached out to me with the same offer (usdc payment + merch) to hop on their space which is not conventional at all.
please stay safe, suspicious, and vigilant!
"We use Prometheus for monitoring."
I hear this in almost every interview. Then I ask one question and the whole thing falls apart.
"Why do logs and metrics need different pipelines?"
Silence.
Most people jump into Prometheus and Grafana without understanding what they're actually solving. They know the tools. They can't explain the problem.
With observability, you're solving two completely different problems.
Logs tell you what happened. An error occurred. A request came in. A database query failed. These are events. Stories your application tells.
Metrics tell you how things are performing right now. Latency is 200ms. CPU is at 75%. You processed 500 requests per minute. These are measurements.
Different data types. Different collection methods. Different storage. That's where people get confused.
Last month in my DevOps bootcamp, we built a complete observability system for microservices on Kubernetes.
For logs, we used Fluentd sidecars that share a volume with the application container.
The app writes logs to the volume.
Fluentd reads and forwards them.
Clean separation of concerns.
At a small scale, you send logs straight to CloudWatch.
But when you're generating thousands of log lines per second, you add layers.
Lambda for formatting.
Kinesis for buffering.
OpenSearch for fast queries across petabytes of data.
S3 for long-term backup.
We kept 7 days in OpenSearch for active investigation. 30 days in CloudWatch. Years in S3 for compliance. Each layer has different cost and performance characteristics.
For metrics, Prometheus scrapes application endpoints every 30 seconds.
Developers instrument their code with Prometheus client libraries.
They expose a /metrics endpoint.
Prometheus pulls the data automatically.
We created ServiceMonitors that tell Prometheus which pods to scrape based on labels.
As soon as new pods come up, Prometheus discovers and scrapes them.
Then Grafana visualizes everything.
We imported pre-built dashboards from https://t.co/5wE21Lb4Q8 for Kubernetes monitoring.
And built custom panels for application-specific metrics.
Logs and metrics run in parallel.
When something breaks, metrics show you the spike. The error rate jumped. Latency went from 100ms to 2 seconds.
Then you check the logs. Filter for that time window. Find the stack traces. See exactly what failed.
You can't troubleshoot with just one. You need both perspectives.
We implemented it, troubleshot everything in a live call, generated real metrics and logs, and built dashboards in Grafana.
That's the difference between watching tutorials and actually understanding how systems work in production.
Episode 92 With Star Platinum
Star has been a good friend of mine the last few years
It has been fun to watch him write threads on his phone and outcompete 99% of creators
He is consistently getting ahead of the crowd because he treats content like a job while respecting it as an art
We got to talk about all things content and what’s next for him and why he is pursuing it
2:23 @StarPlatinum_ building audience on CT
5:52 One platform for ten years which one
8:09 Writing viral threads on his phone
11:50 Spanish crypto media gets news late
20:18 Would you ever retire from content
27:47 Reply guy meta is a trap
31:29 Trump net positive or negative for crypto
38:47 Nikita and the X takeover hot take
43:17 How he would rewire the X algorithm
50:02 How to stay on top in CT
51:37 Inbound brand deals on traditional media
It's serious concern!
AI is getting exposed day by day.....
Sometime it's cost
Sometime it's incapability to handle work with 100% efficiency
Sometime it's security concerns.....
No-one is 100% sure about the solution they are offering to client.....build by AI!
Let's see how far we go....
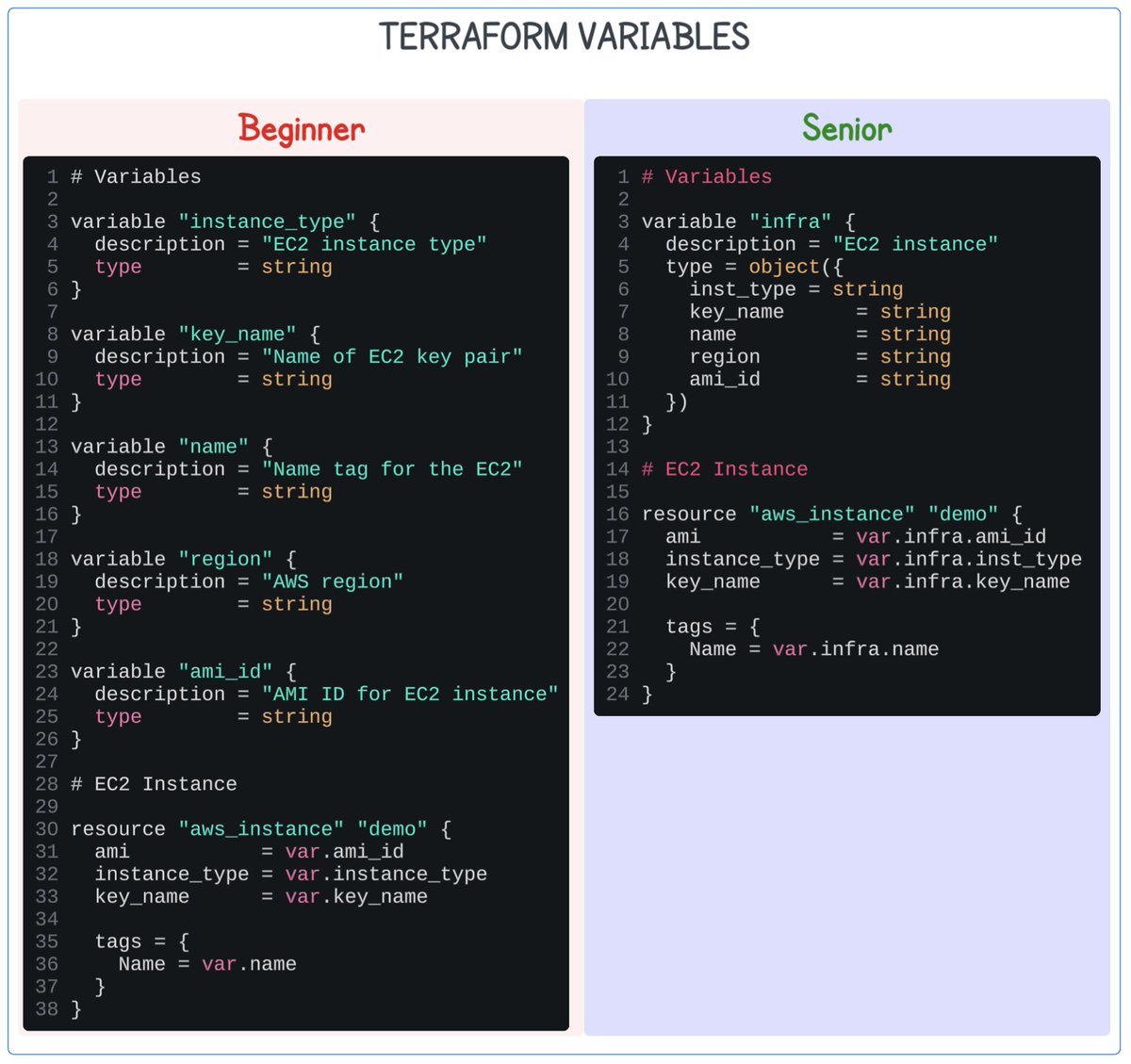
How do you declare your Terraform variables?
There is the traditional way we see in every tutorial:
- One variable for instance_type
- One variable for ami_id
- One variable for key_name
- etc.
It works fine.
But once you join real-world projects, you start seeing another approach:
- Group related variables into one object.
It is cleaner and more professional.
- It keeps related values together.
- It makes the module easier to read.
- It scales better when your infrastructure grows.
Where is your seed phrase stored right now?
No, seriously.
Because if it's stored in ANY of these places, malware can find it in seconds:
❌ Notes app
❌ Photos
❌ Email
❌ Google Docs
❌ iCloud backups
❌ Encrypted USBs
❌ Anywhere online
Most people think:
"It's encrypted, so I'm safe."
Wrong.
Modern wallet-stealing malware doesn't care where you hid it.
It searches your device for 12- or 24-word combinations matching the 2,048 simple words your seed phrase is generated from and sends them to the attacker automatically.
Your wallet can be emptied before you even realize you're infected.
And here's the uncomfortable truth:
If you created your wallet in a browser or on your phone, that seed phrase was generated online...
So what should you do?
✅ Buy a hardware wallet
✅ Generate a new seed phrase
✅ Store the seed phrase offline
Best options:
• Paper backup stored securely (Minimum)
• Metal backup (CryptoTag Zeus, etc.) (Preferred/Recommended)
If you need help my DMs are always open!
Stay Safe & Stay Vigilant
Spent this weekend documenting 10 real-world AWS compute projects every Cloud/DevOpsengineer should understand.
From Serverless APIs and ECS/EKS to event-driven systems, AWS Batch, App Runner, andedge delivery.
Would you like a copy when it's ready?
Drop a 👍 and share it to show your support.
Most containers run as root.
> Someone told you that's bad.
> So you made your container run as a non-root user.
>You felt good about yourself. "I follow security like a pro."
Then your container, which was earlier writing to a volume, stopped writing. And you are debugging at 4 AM.
> Because Kubernetes mounts a volume as root by default.
> Your non-root container cannot write to it.
> Now you go to Reddit, where someone points you to fsGroup with a detailed comment
--> fsGroup is a pod-level security context setting.
--> When you set it, Kubernetes changes the ownership of the mounted volume to that group ID before your container starts.
--> Your non-root user, who belongs to that group, can now write to it.
> You feel happy again.
But that was not all. You need more than just that
Security context is not one setting. It's a combination of things
> runAsNonRoot ensures the container does not start if the image is configured to run as root.
> runAsUser sets the exact UID your container process runs as.
> fsGroup fixes volume ownership so your non-root process can read and write.
> readOnlyRootFilesystem prevents anything from writing to the container's own filesystem.
> allowPrivilegeEscalation false ensures your process cannot gain more privileges than it was started with.
Basically, drop all Linux capabilities and add back only what your app actually needs.
Miss one of these, and you think you're secure. You're not. You just moved the problem somewhere else.
Despite all the billions and millions that $MSTR , Bitcoin treasury companies and all the institutions with their Bitcoin ETF's have been throwing at it, they failed to realize two things:
- not your keys, not your coins
- if it doesn't happen on chain, it did not occur.
A lot of paper is moving among custodians.
Very little Bitcoin itself.