But am I the only one who switched to Codex to validate all the recent feedback, but find that Opus 4.8 consumption lasts 3-4 times longer in 5 hours, compared to GPT-5.5 Low? How is it possible that everyone else says the opposite?
Any recommendations for terminals/wrappers to manage multiple https://t.co/qP1K3Rlq1n sessions externally? 👀
Ideally with remote/shared session support too.
I saw @davis7 mention cmux, any other good options? tmux wrappers, web terminals, orchestrators, etc.
Benchmarking the line tag for edits idea from @antirez in my agent runtime.
Results show, at least for my implementation, that it works best for big changes and probably not worth it for smaller ones.
Need to explore how it scales on long running agentic sessions, these tests are currently one off simple tasks.
His blog post about this idea: https://t.co/WXxOAssBX8
Been using @sveltejs for a few projects lately, it's quite a nice alternative to React, fewer gotchas and complexity and Codex handles it really well. https://t.co/b2KdDvrpLD
@saen_dev The problem I see is related to re-processing. A single diff could impact a lot of derived resources, and detect dead references is probably hell 😵
Hey #buildinpublic 👋
Fast & messy vibe-coding = fun.
LLM wiki for the growing codebase = outdated docs + fortune in reprocessing.
Anyone built a smart self-updating LLM system that stays fresh cheap?
Wins, hacks or fails? Reply! 🤔
@vadym_petryshyn Yes, but llm wiki generate clean documentation, when you change a file, you need to refresh derived docs, remove outdated pieces and compress informations
DS4 is now called DwarfStar4, since you can put a lot of mass into a tiny space... And in a few minutes it is going to be much better on 128GB Macs because I'l pushing much better 2 bit quants generated with an in-house iMatrix magic recipe.
the new @OpenAI realtime voice model just released + gpt 5.5 fast mode brings us a new possibility -
realtime speech to live presentation!
i just talk, and the whiteboard would whiteboard itself
prototype is open sourced. details in thread below -
Last week, Deepseek v4, today this
I see it increasingly difficult for OpenAI and Anthropic to ever repay their infinite debts if AI computation becomes this cheap 😵
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
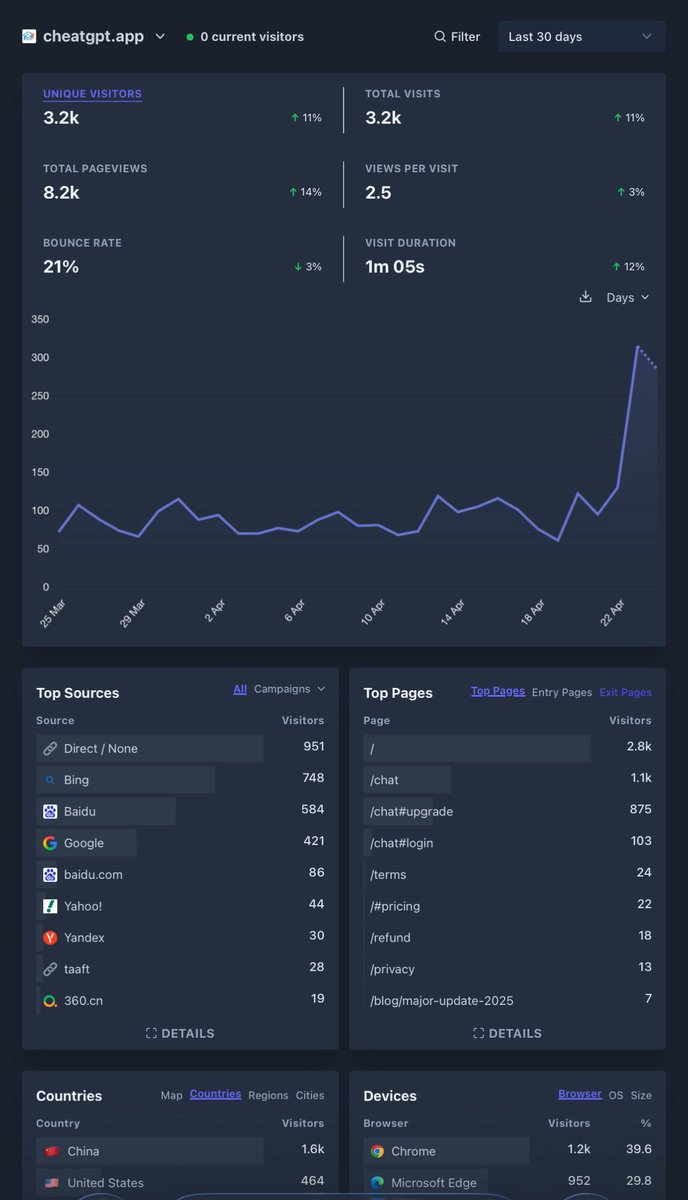
Any suggestions on how to monetize this traffic? Conversions have almost completely stalled these days.
Happy to share new revenue with anyone who can help improve conversions 🤔