⚠️ Critical Apache HTTP Server Flaw Exposes Millions of Servers to RCE Attacks
Source: https://t.co/nyaOOtouZa
The Apache Software Foundation has released a critical security update for Apache HTTP Server, patching five vulnerabilities, including a dangerous double-free flaw capable of enabling Remote Code Execution (RCE) in version 2.4.67, released on May 4, 2026.
All users running version 2.4.66 or earlier are strongly urged to upgrade immediately. The most severe of the five vulnerabilities is CVE-2026-23918, rated High with a CVSS base score of 8.8.
The flaw is a double-free memory corruption bug triggered within Apache's HTTP/2 protocol implementation during an "early stream reset" sequence.
#cybersecuritynews #vulnerability
Recursive Language Models (RLMs) Architecture 👀
The manuscript evaluates the referenced GPT-5 and Qwen3-8B, but access conditions are unclear
#Code is available at https:
//github.com/alexzhang13/rlm
#Paper : https://t.co/9SJgngDXwO
#RLM
¿Dominas la Arquitectura Hexagonal? 🏗️✨
Aprende con Enrique Medina la implementación práctica para lograr un código desacoplado y testeable por diseño. ¡Charla virtual imperdible!
📅 28 de abril - 01:00 PM GMT-5
📺 Míralo aquí: https://t.co/7MoP2KPV4M
#Java#HexagonalArchite
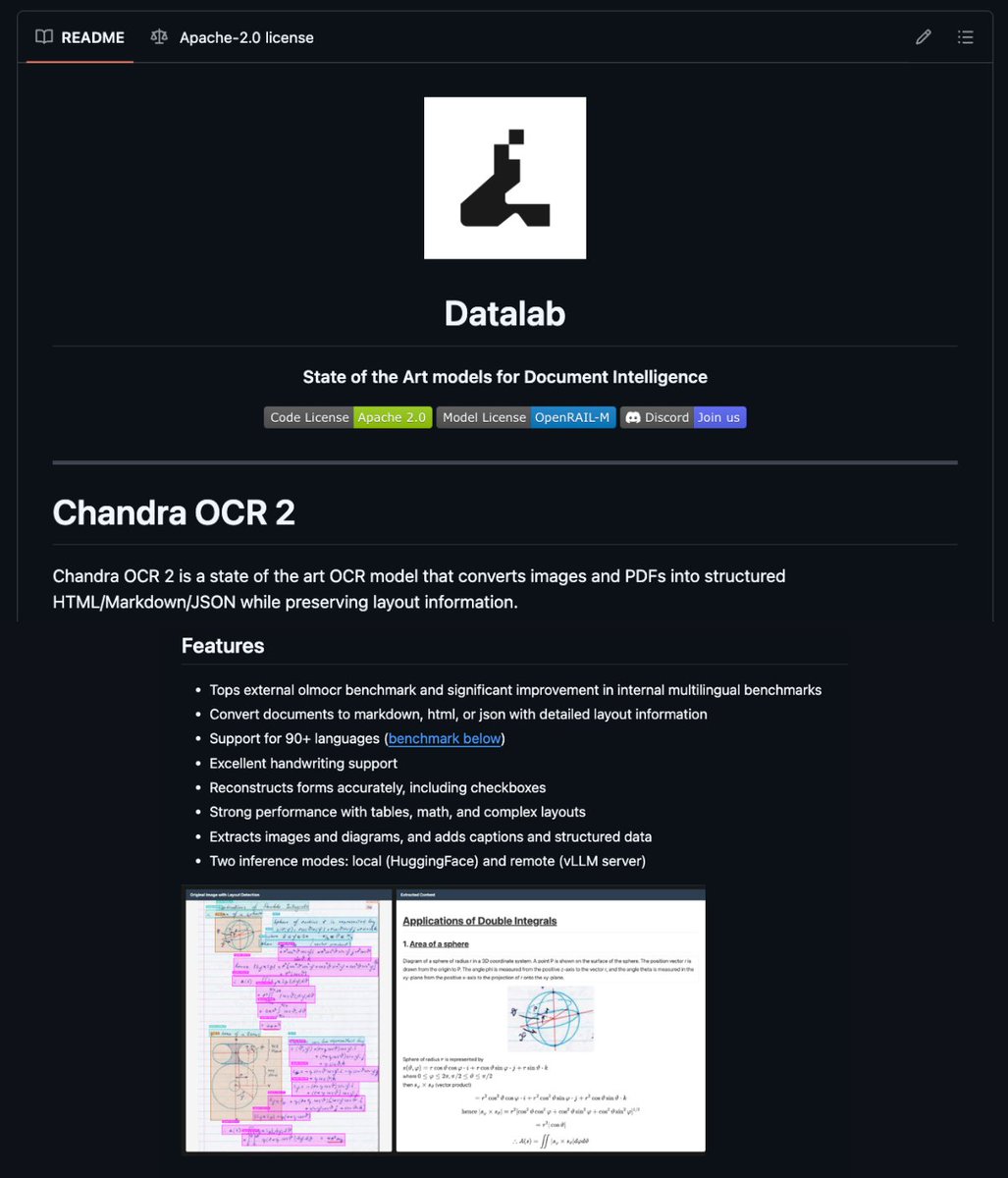
I found a GitHub repo that reads doctor handwriting.
It's called Chandra. It handles forms, tables, math equations and cursive documents that have defeated OCR for 30 years.
One command. Full layout preserved.
→ Reads handwriting, cursive, and messy print with full accuracy
→ Reconstructs merged table cells including colspan and rowspan
→ Renders inline math and block equations as LaTeX automatically
→ Extracts checkboxes, radio buttons, and form fields with their values
→ Outputs Markdown, HTML, or JSON with bounding box coordinates for every element
→ Supports 40+ languages out of the box
→ Runs locally via HuggingFace or on a vLLM server for production throughput
Tested on 10K financial filings, medical forms, LA Times newspapers, and college worksheets.
It beats every baseline on the OLMOCr benchmark.
100% Open Source. Apache 2.0. 4.8K stars.
Repo: https://t.co/nrCGKxLCC9
Vibecoded your app with AI? 5 things that break:
- ❌ Zero error handling
- 🔓 Security nightmares
- 🧩 Spaghetti architecture
- ⚡ Performance collapse
- 📱 App Store rejections
AI = 80% - Pro polish = the rest
Read: https://t.co/Co8AbpZt2D by @Commit451
🎂 Commonhaus Foundation Marks Two Years as Open Source’s ‘Missing Middle’ — and Maintainers Are Taking Notice.
Commonhaus’ 2nd anniversary
https://t.co/2FGFFBPmyM
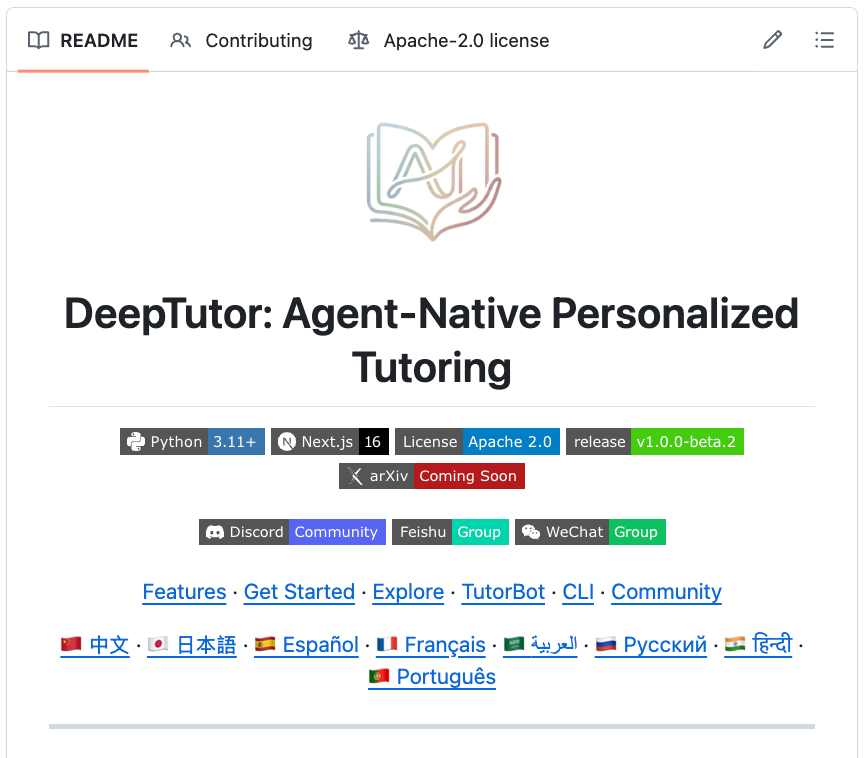
DeepTutor turns your docs into a real learning system.
Upload papers, textbooks, notes → get step-by-step reasoning, quizzes, and guided learning paths.
Multi-agent + RAG + knowledge graphs, all in one.
Not just answers. It actually teaches.
🚨 PDFs are officially broken.
Someone just dropped a tool that converts PDFs → clean Markdown
at 100 pages/sec 🤯
Tables? Extracted.
Messy layouts? Fixed.
Nested data? Perfect.
No GPU. No cost. No excuses.
It’s called OpenDataLoader.
This kills 90% of manual data work.
repo link: → https://t.co/mVMYLMMDJP
MICROSOFT BUILT A TOOL THAT CONVERTS LITERALLY ANYTHING INTO CLEAN MARKDOWN FOR YOUR LLM
pdfs. word docs. excel. powerpoint. audio. youtube urls
one pip install and your AI pipeline stops choking on raw files forever
no custom parsers. no broken layouts. no garbled text.
just clean, structured markdown your LLM can actually read
https://t.co/RSt0CczfYa
🚨 Tutors charge $50/hour. Coursera charges $50/month. Someone built an AI that uploads your textbooks and becomes a personal tutor that never sleeps. 10,300 GitHub stars. Free.
It's called DeepTutor.
An AI-powered learning assistant that reads your textbooks, research papers, and documents. Then teaches you from them. Personally.
Not a chatbot. Not a search engine. A full multi-agent tutoring system that solves problems step by step, generates practice exams, creates visual explanations, and conducts deep research. All from YOUR materials.
Here's what this system does:
→ Upload textbooks, papers, technical docs. It builds a knowledge base from YOUR content.
→ Ask any question. AI answers with step-by-step solutions and citations from your materials.
→ Generates quizzes and practice problems matched to your level
→ Upload a real exam. It creates practice questions that mimic the exact style and difficulty.
→ Deep Research mode: decomposes topics, dispatches parallel agents, produces cited reports
→ Guided Learning: turns your materials into visual, interactive learning paths
→ AI Co-Writer: markdown editor where AI helps you write, rewrite, and expand
→ Personal TutorBots: autonomous tutors with their own memory, personality, and workspace
Here's the wildest part:
TutorBots are not chatbots. They're autonomous agents with soul files that define their personality. Create a Socratic math tutor. A patient writing coach. A rigorous research advisor. All running simultaneously. Each with its own memory. Each evolving as you learn.
They even have a heartbeat system. Your tutor shows up with study reminders and review check-ins. Even when you don't ask.
An AI tutor that initiates. That remembers. That adapts. That never bills you.
Private tutors: $50 to $100/hour. Coursera: $50/month. Chegg: $15/month. University tuition: $20,000+ per year.
This is free. Self-hosted. Your data stays on your machine.
10.3K GitHub stars. 1.4K forks. Built by HKU Data Intelligence Lab. AGPL-3.0 License.
100% Open Source.
🚨 JUST IN: MICROSOFT just open sourced a VOICE AI THAT TRANSCRIBES 60 MINUTES OF AUDIO in a single pass. 100% FREE.
It knows who spoke.
It knows when they spoke.
It knows exactly what they said.
All in one shot. No chunking. No context loss.
It's called VibeVoice.
Not a transcription tool.
Not a basic speech to text wrapper.
A frontier voice AI family with ASR, TTS, and real time streaming. All open source. All free.
Here's what it actually does 👇
VibeVoice ASR - Speech Recognition:
→ Processes 60 minutes of continuous audio in a single pass
→ Never slices audio into chunks so global context is never lost
→ Identifies WHO spoke, WHEN they spoke and WHAT they said simultaneously
→ Supports customized hotwords for domain specific accuracy
→ Works in 50+ languages natively
→ Already adopted by Hugging Face Transformers library
→ Already being built on by the open source community
BY PEOPLE WHO HAD NO IDEA THIS LEVEL OF ACCURACY WAS ALREADY FREE.
VibeVoice TTS - Text to Speech:
→ Generates up to 90 minutes of speech in a single pass
→ Supports up to 4 distinct speakers in one conversation
→ Natural turn taking and speaker consistency throughout
→ Expressive speech that captures emotional nuances
→ Supports English, Chinese and multiple other languages
VibeVoice Realtime - Streaming TTS:
→ Only 300 millisecond first audible latency
→ Streams text input in real time
→ 0.5B parameters so it actually deploys anywhere
→ Robust long form generation up to 10 minutes
→ Lightweight enough for production use today
The core innovation nobody is talking about:
Most voice AI models slice long audio into short chunks.
Every time they slice, they lose context.
Speaker tracking breaks. Semantic coherence breaks. Accuracy drops.
VibeVoice uses continuous speech tokenizers running at an ultra low frame rate of 7.5 Hz.
This preserves audio fidelity while dramatically boosting computational efficiency.
The entire 60 minutes stays in context.
Nothing gets lost. Nobody gets misidentified.
The numbers:
→ VibeVoice ASR 7B - available now on Hugging Face
→ VibeVoice Realtime 0.5B - try it on Colab right now
→ 50+ supported languages
→ 11 distinct English voice styles
→ 9 multilingual speaker voices
→ Already integrated into Hugging Face Transformers
→ Finetuning code now available
The wildest part?
A voice powered input method called Vibing just built itself on top of VibeVoice ASR.
Available on macOS and Windows right now.
The open source community is already shipping products on top of this.
100% Open Source.
Free to use. Free to fine tune. Free to build on.
🔖 Save this before your competitors find it first. 👇
🚨 Extracting data from PDFs just got solved.
Someone open-sourced a tool that turns PDFs into Markdown at 100 pages a second 🤯
It’s called OpenDataLoader.
It runs flawlessly on CPU and decodes tables, complex layouts, and nested structures like an absolute pro.
Best part?
100% free and open-source.
Grab the repo link in the 🧵↓
Imagine trying to teach someone how to swim just by letting them read books about water.
That is how we have been training AI on physics, using text descriptions.
To really learn, you need to get in the water.
"The Well" is that water.
Polymathic AI has released a massive 15TB open-source library of physics simulations. It allows AI models to experience physical phenomena directly.
Instead of reading about a supernova, the model processes the actual data of the explosion. Instead of reading about aerodynamics, it analyzes the fluid flow.
This moves us from [Generative AI] (making things up) to [Scientific AI] (discovering truth).
A huge step forward for open science.
GitHub Repo: https://t.co/xgUdqncyRH
This 2 hour Stanford lecture on AI careers will teach you more about winning in the AI race than every piece of AI content you have scrolled past this year.
Bookmark this & give it 2 hours, no matter what. It'll be the most productive thing you could do this weekend.
Everything you need to build with #JakartaEE, in one place.
💻 The Jakarta EE developer portal brings together the tools and resources developers rely on to build modern enterprise applications.
Explore:
🔹 Getting started guides
🔹 Hands-on tutorials and examples
🔹 Specifications and release information
🔹 Compatible products across the ecosystem
Spend less time searching, more time building 👉 https://t.co/smiKtXsbcH
#JakartaEE #Java #opensource #CloudNativeJava
🚨BREAKING: A dev just open-sourced the #1 ranked OCR model on Earth.
It's called GLM-OCR and it just hit 94.62 on OmniDocBench V1.5, beating every OCR model in existence.
Only 0.9B parameters. One pip install. Handles documents no other model could touch.
100% Open Source.
En sólo 2 semanas floci ha alcanzado 2k stars en GitHub.
Repo: https://t.co/nab0sJsuL6
Esta noche tenemos una sesión con el creador de floci @hectorvent.
Únete a nosotros para conocer todas las funcionalidades de floci y cómo seguirá evolucionando el proyecto.






























![techNmak's tweet photo. Imagine trying to teach someone how to swim just by letting them read books about water.
That is how we have been training AI on physics, using text descriptions.
To really learn, you need to get in the water.
"The Well" is that water.
Polymathic AI has released a massive 15TB open-source library of physics simulations. It allows AI models to experience physical phenomena directly.
Instead of reading about a supernova, the model processes the actual data of the explosion. Instead of reading about aerodynamics, it analyzes the fluid flow.
This moves us from [Generative AI] (making things up) to [Scientific AI] (discovering truth).
A huge step forward for open science.
GitHub Repo: https://t.co/xgUdqncyRH](https://pbs.twimg.com/media/HFC1ZQbaYAE9qoA.jpg)
































