@thornhawthorne These are always the ones who have the most problem with nonbinary people and don't think we can hear it in their voice - they're not saying that to convince us, but themselves
While I did help a little startup find the right developers for their project, I will never, ever be posting a small job on LinkedIn ever again. RIP my email and the contact form of my website (that is not what it! is! for! [internal screaming])
Anybody reading this out there - have you any experience deploying federated AI/ML systems using tools like https://t.co/ve8kVqJ1zB?
I'm falling in love with this idea especially for cases where personalization is involved. Train on user data locally, never send it anywhere
@hologramvin Yep, and the interesting thing is that anybody you think you know better/longer than a mutual is just as capable of harming you. Based on some stats for certain kinds of harm, it may be even MORE likely the more lose the relationship is.
I agree situational awareness is key.
Excited to finally be giving this talk at Microsoft tonight! If you missed the sign up or are otherwise unable to make, I think it may end up being recorded.
If it's not, I'll record a version and put it up anyways.
If you're in NYC, I'll be giving a talk on LLM systems at the Microsoft offices on May 13th - it's free to attend, and I'd be really happy to see you there
https://t.co/xkdYxIz1Kf
Thrilled to introduce RefuelLLM-2, our latest family of LLMs built for data labeling and enrichment tasks. RefuelLLM-2 (83.82%) outperforms GPT-4-Turbo (80.88%), Claude-3-Opus (79.19%), Llama3-70B (78.2%) and Gemini-1.5-Pro (74.59%) on a benchmark of ~30 data labeling tasks:
RefuelLLM-2-small (79.67%), aka Llama-3-Refueled, outperforms all comparable LLMs including Claude3-Sonnet (70.99%), Haiku (69.23%) and GPT-3.5-Turbo (68.13%). We’re open sourcing the model: https://t.co/to94D0foTx
You can try out the models here and give us some feedback! https://t.co/2LOT6qmY4F. The code and data used for benchmarking the LLMs is available in our Autolabel library: https://t.co/NdpUZ0A7pA
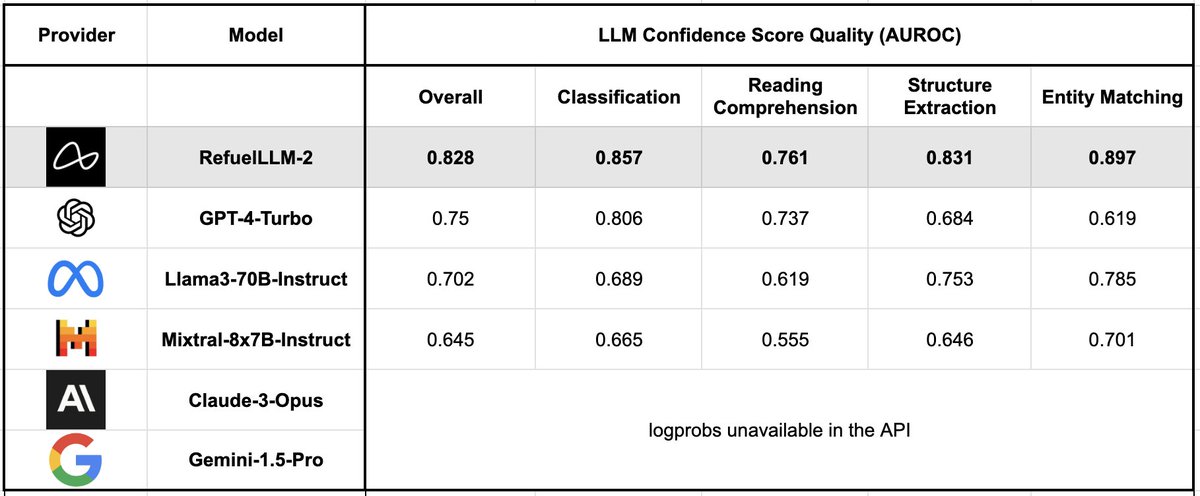
One more thing: RefuelLLM-2 family of models output much better calibrated confidence scores - a useful lever to reject, retry or ensemble low confidence outputs.
I still have an eternal love-hate relationship with regex. Inscrutable incantations.
If any junior devs are reading this, pretty much all of us have to look up the syntax and using a syntax checking tool is a best practice, considering that. Please do and don't feel bad for it.
I wish I could go back in time ten years and tell past Leo that I would eventually evolve into the kind person who's first PR at a place amounts to "this could probably be a regex instead?"
If you're in NYC, I'll be giving a talk on LLM systems at the Microsoft offices on May 13th - it's free to attend, and I'd be really happy to see you there
https://t.co/xkdYxIz1Kf
Working on reinventing the browser in the context of the latest AI boom, I feel like I did in 2012 when I was charting unexplored web APIs like shadow DOM.
Uncharted territory, no map. Creating the map is the work.