I'm a very visual person. when I was first getting into ML, I'd try to draw out every concept on pen and paper.
back then I couldn't vibe-code a visualization. but now you can!
here are my favorite ML visualizations I've been saving for a while. take them as inspo for the next complex topic you want to visualize 🧵
Visiting most of the leading Chinese AI labs, I'm struck by a culture that's extremely well suited to building LLMs with fewer resources, but one happening in a very different ecosystem, more companies at play, almost no data industry, etc.
Full report: https://t.co/ibmtMWnfTc
I spent all of Christmas reverse engineering Claude Chrome so it would work with remote browsers.
Here's how Anthropic taught Claude how to browse the web (1/7)
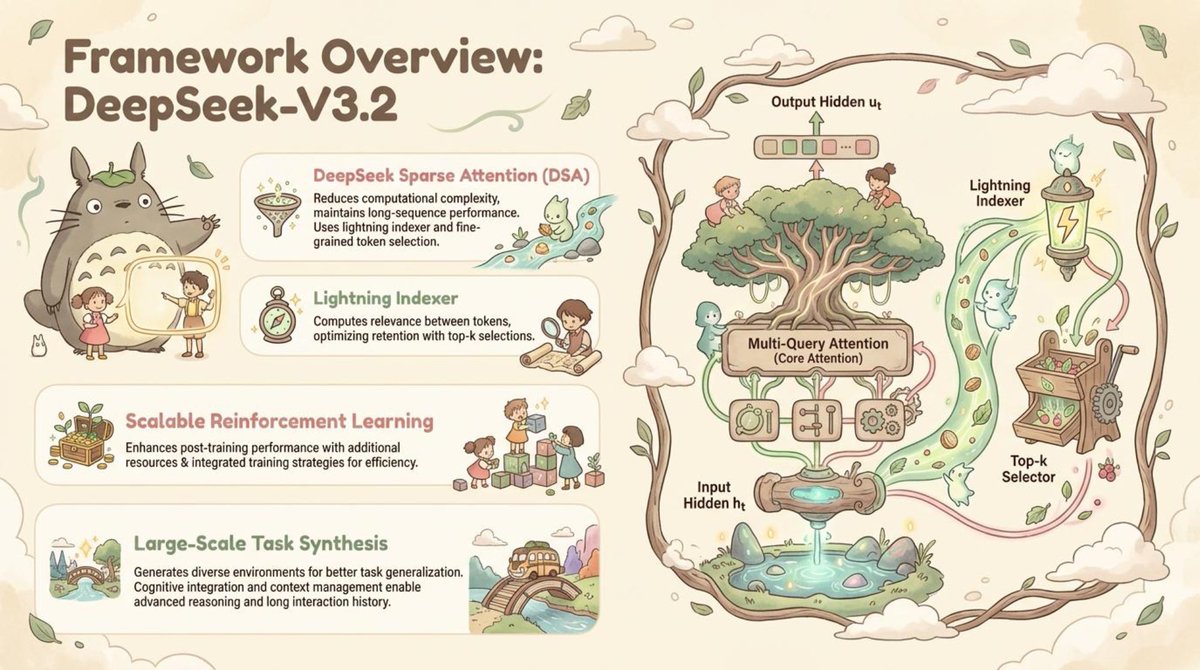
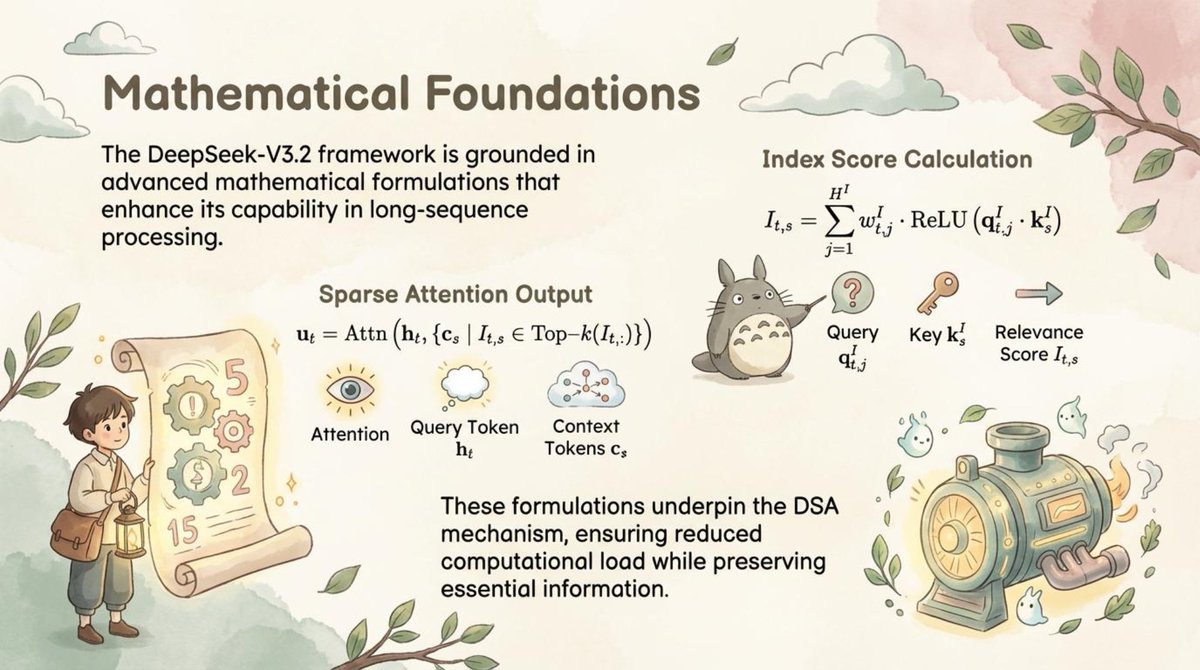
🚀 Paper2Slides is now open source! Transform research papers & technical reports into professional presentations with ONE click!
We've generated stunning presentation slides from the latest DeepSeek V3.2 paper in diverse styles - check them out and share your feedback!
🔥 Core Features:
- 📄 Multi-format support - PDF, Word, Excel, PowerPoint & more
- 🎯 Smart content understanding - Captures key insights, figures, formulas, tables & data points.
- 🎨 Custom styling - Professional themes with full personalization.
- ⚡ Lightning fast - High-quality PPT generation in minutes.
GitHub: https://t.co/zNxlFifDU3
Never build slides from scratch again! ✨ Come play with it ⭐!
#Paper2Slides #AIPPT
Today, we are releasing a new version of K2 (K2-V2), a 360-open LLM built from scratch as a superior base for reasoning adaptation, while still excelling at core LLM capabilities like conversation, knowledge retrieval, and long-context understanding.
K2 fills a major gap: highly capable models with no transparency. Instead of releasing only weights, we’re sharing the full training story — dataset recipes, mid-training checkpoints, logs, code, and evaluation tools. That’s 360-open.
What’s inside:
• 70B dense transformer engineered as a reasoning-enhanced base model
• Native 512K context (extendable via RoPE scaling)
• Mid-training reasoning phase
• Strong tool-use scaffolding
What we’re open-sourcing:
• 250M+ reasoning traces (math, planning, multi-step logic)
• Full pre- & mid-training data compositions
• All mid-training checkpoints
• Training logs, code, Eval360
Performance:
• GPQA-Diamond: 55.1% mid-training → 69.3% after SFT (strongest fully open 70B model)
• KK-8 Logic Puzzles: 83% — competitive with DeepSeek-R1 & OpenAI o3-mini-high
• ArenaHard V2: 62.1% — close to Qwen3 235B
• Outperforms Qwen2.5-72B and approaches Qwen3-235B despite being smaller and fully transparent.
🔗 The Model:
https://t.co/gsjRUwfnvN
🔗Technical Report:
https://t.co/oFZQuLQaNg
🔗Blog:
https://t.co/zQdpmLgEUt
Introducing SynCity 🌆
SynCity generates entire 3D worlds from a text prompt with no training or optimisation. It leverages pretrained 2D and 3D generators and generates scenes on a grid, tile by tile. The generated 3D environments are diverse, fully coherent, and navigable.
🧵👇
How can we evaluate LLMs across 1000+ languages? 🌎 The first step towards FineWeb Multilingual was creating FineTasks, a data-driven evaluation framework that helps select reliable evaluation tasks for any language. The @huggingface Team validated it across 9 different languages and evaluated 35 open and closed LLMs. 👀
TL;DR:
🎯 Created FineTasks - a framework for selecting reliable multilingual evaluation tasks
📊 Tasks based on 4 key metrics: monotonicity, low noise, non-random performance, and model ordering consistency
🔍 Tested 185 tasks across 9 diverse languages (Chinese, French, Arabic, Russian, Thai, Hindi, Turkish, Swahili, Telugu)
📋 Selected 96 final tasks covering reading comprehension, general knowledge, language understanding, and reasoning
🧪 Found task formulation matters: Cloze Format better for early training, Multiple Choice Format for later evaluation
📈 Metrics recommendation: Use length normalization for most tasks, PMI for complex reasoning
🔥 Open models are narrowing the gap with closed-source models in multilingual performance.
🏆 Evaluated 35 open and closed-source LLMs; Qwen 2 models dominated high/mid-resource languages: Gemma-2 excelled in low-resource languages
🌐 Framework supports 550+ tasks across various languages
I can't believe I need to say this, but run the code below in your local Jupyter notebook and save 138,830 arXiv papers in multi-markdown format now before they're gone! 😅
Available on @huggingface Datasets: https://t.co/5sOPYBLZBs