I know we can’t do it in a “pixel-perfect” way yet, but the step Karpathy is pointing toward takes us to a place where what we call “knowledge” needs to be decomposed and collectively maintained independently of its presentation. I think it’s possible. The wiki structure was the first step toward this.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
hangi damardan kan alması gerektiğini gösterdiğim halde inadına başka yerden alan hemşire, sana da selam olsun kolum mosmor. dediğim damarda aynı kan akmıyordu sanki ucube oe
IK’ya ‘biraz da senden bahsedelim’ dedim ve sonra 3 saat sohbet edip ertesi günlerde buluşmuştuk. Profesyonel olmayacağı için işe alım sürecine devam etmedik.
İş görüşmelerinde yaşadığınız en garip olay neydi?
En garip olayı seçtim ben. Az önce yapay zeka tarafından telefonla arandım djfjsjakak merhaba ben yapay zeka asistanı … şimdi sana sorular soracağım önce adını teyit edelim şeklinde başladı konuşmaya
Insider iş görüşmelerinde ''fazla mesai yapmaya okey misin biz çok çalışırız şirket kültürü gereği ona göre'' gibi şeyler söyleyip sizi tartar. Peki fazla mesai ücreti veriliyor mu? HAYIR. İş kanununa aykırı iş yapıyorlar yani ve fazla mesai yapmazsan kovuluyorsun.
You can build this for your own product — for free.
Better i18n's Content CMS lets you create a multilingual help center, blog, or knowledge base without paying for Intercom ($85/seat) or Zendesk ($115/seat).
Write once, AI translates to all your languages, publish to CDN.
Get started → https://t.co/PwfcZNMgHe
yavaş yavaş beta sürecinden çıkıyoruz. 🥂
önce "destek" ol kısmının düzenlenmesi şimdi ise detaylı monetization. işlemlerin hepsi stripe üzerinden oldugu icin try için ayrı bir şey oluşturmak yerine yine dolar listeletiyorum ancak türkiyeye özel ayrı paketler oluşturdum. %70 indirimli olarak listeletiyorum. şuan 1600+ kullanıcımız türk olsa dahi yavaştan reddite ve diger grow sayfalarina girerek global olarak büyütmeyi es zamanli olarak yurutecegim.
kalitemizden ödün vermeden ama muzipliğimizi de bırakmadan header'da kelime oyunu yaptık yine : )
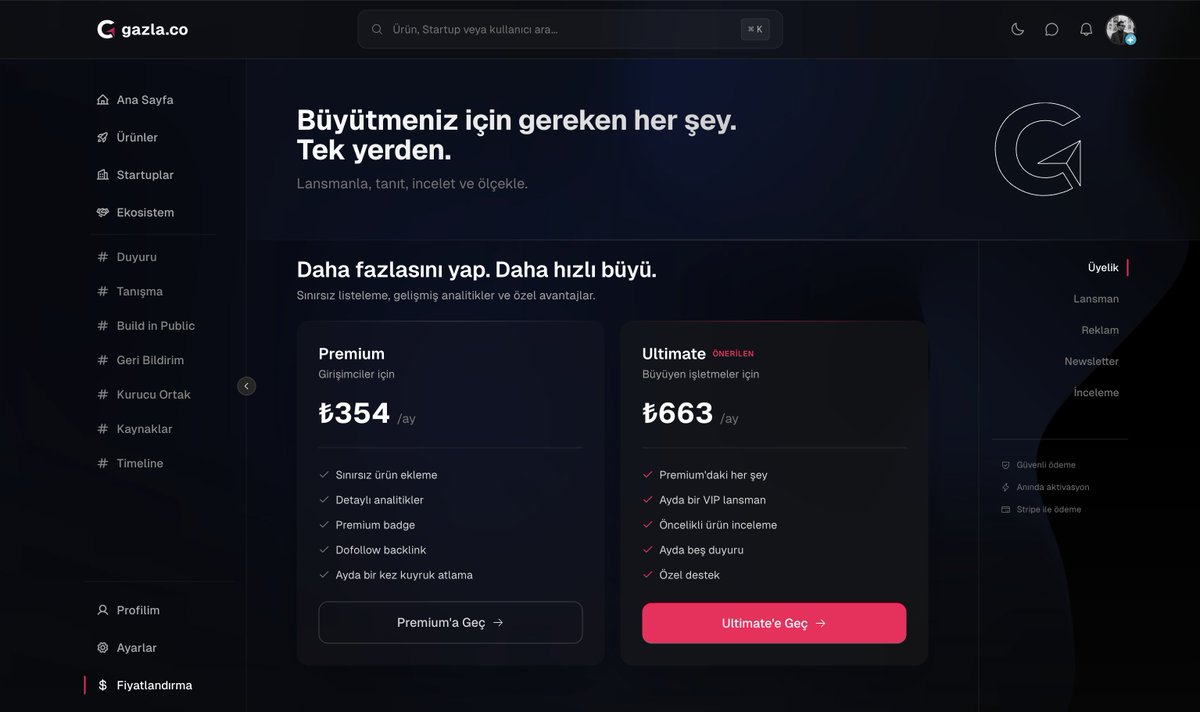
fiyatlandırma sayfamız detayli:
https://t.co/2dPHp5bS26
Ciddi ciddi bir psikolog böyle düşünüp bunu bir de açıkça bir yerde paylaşıyor eğitim sisteminin geldiği nokta budur. Sanki her gün avlanıyo çok yoruldu da iki işin ucundan tutsa beli kopacak amk evladının
Psikolog Fatih Civelekoglu:
'''Bulaşığı sen yıka, yemeği ben yapayım. Evi sen süpür, camları ben sileyim.'
Bunu kabul etmiyoruz.
Bunları yapan erkek erilligi kaybeder, testosteronu düşer.
Koca olma yeterliliğini yitirip maskara olur."
ben: buraya çok güvenmiyorum ama canlıya alacağım. müşteri zaten test eder, hata döner mutlaka. şu an önceliklendirmeyeceğim.
müşteri: burayı zaten test etmişlerdir, kontrol etmeme gerek yok