The funniest maths in modern environmentalism.
One almond requires 12 litres of irrigated water to produce. Peer-reviewed, ScienceDirect, 2017. A glass of almond milk contains roughly 50 of them. 600 litres of water before the carton is filled.
The water comes from the San Joaquin Valley in California, which sits over one of the most over-extracted aquifers on earth. The valley floor has subsided by up to nine metres in places due to groundwater depletion. The carton is then refrigerated, sailed across the Atlantic, refrigerated again, lorried to a Manchester Tesco, and bought by someone who is concerned about the environmental impact of dairy.
Meanwhile, in Cheshire.
A British dairy cow drinks roughly 70 to 100 litres of water a day and produces around 28 litres of milk. That's about 3.5 litres of water per litre of milk. The water is rainwater that fell on her field or came from a local stream fed by the same rainwater. The rain was going to fall on the field whether the cow stood in it or not. 80% of her moisture intake comes from the grass itself, which is also rain.
She converts the grass, free of charge, into a litre of milk containing seven times the protein and four times the calcium of almond milk, and shipped roughly 18 miles to the same Tesco.
To recap.
600 litres of stolen aquifer, flown halfway round the world for nutritionally worthless beige water.
Or 3.5 litres of rain that was already falling, converted by an animal you can pet, into actual food.
The shopper picks the almond.
She has been told this is the ethical position.
The aquifer would like a word.
DRUMMONDVILLE - NUL BESOIN DE LA CHINE OU DE TRUMP POUR DÉTRUIRE NOS ENTREPRISES
Résumé de l'affaire : NN Remorques vs Drummondville
L'entreprise NN Remorques, un fleuron familial de Drummondville spécialisé dans la fabrication de remorques en aluminium, est actuellement dans une impasse critique avec la Ville.
Le Projet :
L'entreprise, en pleine croissance, prévoyait un investissement de 20 millions de dollars pour construire une nouvelle usine moderne, créant de nombreux emplois et consolidant sa position de leader.
Le Conflit :
La Ville de Drummondville a entamé des procédures d'expropriation sur les terrains de l'entreprise pour un projet de développement municipal (parc industriel ou infrastructure).
L'Impact :
Cette décision bloque non seulement l'expansion de 20 M$, mais menace la survie même de l'entreprise sur le territoire drummondvillois.
Les propriétaires dénoncent une déconnexion totale des élus, un manque de vision économique et un mépris pour une famille qui investit ici depuis des décennies.
Le Cri du cœur :
L'entreprise se dit « étouffée » par la bureaucratie et les décisions unilatérales de la Ville, affirmant que l'administration municipale devient le principal obstacle à leur succès, plutôt qu'un partenaire.
On se gargarise de mots au Québec. « Innovation », « Achat local », « Soutien à nos entrepreneurs ».
On fait des grandes conférences, on coupe des rubans, on se tape dans le dos.
Mais grattez un peu le vernis, pis vous allez voir la machine à broyer les rêves en pleine action.
L’histoire de NN Remorques à Drummondville, c’est pas juste une chicane de terrain.
C’est le symptôme d’un cancer qui bouffe le Québec de l’intérieur : le mépris bureaucratique.
T’as une famille, des gens de chez nous, qui décident de risquer leur peau, leur capital, leur santé pour bâtir de quoi.
Vingt millions de dollars.
C’est pas des peanuts, c’est du sérieux. Ça veut dire des jobs, de la richesse, du rayonnement.
Et qu’est-ce qu’ils reçoivent en retour ?
Une lettre d’expropriation.
Un coup de pelle derrière la tête de la part de ceux-là mêmes qui sont supposés leur dérouler le tapis rouge.
C’est rendu qu'au Québec, le plus gros compétiteur d’un entrepreneur, c’est pas la Chine ou les États-Unis. C’est l’Hôtel de Ville.
C’est le fonctionnaire qui voit un terrain comme une case sur un plan d’urbanisme sans comprendre qu’il y a du sang, de la sueur et une vision derrière chaque pied carré.
On est en train de dire à nos créateurs de richesse : « Allez-vous-en. Allez investir ailleurs, là où on ne vous traitera pas comme des obstacles. »
Drummondville agit comme un prédateur sur ses propres citoyens.
C’est d’une courte vue effrayante.
On sacrifie le futur industriel pour des projets de bureau de coin de table.
On n’a même plus besoin d’ennemis extérieurs pour couler notre économie.
Nos municipalités s’en occupent très bien toutes seules.
On étouffe, on exproprie, on décourage. Et après, on va se demander pourquoi nos jeunes partent et pourquoi notre économie stagne ?
Si on n'est pas foutus de protéger et de respecter ceux qui ont le courage de bâtir, on mérite de finir comme un grand parc vide, géré par des bureaucrates qui n'ont jamais vendu un clou de leur vie.
Laissez NN Remorques bâtir, ou assumez que vous êtes les fossoyeurs de notre propre prospérité.
@E_Duhaime
https://t.co/i86uNNGwTi
Regarding the OpenAI case, the judge & jury never actually ruled on the merits of the case, just on a calendar technicality.
There is no question to anyone following the case in detail that Altman & Brockman did in fact enrich themselves by stealing a charity. The only question is WHEN they did it!
I will be filing an appeal with the Ninth Circuit, because creating a precedent to loot charities is incredibly destructive to charitable giving in America.
OpenAI was founded to benefit all of humanity.
🌟Introducing🎻Violin — an Open-source Video Translation Skill.
📹Video is the dominant medium on the internet, yet most high-quality content (lecture, talk, podcast) is locked behind a single language, leaving global audiences behind.
So we built Violin: a video skill that combines speech recognition, LLM translation, and speech synthesis into one seamless pipeline.
🌐 Demo: https://t.co/QFLuz4ANoE
📝 Blog: https://t.co/7FLQYQnCkn
🔗 GitHub: https://t.co/Allp6RZV4V
✨Key Features:
🎙️High-quality multilingual ASR & Translation & TTS.
🗣️Personalize translation & voice (turn an academic talk into something children can follow).
💬Chat with the video — ask any questions grounded in the video.
🧩Support Web app, CLI, and Agent skill
🍃Fully open-source under MIT.
❤️Built with the wonderful @ShangZhu18 and advised by @james_y_zou !
All features powered by @togethercompute .
Try it and let us know what you think! 🎻
Le Québec a perdu 100 000 emplois depuis le début de l’année, et pas que dans le secteur de la fabrication. «C’est inquiétant, ça s’élargit au delà des secteurs touchés par les tarifs» dit l’économiste en chef de Desjardins Jimmy Jean à #Zoneéconomie
@elonmusk Community note: 1) he was supported by the right wind to fight against communism. 2) he fight against immigration as must of the right wind.
@grok can you validate it?
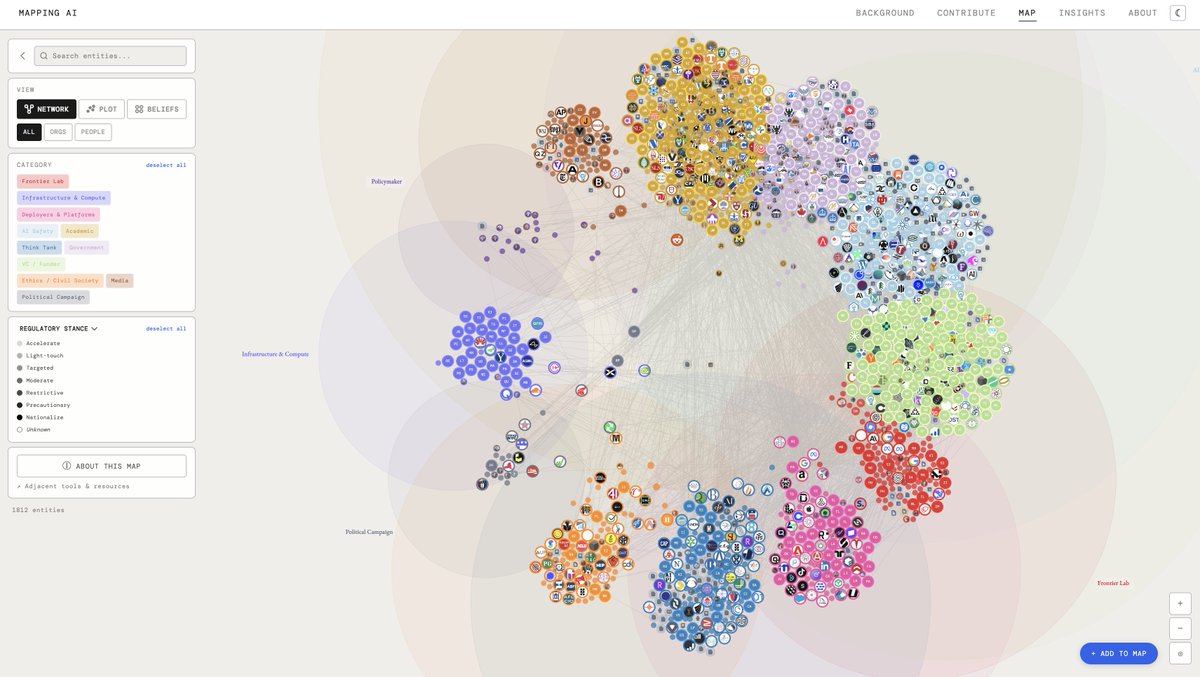
Who actually shapes AI policy in the U.S.?
We mapped 1,812 entities: 745 people, 918 organizations, 2,925 relationships. Frontier Labs, AI Safety orgs, Think Tanks, Government, VCs, and more.
https://t.co/6RDB1R0qNd
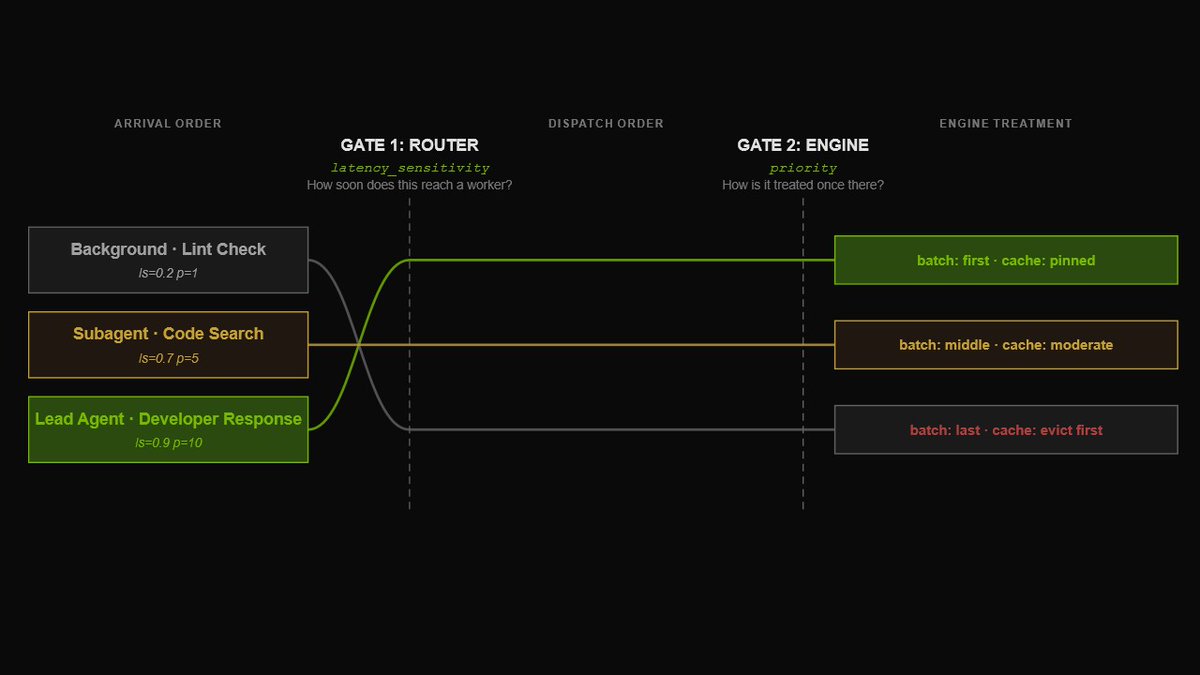
Traditional inference wasn’t built for agentic coding.
Agentic tools make hundreds of API calls per coding session, often with recomputed context, creating bottlenecks that drive up cost per token.
NVIDIA Dynamo rebuilds the stack for agents with:
→ KV-aware routing
→ Agent-aware scheduling
→ Multi-tier caching
→ Unified orchestration
The result: higher cache hit rates, lower latency, and up to 7× more throughput: https://t.co/E9tRgiLmar
Here are the 3 Core Pillars of Every AI Agent's Context
Here's why MCP, RAG and Skills are now unavoidable...
Before we dive in, here's why all 3 exist in the first place:
Every AI Agent struggles with 3 core problems:
- Connecting to external tools requires writing custom API code every time
- Answering accurately from knowledge it was never trained on
- Repeating the same instructions in prompts; wasting tokens on every single call
MCP, RAG, and Skills were each built to solve exactly one of these problems.
📌 1\ MCP (Model Context Protocol)
MCP eliminates the need to write custom API integration code every time your agent needs to connect to an external tool.
How it works:
- User sends a query → MCP Client selects the right server
- LLM processes the request and routes it to the MCP Server
- Server (Slack, Qdrant, Brave Search) responds with the relevant data
- Final output is returned back to the user
Key insight: Without MCP, every new tool connection means new custom code. With MCP, your agent plugs into any server through one standardized protocol.
Use when: You want your agent to access external tools and services without rebuilding integrations from scratch each time.
📌 2\ RAG (Retrieval Augmented Generation)
RAG gives your agent memory-enabled retrieval, so it reasons over knowledge it was never trained on, instead of hallucinating answers.
How it works:
- Data sources are chunked → converted into embeddings
- Stored as dense vectors inside a Vector DB
- User query triggers a search → most relevant chunks are retrieved
- Retrieved info + query + system prompt → fed into the LLM → Output
Key insight: Without RAG, agents confidently make things up. With RAG, they retrieve first, then reason.
Use when: You want your agent to reason over large, dynamic knowledge bases with accuracy and context.
📌 3\ Agent Skills
Skills stop your agent from wasting tokens by repeating the same instructions in every single prompt.
How it works:
- User query → LLM sends a Skill Request to the Skill Manager
- Skill Manager retrieves the right skill using stored prompts and actions
- Tools like Git, Docker, Python Interpreter, and Shell are triggered
- Skill data flows back to the LLM → Final Output is delivered
Key insight: Without Skills, you bloat every prompt with repeated instructions. With Skills, your agent loads only what it needs, exactly when it needs it.
Use when: You want reusable, token-efficient actions your agent can execute without being re-instructed every time.
Save 💾 ➞ React 👍 ➞ Share ♻️
Cc : Rakesh Gohel
1/ Quantization
Running FP16 or BF16 in production? You're leaving 50-75% performance on the table.
FP8 on H100 gets ~2x throughput with 99%+ accuracy. INT4 via AWQ or GPTQ gives 3-4x memory reduction.
Red Hat AI has 600+ pre-quantized models ready to drop in: https://t.co/9CT0WrxtqW
Red Hat AI Factory with NVIDIA is a joint platform for production AI at scale.
NVIDIA AI Enterprise + Red Hat AI Enterprise, SELinux and FIPS compliance built in. Runs on Blackwell today, Vera Rubin when it ships.
Taylor Smith walks through it in 3 mins. https://t.co/VlSZ17puXo
Better model outputs. Smaller models. More reliable agents. All without retraining.
That's inference time scaling: more compute at inference, not training. Works with any OpenAI-compatible model.
Watch the demo below and try it yourself here: https://t.co/Ov8hFyK1N3
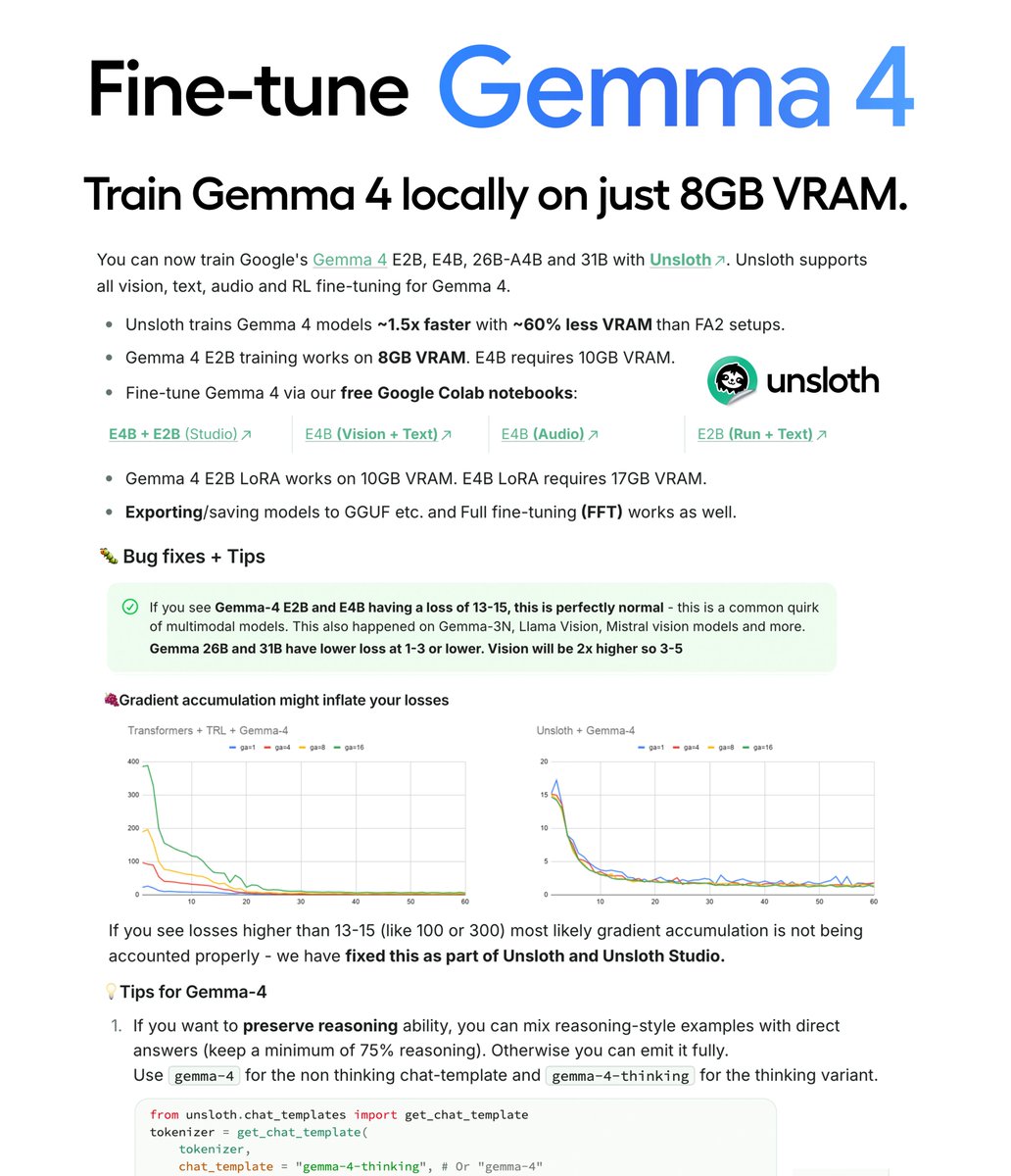
You can now fine-tune Gemma 4 with our free notebooks! 🔥
You just need 8GB VRAM to train Gemma 4 locally!
Unsloth trains Gemma4 1.5x faster with 50% less VRAM.
GitHub: https://t.co/aZWYAtakBP
Guide: https://t.co/NBwKoFH2lp
Gemma-4-E4B Colab: https://t.co/JjpCQgWEpL
What if you could build a full Vision AI pipeline… just by describing it?
In our upcoming livestream, we’re showing how NVIDIA DeepStream is transforming how developers build and deploy vision AI with coding agents like Claude Code or Cursor —cutting development cycles from weeks to hours.
🗓️ April 16, 9am PT
Register 👉 https://t.co/YM9lKpFfRi
A peanut-sized Chinese model just dethroned Gemini at reading documents.
GLM-OCR is a 0.9B parameter vision-language model.
It scores 94.62 on OmniDocBench V1.5, ranking #1 overall.
For context, it outperforms models 100x its size. 100% open-source.
It works in two stages.
1. A layout engine detects every region in a document.
2. Each region gets read in parallel.
The model predicts multiple tokens per step instead of one.
That's what makes it so fast at small size.
It handles things most OCR tools struggle with:
> Complex tables and nested layouts
> Handwritten text and stamps
> Math formulas and code blocks
> Mixed image-and-text documents
You can run it locally through Ollama.
It fits on edge devices with limited compute.
Every expensive OCR API just got a free competitor.
🚨 Breaking: Alibaba just killed the browser automation stack.
**page-agent.js** — a GUI agent that lives directly inside your webpage. No Selenium. No Puppeteer. No Chrome extension. No Python backend. Just one script tag.
It reads your DOM as text (no screenshots, no multimodal BS), brings your own LLM, and executes natural language commands like "fill out this form" or "click login" — right inside the page.
The use cases are genuinely insane:
→ Ship an AI copilot in your SaaS in literally lines of code
→ Turn 20-click ERP/CRM workflows into one sentence
→ Make any legacy web app accessible via voice or natural language
12k stars. MIT licensed. Built on top of browser-use internals — but without any of the setup overhead.
This is what "AI-native UX" actually looks like in practice
Link in comments👇
Gemma 4 31B, quantized and evaluated.
Instruction following evals are live on our NVFP4 and FP8-block model cards. Results look great. Reasoning and vision evals coming later this week.
NVFP4: https://t.co/W62l0l4WbI
FP8: https://t.co/SwTGu8vHJ3
New paper from our team is now on arxiv. One of the techniques we use for Nemotron-3 post-training.
"PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost"
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.