Our paper PERK is accepted to #ICLR2026 🎉
Long-context reasoning is one of the most critical skills a frontier model must master. The standard approach: feed the context into the model’s attention and hope the model figures out how to reason over its content.
We show that Test-Time Learning (TTL) is a more effective way to process long context than standard long-range attention.
Instead of just reading the context, the model should learn it at test time, by internalizing it into LoRAs via next-token prediction.
Come find us at our poster — Pavilion 3 #509, Thu, Apr 23 • 10:30 AM – 1:00 PM — if you want to dig in further.
Excited to be in Rio for #ICLR2026 🇧🇷
I'll be presenting our work, Mixture of Cognitive Reasoners (aka MiCRo), on Friday at Pavilion 3, 10:30 AM (#1610). Come say hi :D
Happy to chat about NeuroAI, representational & cultural alignment, and/or test-time learning 🧠
News at Rio de Janeiro!
Our paper “AbstRaL: Augmenting LLMs’ Reasoning by Reinforcing Abstract Thinking” will be presented at #ICLR2026 soon!
Welcome to our poster session -->
Time: Friday, April 24, 10:30am – 1:00pm (Rio local time) Room: Pavilion 4, P4-#4615
Our paper PERK is accepted to #ICLR2026 🎉
Long-context reasoning is one of the most critical skills a frontier model must master. The standard approach: feed the context into the model’s attention and hope the model figures out how to reason over its content.
We show that Test-Time Learning (TTL) is a more effective way to process long context than standard long-range attention.
Instead of just reading the context, the model should learn it at test time, by internalizing it into LoRAs via next-token prediction.
Come find us at our poster — Pavilion 3 #509, Thu, Apr 23 • 10:30 AM – 1:00 PM — if you want to dig in further.
What does TTL with PERK actually get you?
1. Consistently beats attention across a wide range of reasoning tasks.
2. Much more robust to context-length variation at test time.
3. Much more robust to relevant information positions.
4. Scales more efficiently than attention at inference.
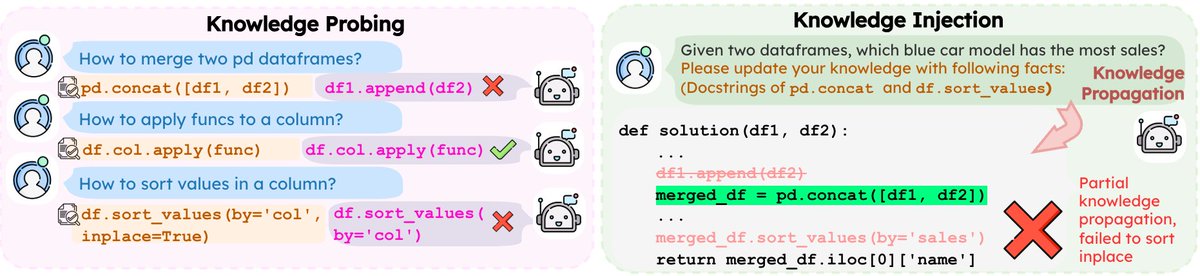
Can LLMs truly reason with knowledge that conflicts with what they already believe?
Our paper TRACK, accepted as a Virtual Oral @eaclmeeting#EACL2026, shows the answer is often no. Even when you hand them the correct facts.
Find out how we did this ⬇️
Love seeing more work on test-time learning for long context! We explored a similar direction in PERK, encoding long contexts into LoRA parameters via test-time learning. We found similar strong gains in long-context reasoning, especially better performance on length generalization (train on 8K and extrapolate to 128K).
https://t.co/TdraAxzWG5
1/ 🌍 How does mixing data from hundreds of languages affect LLM training?
In our new paper "Revisiting Multilingual Data Mixtures in Language Model Pretraining" we revisit core assumptions about multilinguality using 1.1B-3B models trained on up to 400 languages.
🧵👇
We're excited to welcome 28 new AI2050 Fellows! This 4th cohort of researchers are pursuing projects that include building AI scientists, designing trustworthy models, and improving biological and medical research, among other areas. https://t.co/8oY7xdhxvF
🚀 Excited to share a major update to our “Mixture of Cognitive Reasoners” (MiCRo) paper!
We ask: What benefits can we unlock by designing language models whose inner structure mirrors the brain’s functional specialization?
More below 🧠👇
https://t.co/LVBLQ9yFlA
1/🚨 New preprint
How do #LLMs’ inner features change as they train? Using #crosscoders + a new causal metric, we map when features appear, strengthen, or fade across checkpoints—opening a new lens on training dynamics beyond loss curves & benchmarks.
#interpretability
In collaboration with my wonderful co-authors: @agromanou, @gail_w , & @ABosselut!
Links 🔗:
Project Page: https://t.co/Hf4le4Ad7i
Paper: https://t.co/tFC5HmhmDY
Code: https://t.co/ET6uxuwEnY
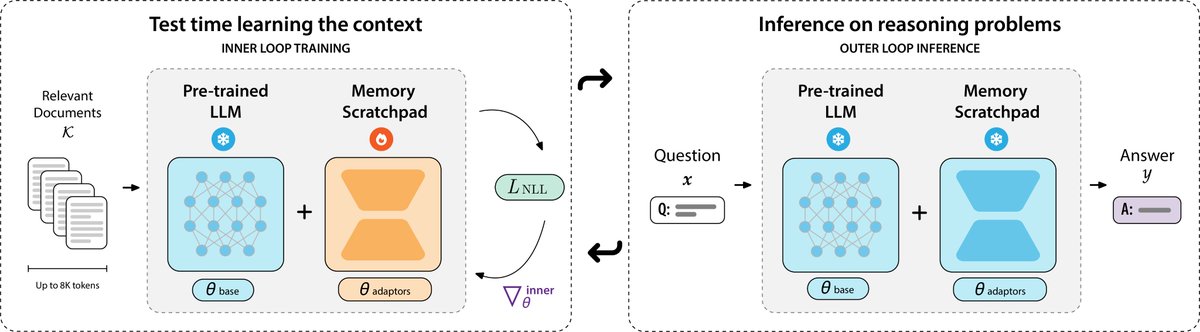
🗒️Can we meta-learn test-time learning to solve long-context reasoning?
Our latest work, PERK, learns to encode long contexts through gradient updates to a memory scratchpad at test time, achieving long-context reasoning robust to complexity and length extrapolation while scaling efficiently at inference.
PERK can be applied to existing pretrained language models without requiring architectural or parameter modifications to the base model.
#LLM #LongContext
Find out how PERK operates and performs 👇
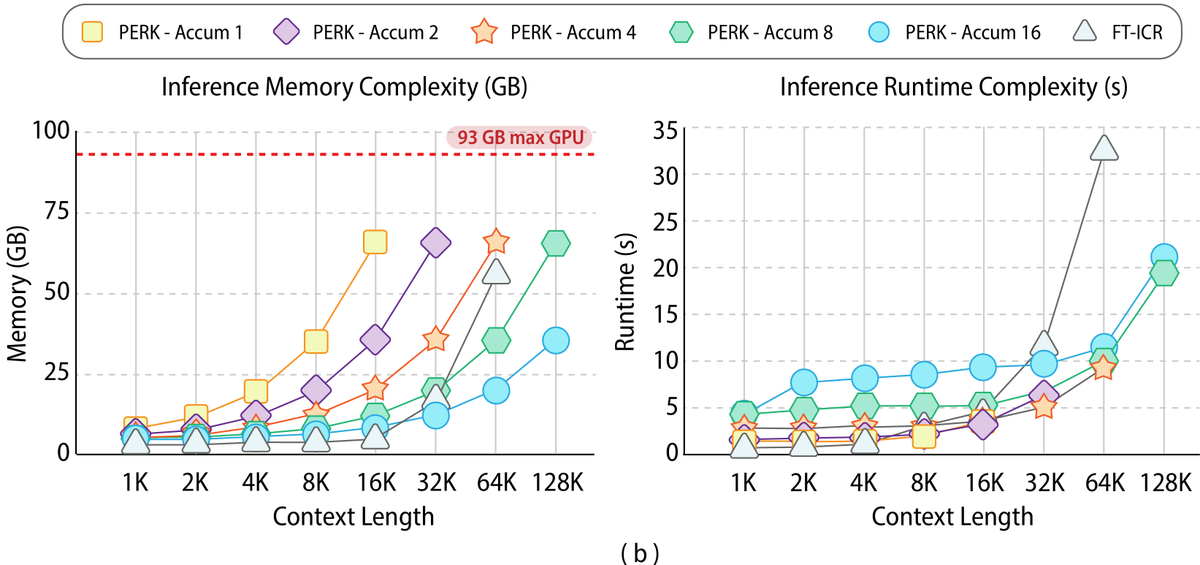
💻Finally, PERK demonstrates more efficient scaling in both memory and runtime, particularly for extremely long sequences. While in-context reasoning is initially more efficient, its memory and runtime grow rapidly, leading to OOM errors at a context length of 128K. In contrast, PERK can manage long sequences through gradient accumulation, which, while increasing runtime, reduces the memory footprint.