I created an AI artist and kids channel — been writing the songs by hand and using tools to produce the music and videos - mostly to entertain my kid / create some legacy and story content for him.
Check out the kids channel (I add videos almost daily)
https://t.co/2VfeJaXPO5
I created a full on ai artist - https://t.co/u1YfvEZ4iT
I write the songs to tell my story for my kid when he’s older (and entertain myself) using ai to produce the tunes
Spelke's core knowledge framework (objects, agents, number, geometry) is a four-part specification of what cognition has before it starts learning.
Specific ML instantiations now exist for each:
Objects: slot attention (Locatello et al. 2020), PLATO (Piloto et al. 2022) Number: approximate number system models Agents: naïve utility calculus (Jara-Ettinger et al. 2016) Geometry: structured spatial representations
Developmental psych almost reads like a requirements doc for AGI priors.
The memory wall, updated numbers:
H100 FP8 ridge: 591 FLOPs/byte H200 (same die, HBM3e): 412 ← NVIDIA shipped a memory-only refresh B200 FP8: 563 B200 FP4: 1,125 B300 NVFP4: ~1,875 Rubin Ultra (2026): ~7,700
FP4 and NVFP4 are not just precision tricks. They're how you use the tensor cores at all when the compute:bandwidth ratio is this wide.
Zoology paper (Arora et al. 2023) swept 4 learning rates per architecture to compare sequence mixers on MQAR. Mamba and Hyena appeared to fail at long sequences.
Okpekpe & Orvieto (2025, arXiv 2508.19029) reran with a 10+ point grid, 3,000+ runs, ~20,000 GPU-hours. Mamba and Hyena have extremely narrow LR windows, effectively binary performance at typical sweep resolutions. With a denser grid, Mamba solves MQAR at sequence lengths well beyond hidden dimension.
Architecture capability claims are optimization-confounded. Finer grids or report "capability under tuning budget B" not "capability."
Optimization is the part of ML people assume is solved. It isn't.
Three results from the last two decades that actually decide what your model learns:
Convexity is a phase transition. One negative eigenvalue in a QP makes it NP-hard (Pardalos-Vavasis 1991).
The optimizer IS the regularizer. GD on separable logistic regression converges in direction to the max-margin SVM solution (Soudry et al. 2018). Same loss, different interpolator, different generalization.
SGD won because of its noise, not despite it. Robbins-Monro 1951 is still the theoretical backbone of every large-scale trainer in production.
Yamins & DiCarlo (2014): deep nets trained for object recognition predict V4 and IT neural responses, with no explicit constraint to match brain data.
Schrimpf et al. (2021): transformer LMs predict neural responses in language areas.
But Feather et al. (2023): model metamers (stimuli producing identical ANN representations) often look drastically different to humans. And biological vision leans on recurrent processing that feedforward CNNs don't have.
Convergence is real. Equivalence is premature.
A lot of AI still defaults to dense measurement. Biology doesn't.
Compressed sensing (Candes, Romberg, Tao 2006) proved sparse signals can be recovered from far fewer samples than Nyquist says you need. Olshausen and Field (1996) showed the visual cortex already works this way.
Before reaching for more parameters, more data, more compute... look for sparsity in your representations. Evolved systems figured this out a long time ago.
A useful frame for evaluating HDC pitches: ask what's being factored, not what's being bound.
Encoding in hyperdimensional computing is polynomial. Decoding (recovering the original components from a composed vector) is combinatorially hard. Search space is N^F for F factors from a codebook of size N.
HDC is great for "compose and check." It's structurally hard for "decompose and reason." Most enterprise pitches are the second kind.
Anthropic's sparse autoencoders on transformer activations: ~70% of extracted features are judged genuinely interpretable by human evaluators.
Features for Arabic script. DNA sequences. Base64. Abstract concepts that are invisible in the raw neuron basis.
Dictionary learning from the 1990s is the reason we can now read LLM internals.
Cerebras WSE-3: one processor etched on a single 46,225mm² wafer.
44GB on-chip SRAM. 21 PB/s memory bandwidth. Roughly 7,000x an H100.
For workloads that fit in 44GB, the memory wall vanishes.
The most radical response to the memory wall is also the simplest. Make the chip enormous.
Information is physical. That's the most important sentence Rolf Landauer ever wrote, and it became one of the most experimentally robust results in 20th century physics.
The principle: erasing one bit of information must dissipate at least kT ln 2 ≈ 2.87 × 10⁻²¹ joules of heat. It's not an engineering limit. It comes from statistical mechanics; phase-space compression has to be paid for somewhere. First articulated in 1961, experimentally confirmed in 2012 with optical tweezers and silica beads, and now extended through superconducting circuits, trapped ions, nanomagnets, single-electron Szilard engines, and (in 2025) quantum many-body systems with ultracold Bose gases.
The gap between this theoretical floor and modern silicon is vast and shrinking. A 5nm CMOS transistor switches at ~1,000× the Landauer limit. An H100 burns ~10⁸× the limit per FLOP. A ChatGPT query is roughly 10²³ times the Landauer cost of erasing a single bit.
That gap is the budget for the next 50 years of computing efficiency improvements. Ho et al. (2023) estimate ~200× more headroom in CMOS before fundamental physics intervenes: roughly 7–8 doublings, or 15–20 years at current Koomey-law rates. After that, the only known escape is reversible computing.
Rate-distortion theory (Shannon 1959) unifies modern representation learning. VAE ELBO = −D−R. β-VAE traces the R-D curve. Information Bottleneck is supervised R-D (Tishby et al. 1999). Cross-entropy LM loss is lossless-limit R-D via arithmetic coding (Delétang et al. ICLR 2024). Neural codecs optimize R + λD directly (DCVC-RT beats VVC). Every knob you tune is picking an operating point on some R-D curve. The master control panel for representation learning is 66 years old and most engineers still haven't learned to use it.
G-Net (Aghasi et al., NeurIPS 2025): proves every floating-point neural network has a randomized binary embedding with formal accuracy guarantees, converging to the reference network as hypervector dimension N grows. Empirical: 81%+ on CIFAR-10, nearly 30 points above prior HDC. The "accuracy collapse" wasn't an architectural limit, it was a dimensionality budget problem. HDC isn't a separate paradigm. It's binary compression of neural computation.
The math is unambiguous: async beats sync on graph-structured updates. Hopfield 1982 (energy descent), Elidan 2006 (residual BP), Gonzalez 2011 (chromatic Gibbs preserves correctness), Faber & Wattenhofer 2022 (async GNNs strictly more expressive than 1-WL). Sync wins anyway because GPUs make SpMM cheap. Cleanest single example of the Hardware Lottery in a specific subfield.
Selective absorption is the pattern: deep learning doesn't kill alternatives, it strips out the useful ideas and reimplements them inside the GPU/PyTorch/transformer stack. Capsule networks → soft routing in ViTs. Bayesian uncertainty → deep ensembles. State-space efficiency → hybrid SSM-attention (Jamba, Nemotron-H, Qwen3-Next). Symbolic reasoning → tool-augmented LLMs. The useful ideas survive; the architectural commitments don't. Whether absorption is enough is the open question. LeCun raising $1.03B for AMI on the explicit thesis that "scaling LLMs is nonsense" suggests at least one well-funded researcher is betting it isn't.
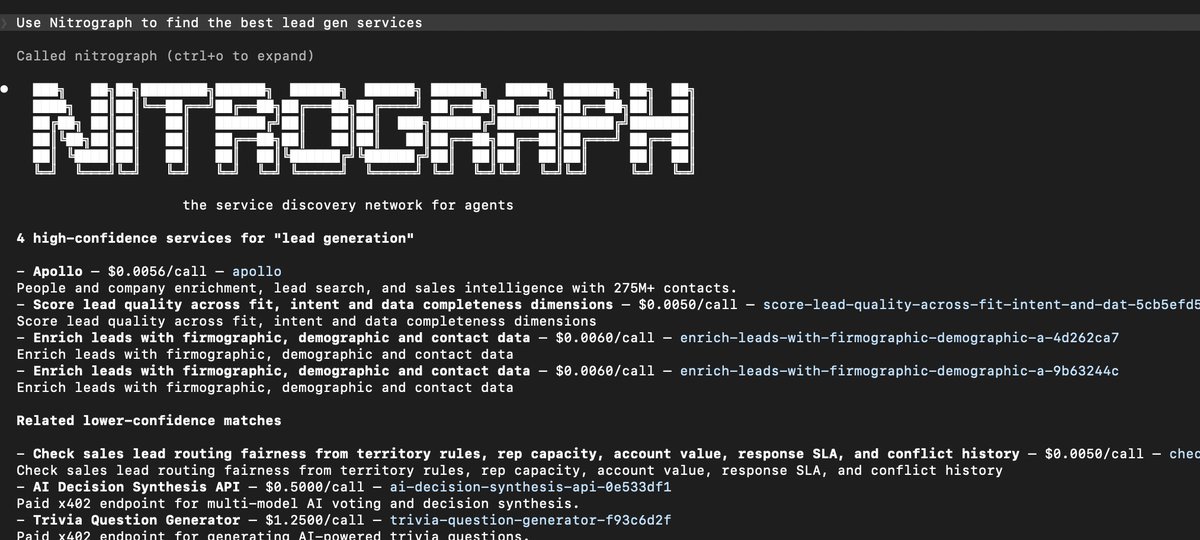
I live in my terminal all day running agents.
So I don’t want to browse API directories.
I want to tell my agent what I need and have it find the right service.
Here I asked it:
“Use Nitrograph to find the best lead gen services.”
Nitrograph returned high-confidence x402/MPP services directly in the CLI.
Graphcore IPU: 1,472 tiles, 900 MB on-chip SRAM, true MIMD, bulk synchronous parallel execution. Architecturally excellent for graphs and irregular workloads. 2022 revenue: £2.1 million against ~$682-767M raised. Sold to SoftBank 2024 for ~$500M. Best graph hardware, worst market timing. The cleanest example in modern AI hardware that "best for specific workloads" only matters when the market is growing toward those workloads, not away from them.
16 behavior-related dimensions explain half of variance in ~1M mouse cortex neurons (Manley et al., Neuron 2024). The brain compresses ~10⁹ bits/s of sensory input to ~10 bits/s of behavior (Zheng & Meister, Neuron 2024). Modern LLMs use ~22% of their nominal precision per parameter (Morris et al. 2025). Three different fields, three different methods, same answer: high-capacity systems use a tiny fraction of nominal capacity. That's not waste, that's what efficient learning looks like.